

11|Agent 集成与数据流全景:记忆如何与 Agent 闭环联动?
Henry

你好,我是 Henry,欢迎来到 Memory 向量记忆系统的最后一课。
在前三课中,我们已经构建了完整的记忆基础设施:第 08 课我们理解了为什么 Agent 需要记忆,搭建了四层架构和三层类继承体系;第 09 课我们打开了混合搜索、MMR 去重、时间衰减三个核心算法的“黑盒”;第 10 课我们深入了 Embedding 多提供者体系和 SQLite 六张表的存储工程。
但此刻你可能会问:这些精心设计的基础设施,Agent 到底是怎么用起来的?对话中产生的新知识,又是如何自动沉淀为长期记忆的?
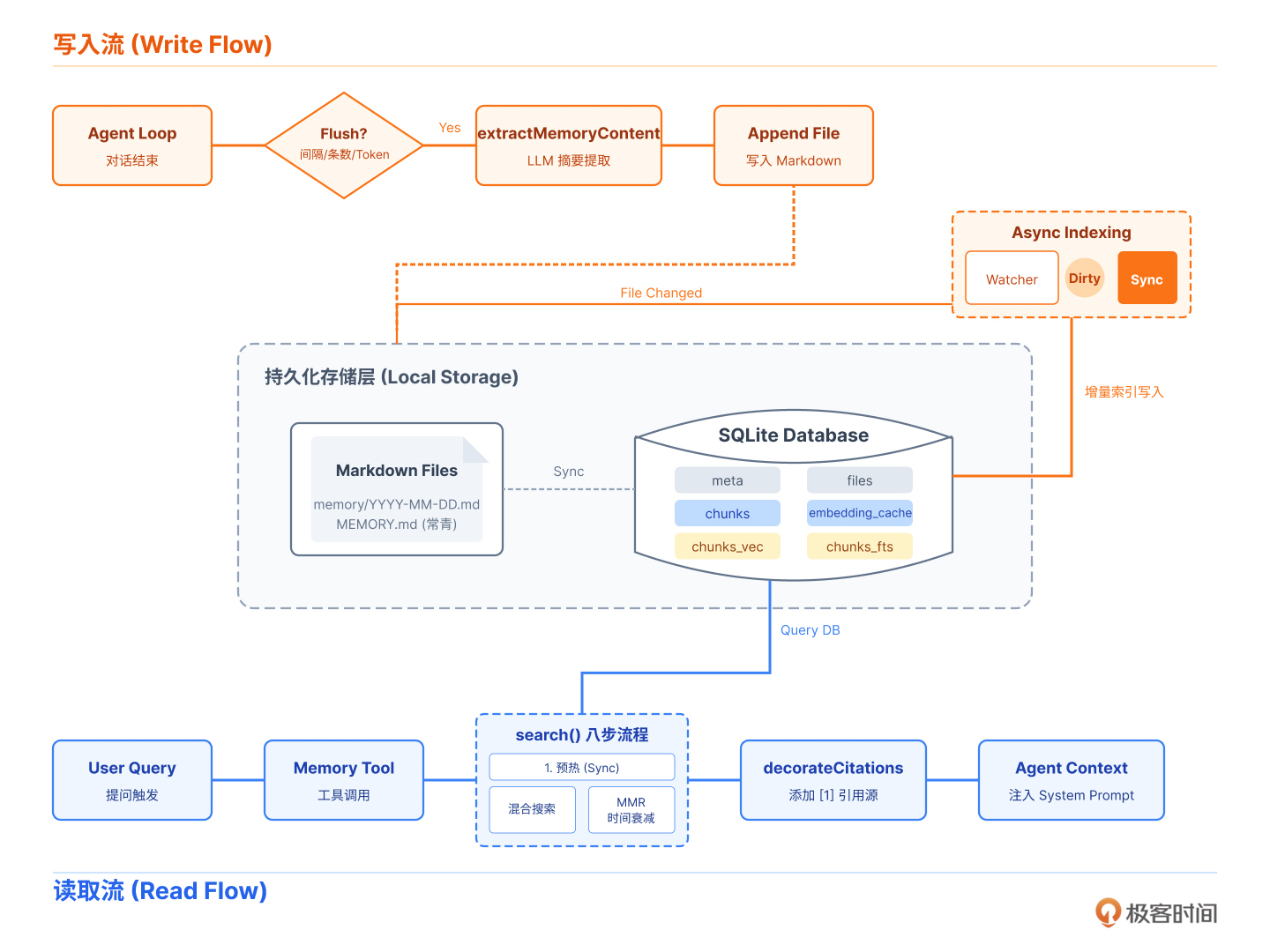
这就是本课要解决的核心问题——打通 Agent 与 Memory 的完整闭环。你将看到:
Memory 搜索如何被包装成 Agent 可调用的“工具”?
搜索结果如何附加引用标注,让 LLM 能够溯源?
系统如何在恰当时机静默触发记忆持久化?
写入流与读取流的完整链路是什么样的?
学完这节课,你将拥有一张“数据流全景图”,理解 OpenClaw 如何实现“检索 - 使用 - 记录 - 索引”的生命周期闭环。
Memory Tool 工具化集成
为什么需要工具化
在 Agent Loop 中,LLM 并不能直接调用 TypeScript 函数。它只能通过“工具调用”(Tool Call)的方式与外部世界交互。因此,我们需要将 Memory Manager 的搜索能力包装成一个符合 Agent 工具规范的对象。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《OpenClaw 核心原理与实战》,新⼈⾸单¥59
《OpenClaw 核心原理与实战》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论