

11|如何借助LLaMA 3赋能索引构建?
Tyler

讲述:机器人🤖大小:1.95M时长:11:21
你好,我是 Tyler!
上节课我们讨论了检索增强生成(RAG,Retrieval-Augmented Generation)方法中 LLaMA 3 所能带来的提升。今天,我们将深入学习 LLaMA 3 在实际应用中的作用。计算机科学领域有一句常用的话:“垃圾进,垃圾出。” 这句话强调了输入数据的质量对系统输出结果的决定性作用。
在基于 RAG 的模型中,输入数据的质量至关重要,它直接决定了生成内容的优劣。RAG 模型主要由两个环节组成:检索(Retrieval)和生成(Generation)。简而言之,R 负责从知识库中检索相关信息,G 基于检索到的内容生成自然语言回答。由此可见,检索阶段的输入质量直接影响生成阶段的表现。如果想提高生成结果的准确性与上下文相关性,首先需要专注于优化检索阶段的表现,例如提高知识库的覆盖面、检索算法的准确度,以及过滤无关信息的能力。
基于文章片段向量检索的问题
当前许多 RAG 实现采用基于文章片段的向量检索技术,这种方法虽然在某些应用场景下提升了效率,但也存在一些明显的局限性。
语义信息碎片化:为了适应向量检索的机制,长篇文章通常会被切割成多个独立的小片段。然而,这种片段化处理会割裂文章的语义联系,无法完整保留原文中的上下文关联。在生成阶段,系统由于缺乏跨片段的语义信息,可能输出不连贯或前后矛盾的回答。
歧义性问题:向量检索在处理多义词时容易受限于局部片段的信息,无法理解词语的上下文语境。例如,“cloud”既可能指“云计算”,也可能指“气象云”,甚至日常生活中的“云”。如果模型无法正确消解歧义,检索内容可能偏离用户预期。
缺乏全局知识:向量检索基于片段化的文档信息,通常缺乏对整体语境或跨领域知识的综合理解。这使得系统在应对需要全局视角或跨领域信息的任务时表现较差,生成的回答难以深入挖掘信息之间的复杂关系。
优化方案:通过 LLaMA 3 构建 GraphRAG
为了提升 RAG 模型的性能,需要对原始数据进行更加高级的处理,结合更丰富的知识。这里提出的通过 LLaMA 3 模型来构建 GraphRAG 的方法,将结构化的知识图谱与向量检索结合,从而优化信息的检索与生成。
