

05 | ArrayList还是LinkedList?使用不当性能差千倍

该思维导图由 AI 生成,仅供参考
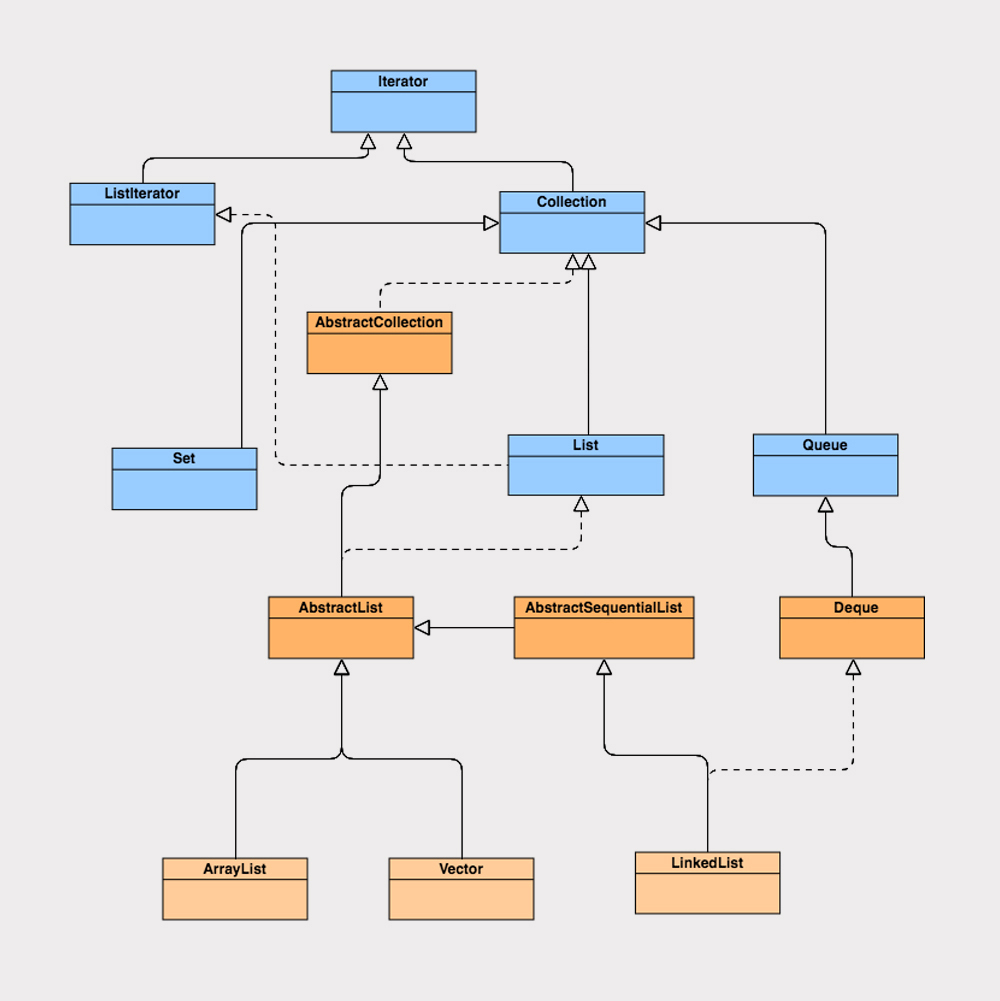
初识 List 接口
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

Java中的ArrayList和LinkedList是常用的集合类型,分别基于数组和双向链表实现。本文通过深入分析源码,揭示了它们的内部机制和性能特点。首先介绍了ArrayList的实现原理,包括新增和删除元素的方法,以及遍历元素的效率。重点解答了关于ArrayList序列化和新增元素效率的疑问,揭示了其动态扩容和数组复制的内部机制。其次,详细介绍了LinkedList的实现原理,包括基于双向链表的数据结构和在JDK1.7之后的优化。通过对比ArrayList和LinkedList的实现原理和性能特点,读者可以深入了解它们的内部机制和使用场景。文章通过问题引入和源码分析的方式,生动地展现了ArrayList和LinkedList的内部实现和性能差异,为读者提供了深入了解这两种集合类型的机会。通过测试验证了它们在新增、删除和遍历元素时的性能表现,帮助读者更好地选择适合的集合类型。文章还提出了思考题,引发读者对ArrayList数组的删除操作进行思考。
《Java 性能调优实战》,新⼈⾸单¥59

全部留言(77)
- 最新
- 精选
 Rain置顶老师,为什么第二种就会抛出`ConcurrentModificationException`异常呢,我觉得第一种迭代器会抛这个异常啊
Rain置顶老师,为什么第二种就会抛出`ConcurrentModificationException`异常呢,我觉得第一种迭代器会抛这个异常啊作者回复: for(:)循环[这里指的不是for(;;)]是一个语法糖,这里会被解释为迭代器,在使用迭代器遍历时,ArrayList内部创建了一个内部迭代器iterator,在使用next()方法来取下一个元素时,会使用ArrayList里保存的一个用来记录List修改次数的变量modCount,与iterator保存了一个expectedModCount来表示期望的修改次数进行比较,如果不相等则会抛出异常; 而在在foreach循环中调用list中的remove()方法,会走到fastRemove()方法,该方法不是iterator中的方法,而是ArrayList中的方法,在该方法只做了modCount++,而没有同步到expectedModCount。 当再次遍历时,会先调用内部类iteator中的hasNext(),再调用next(),在调用next()方法时,会对modCount和expectedModCount进行比较,此时两者不一致,就抛出了ConcurrentModificationException异常。 所以关键是用ArrayList的remove还是iterator中的remove。
2019-05-3074 陆离置顶对于arraylist和linkedlist的性能以前一直都是人云亦云,大家都说是这样那就这样吧,我也从来没有自己去验证过,没想过因操作位置的不同差异还挺大。 当然这里面有一个前提,那就是arraylist的初始大小要足够大。 思考题是第一个是正确的,第二个虽然用的是foreach语法糖,遍历的时候用的也是迭代器遍历,但是在remove操作时使用的是原始数组list的remove,而不是迭代器的remove。 这样就会造成modCound != exceptedModeCount,进而抛出异常。
