

13|分布式缓存:大Key更新,拆分大Key如何防脏读?
徐逸

你好,我是徐逸。
在上一节课中,我们深入探讨了如何应对 Redis 中的热 Key 问题,并掌握了多种解决方案。然而,在面对高并发的挑战时,我们不仅要关注热 Key 问题,还必须关注另一个可能影响 Redis 性能的因素——大 Key 问题。
今天这节课,我们就来聊聊 Redis 大 Key 问题和相应的解决方案。
什么是大 Key 问题
Redis 作为单线程应用程序,它的请求处理模式类似排队系统,就像下面的图一样,所有请求只能依序逐个处理。一旦处于队列前面的请求处理时间过长,后续请求的等待时间就会被迫延长。
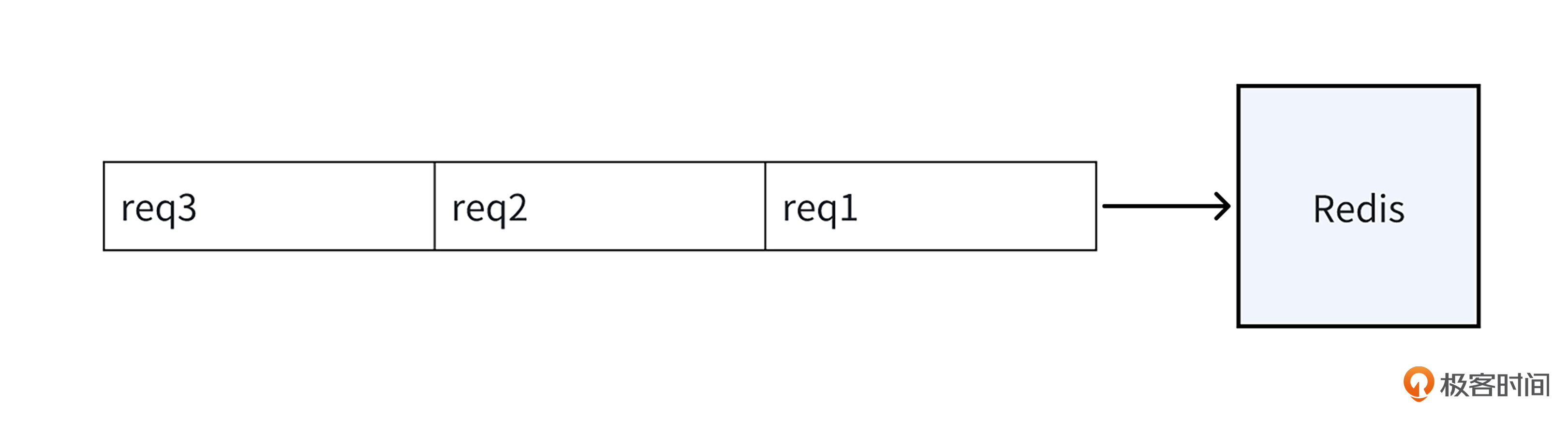
图1 Redis 请求排队处理
在请求处理过程中,若涉及的键(Key)或键关联的值(Value)数据量过大,Redis 针对这个请求的 I/O 操作耗时以及整体处理时间都将显著增加。
倘若这种情况频繁发生,不仅 Redis 的吞吐会下降,而且大量后续请求都会因长时间得不到响应,而导致延迟上涨,甚至引发超时。在实际应用场景中,这种现象被定义为 “大 Key 问题”,而那些数据量过大的键(Key)与值(Value)则被称为 “大 Key”。
当然,要判断什么是“大 Key”,我们得综合考虑两个因素:Key 的大小和 Key 中包含的成员数量。
不过,对于 Key 究竟要达到多大规模或者包含的成员数量具体为多少才能够被认定为大 Key,实际上并没有一个统一的标准,这个标准得根据你的 Redis 配置来定。接下来,我给你分享一些阿里云提供的关于大 Key 的参考标准,这些标准可以作为你判断和处理大 Key 问题的参考。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

1. Redis的大Key问题指的是请求处理中涉及的键或键关联的值数据量过大,导致Redis的I/O操作耗时增加,整体处理时间显著增加,进而影响Redis性能和吞吐。 2. 大Key问题的判断标准包括Key的数据量、Key成员数量以及Key的成员数据量,但并没有统一的标准,需要根据具体Redis配置来定。 3. 针对大Key问题,可以采取数据压缩方案和大Key拆分方案来优化,以减轻大Key问题带来的挑战。 4. 数据压缩方案可以利用序列化工具如Protocol Buffers(PB)对数据进行预处理,减少存储在Redis中的数据大小,降低出现大Key问题的风险。 5. 大Key拆分方案是将一个Key的数据拆分成多个小块,每个小块存入不同的Redis Server里,以避免单个Redis Server处理大Key的压力。 6. 大Key拆分方案的核心难点在于如何有效规避脏读现象,可以借助版本号机制来防止脏读。 7. 通过对大Key进行拆分,并为每个部分添加版本号作为子Key,可以有效避免因拆分操作而可能引发的脏读问题。 8. 两种有效的解决方案是基于PB序列化的数据压缩方案和基于版本号机制的大Key拆分方案。 9. 数据压缩方案和大Key拆分方案可以有效解决大Key问题,提高Redis性能和减轻处理压力。 10. 在实践中,面对大Key问题,还可以探索其他解决方式,欢迎分享和交流经验。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《Go 服务开发高手课》,新⼈⾸单¥59
《Go 服务开发高手课》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论