首先,我简要介绍一下知识图谱的概念。知识图谱以三元组形式(主语 - 谓语 - 宾语)来表示信息,捕捉不同知识点之间的关系,并通过这些关系构建出一个相互关联的图结构。知识图谱提供了更深层次的上下文理解,能够帮助系统更好地处理复杂关系,增强生成结果的连贯性与准确性。
在构建知识图谱的过程中,第一步是从原始文本中提取三元组。我们可以利用 LLaMA 3 模型作为 NER 工具,识别出文本中的实体和它们之间的关系。与传统的 NER 方法相比,LLaMA 3 凭借其强大的语义理解能力,能够识别出更复杂和细粒度的实体关系。
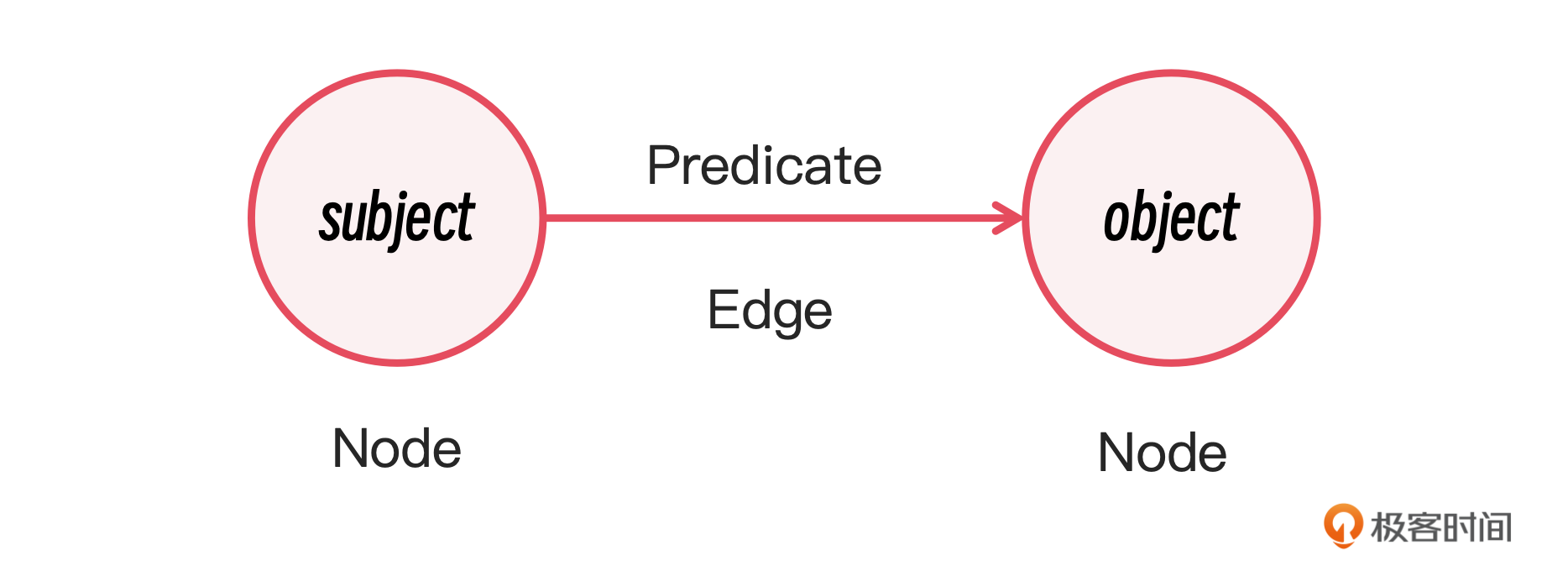
以下是一个具体的三元组示例:
通过 LLaMA 3 模型提取三元组时,系统可以识别文本中的复杂关系。例如,输入的句子可能是:“Albert Einstein 于 1905 年提出了相对论。”
在这个例子中,“Albert Einstein” 是主语,表示一个具体的实体;“提出” 是谓语,描述了主语与宾语之间的关系;“相对论” 是宾语,表示另一个具体的实体。这种结构化的信息表述可以帮助知识图谱捕捉到不同知识点之间的关联。
三元组示例:
主语(Entity 1):Albert Einstein
谓语(Relation):提出
宾语(Entity 2):相对论
下面我来介绍一下如何用 LLaMA 3 来提取三元组。
1. 提示目标 (Goal)
首先,我们需要定义任务目标。提示词的核心要求是:“给定一篇可能与任务相关的文档和实体类型列表,识别文中所有指定类型的实体及其之间的关系。” 这为整个提取任务设定了方向——我们不仅要识别实体,还要深入分析它们之间的关联,以确保最终生成的内容具备准确性和相关性。
2. 实体识别 (Step 1)
接下来,进入实体识别阶段。我们需要从文中提取所有符合要求的实体,包括每个实体的名称、类型和详细描述。提示词明确指出:“识别所有实体,并提取实体名称、实体类型及其描述。” 这是信息提取的基础,确保了后续关系分析的准确性。LLaMA 3 模型在这一过程中能够高效识别出复杂的命名实体,并为它们添加合适的语义标签。