陆离置顶对于arraylist和linkedlist的性能以前一直都是人云亦云,大家都说是这样那就这样吧,我也从来没有自己去验证过,没想过因操作位置的不同差异还挺大。 当然这里面有一个前提,那就是arraylist的初始大小要足够大。 思考题是第一个是正确的,第二个虽然用的是foreach语法糖,遍历的时候用的也是迭代器遍历,但是在remove操作时使用的是原始数组list的remove,而不是迭代器的remove。 这样就会造成modCound != exceptedModeCount,进而抛出异常。作者回复: 陆离同学一直保持非常稳定的发挥,答案非常准确!
2019-05-30299 Loubobooo这一道我会。如果有看过阿里java规约就知道,在集合中进行remove操作时,不要在 foreach 循环里进行元素的 remove/add 操作。remove 元素请使用 Iterator方式,如果并发操作,需要对 Iterator 对象加锁。 <!-- 规约第七条 -->
Loubobooo这一道我会。如果有看过阿里java规约就知道,在集合中进行remove操作时,不要在 foreach 循环里进行元素的 remove/add 操作。remove 元素请使用 Iterator方式,如果并发操作,需要对 Iterator 对象加锁。 <!-- 规约第七条 -->作者回复: 👍
2019-06-01236- 脱缰的野马__老师您好,在我的认知里面,之所以数组遍历比链表要快,应该还有一个底层的原因,就是源于数组的实现是在内存当中是一块连续的内存空间,而链表所有元素可能分布在内存的不同位置,对于数组这种数据结构来说对CPU读是非常友好的,不管是CPU从内存读数据读到高速缓存还是线程从磁盘读数据到内存时,都不只是读取需要的那部分数据,而是读取相关联的某一块地址数据,这样的话对于在遍历数组的时候,在一定程度上提高了CPU高速缓存的命中率,减少了CPU访问内存的次数从而提高了效率,这是我结合计算机相关原理的角度考虑的一点。
作者回复: 赞,这是计算机底层访问数组和链表的实现原理,数组因为存储地址是连续的,所以在每次访问某个元素的时候,会将某一块连续地址的数据读取到CPU缓存中,这也是数组查询快于链表的关键。
2020-03-1530  皮皮第一种写法正确,第二种会报错,原因是上述两种写法都有用到list内部迭代器Iterator,而在迭代器内部有一个属性是exceptedmodcount,每次调用next和remove方法时会检查该值和list内部的modcount是否一致,不一致会报异常。问题中的第二种写法remove(e),会在每次调用时modcount++,虽然迭代器的remove方法也会调用list的这个remove(e)方法,但每次调用后还有一个exceptedmodcount=modcount操作,所以后续调用next时判断就不会报异常了。
皮皮第一种写法正确,第二种会报错,原因是上述两种写法都有用到list内部迭代器Iterator,而在迭代器内部有一个属性是exceptedmodcount,每次调用next和remove方法时会检查该值和list内部的modcount是否一致,不一致会报异常。问题中的第二种写法remove(e),会在每次调用时modcount++,虽然迭代器的remove方法也会调用list的这个remove(e)方法,但每次调用后还有一个exceptedmodcount=modcount操作,所以后续调用next时判断就不会报异常了。作者回复: 关键在用谁的remove方法。
2019-05-3018 TerryGoForIt老师您好,我比较好奇的是为什么 ArrayList 不像 HashMap 一样在扩容时需要一个负载因子呢?
