

04|让RAG更聪明:掌握分块的“核心刀法”
陈磊

你好,我是陈磊。
上一篇我们一起聊了很多大模型应用相关的性能指标,这些指标也并不是说每次评价大模型应用都需要,而是根据具体的问题进行选择的。上一节课最开始的那个小狗的例子你还记得吗?我们在那个例子里面就介绍了 RAG 是什么。那么今天我们深入地聊一聊测试开发工程师构建一个 RAG 系统需要掌握的每一个技能点。
RAG 是什么?
RAG 说白了就是给我问的问题找到更多的参考文献,然后把找到的参考文献和我问的问题组合在一起,再去问大模型。简单说就是这样一个过程,就和我们读论文一样,很多时候在论文中总有一些引用的参考文献,如果我们不深入读对应的参考文献,就会有很多文章中的内容无法理解。大模型也是一样,因此我们建立了一个自己的参考文献库,每次大模型需要反馈对应问题的时候,就先去参考文献库里读取参考文献,然后和原来的问题一起组成一个新的提示词,再反馈对应的内容。
说到根源,RAG 也是提示词工程的一个扩展。你现在是不是已经理解 RAG 的作用了?那么下面我们就讲讲 RAG 的具体技术。
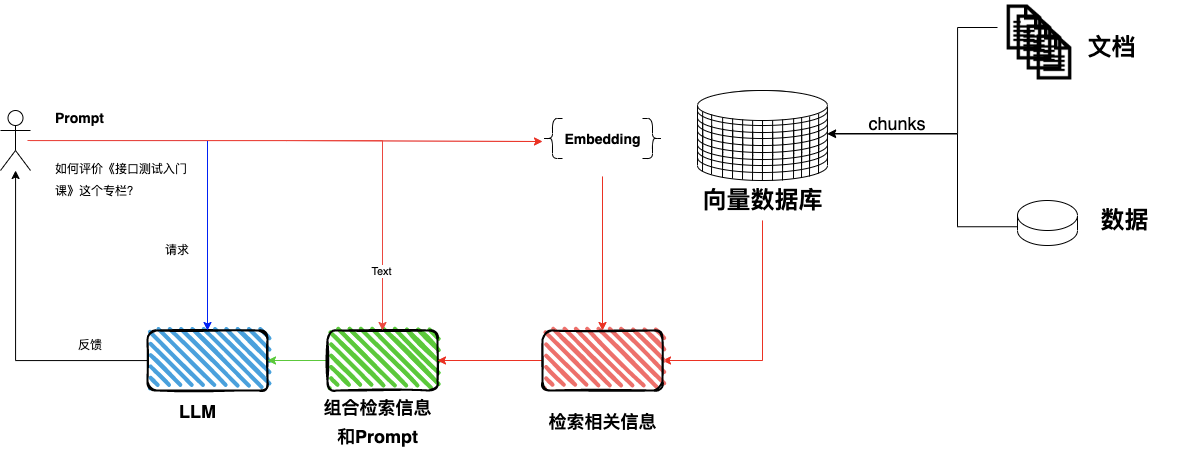
RAG 的全称是 Retrieval-Augmented Generation,中文叫做索引增强生成,顾名思义就是需要一个外部增强的知识库来帮助我们强加更多的输入内容,从而减少幻觉,使模型生成地更准确。比如我问:如何评价接口测试入门课这个专栏?如果没有使用 RAG 技术,问题就会沿着蓝色的线直接反问大模型,然后等待大模型给出反馈。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

1. RAG是Retrieval-Augmented Generation的缩写,是一种索引增强生成技术,通过外部知识库来帮助模型更准确地生成结果。 2. RAG技术的主要目的是减少模型生成过程中的幻觉现象,使结果更准确,幻觉更少。 3. Embedding模型是一种将高维数据转换为低维连续向量表示的机器学习模型,能够捕捉数据的语义或特征,使相似的对象在向量空间中距离较近。 4. 在RAG系统中,选择合适的Embedding模型对于提高准确性至关重要,需要遵循不混用不同Embedding模型的原则。 5. Chunk是将长文本或句子分解成更小、更易处理的语义片段,有助于提高RAG系统的准确性和检索准确率。 6. 刀法选择方法需要依据文档类型、查询需求、系统需求等方面进行统一进行选择,并通过数据驱动的实验进行迭代优化。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《AI 重塑测试开发系统实践》,新⼈⾸单¥29
《AI 重塑测试开发系统实践》,新⼈⾸单¥29
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论