TerryGoForIt老师您好,我比较好奇的是为什么 ArrayList 不像 HashMap 一样在扩容时需要一个负载因子呢?作者回复: HashMap有负载因子是既要考虑数组太短,因哈希冲突导致链表过长而导致查询性能下降,也考虑了数组过长,新增数据时性能下降。这个负载因子是综合了数组和链表两者的长度,不能太大也不能太小。而ArrayList不需要这种考虑。
2019-05-31215 JasonZlinkedlist使用iterator比普通for循环效率高,是由于遍历次数少,这是为什么?有什么文档可以参考么?
JasonZlinkedlist使用iterator比普通for循环效率高,是由于遍历次数少,这是为什么?有什么文档可以参考么?作者回复: 因为for循环需要遍历链表,每循环一次就需要遍历一次指定节点前的数据,源码如下: // 获取双向链表中指定位置的节点 private Entry<E> entry(int index) { if (index < 0 || index >= size) throw new IndexOutOfBoundsException("Index: "+index+ ", Size: "+size); Entry<E> e = header; // 获取index处的节点。 // 若index < 双向链表长度的1/2,则从前先后查找; // 否则,从后向前查找。 if (index < (size >> 1)) { for (int i = 0; i <= index; i++) e = e.next; } else { for (int i = size; i > index; i--) e = e.previous; } return e; } 而iterator在第一次拿到一个数据后,之后的循环中会使用Iterator中的next()方法采用的是顺序访问。
2019-06-09811 csyangchsh测试代码不严谨,建议使用JMH。
csyangchsh测试代码不严谨,建议使用JMH。作者回复: 厉害了,感谢建议。这里很多同学没有了解过JMH测试框架,所以没有使用。
2019-05-3010 建国老师,您好,linkList查找元素通过分前后半段,每次查找都要遍历半个list,怎么就知道元素是出于前半段还是后半段的呢?
建国老师,您好,linkList查找元素通过分前后半段,每次查找都要遍历半个list,怎么就知道元素是出于前半段还是后半段的呢?作者回复: 这个是随机的,因为分配的内存地址不是连续的。
2019-06-1046 yangmodCount属于ArrayList expectedModCount属于Iterator 增强for循环 本质是iterator遍历 iterator循环 iterator遍历 增强for循环 调用list.remove() 不会修改到iterator的expectedModCount, 从而导致 迭代器的expectedModCount != ArrayList的modCound; 迭代器会抛出 concurrentModifiedException 而iterator遍历 的时候 用iterator. remove(); modCount 会被同步到expectedModCount中去,ArrayList的modCount == Iterator的exceptedModCount,所以不会抛出异常。 老师对其他同学的评论以及我的理解就是这样。
yangmodCount属于ArrayList expectedModCount属于Iterator 增强for循环 本质是iterator遍历 iterator循环 iterator遍历 增强for循环 调用list.remove() 不会修改到iterator的expectedModCount, 从而导致 迭代器的expectedModCount != ArrayList的modCound; 迭代器会抛出 concurrentModifiedException 而iterator遍历 的时候 用iterator. remove(); modCount 会被同步到expectedModCount中去,ArrayList的modCount == Iterator的exceptedModCount,所以不会抛出异常。 老师对其他同学的评论以及我的理解就是这样。作者回复: 赞
2019-12-245