3. 关系识别 (Step 2)
完成实体识别后,进入关系识别阶段。在此步骤中,我们需要从已识别的实体中找出那些有明确关系的实体对,并为每对实体提供关系描述及强度评分。提示词要求:“识别出所有明确相关的实体对,并描述其关系及强度。” 通过这种分析,能够有效构建知识图谱中的关系节点,为后续的生成阶段提供更加连贯的上下文支持。
4. 输出格式 (Step 3 & 4)
最后一步是将识别出的实体和关系以结构化格式输出,以便后续处理和检索。提示词指出:“将步骤 1 和 2 中识别出的实体和关系按统一格式输出。” 格式化的输出不仅提升了数据的组织性,还使得后续模型可以高效解析和应用这些三元组信息,特别是在大规模检索任务中。
微软的 GraphRAG 实现提供了一个实际案例,我们来看一下。
微软的官方 GraphRAG 就是通过这样的提示词,使用大模型生成了构建图片所必要的三元组信息,为 RAG 提供了结构化的索引。
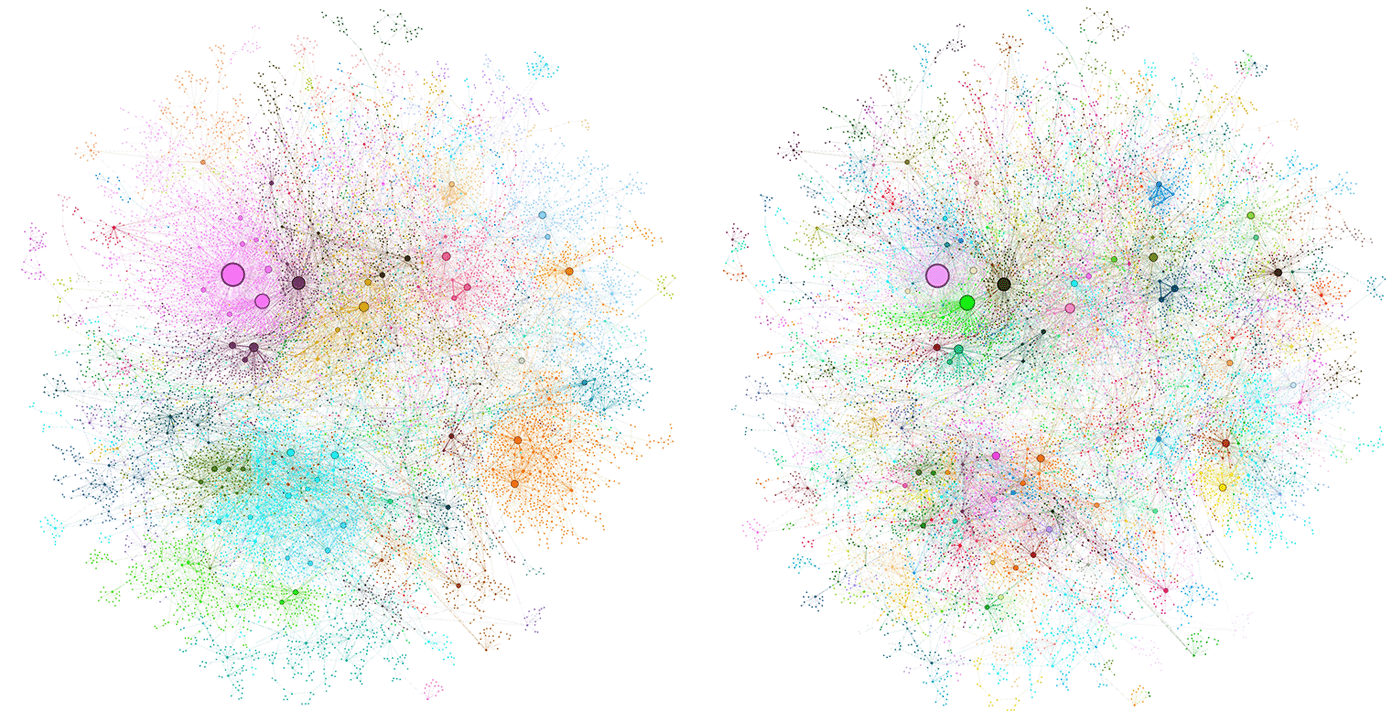
到这里,我们已经成功构建了一个基础的知识图谱,它为后续的信息检索和推理提供了结构化的数据支持。接下来,我们讨论两个关键的检索策略——本地搜索和全局搜索,帮助我们更好地理解如何在知识图谱中高效检索信息。
本地搜索与全局搜索
本地搜索专注于在知识图谱中围绕特定实体或少量相关实体进行的局部检索。这种方法非常适合处理与特定上下文相关的查询任务。例如,当用户的问题与某个具体主题或概念密切相关时,本地搜索能够迅速锁定相关的三元组和实体,避免在整个知识图谱中进行无关的冗余搜索。其优势在于速度快、计算资源消耗低,并能保持上下文的连贯性,尤其适用于具体性较强的问题。
然而,为了使大模型不仅能处理局部问题,还能有效回答全局性的问题,GraphRAG 引入了全局搜索策略。其关键在于社区总结和推理。
具体而言,在索引构建的第二步,GraphRAG 通过层次聚类技术(如常用的 Leiden 算法)对构建好的知识图谱进行社区划分。此过程的目标是将知识图谱按主题划分成多个社区,每个社区包含一组紧密相关的实体和关系。随后,系统为每个社区生成一个摘要,这个摘要可以视为该社区的“主题总结”,帮助我们宏观把握这一部分知识的主要内容。
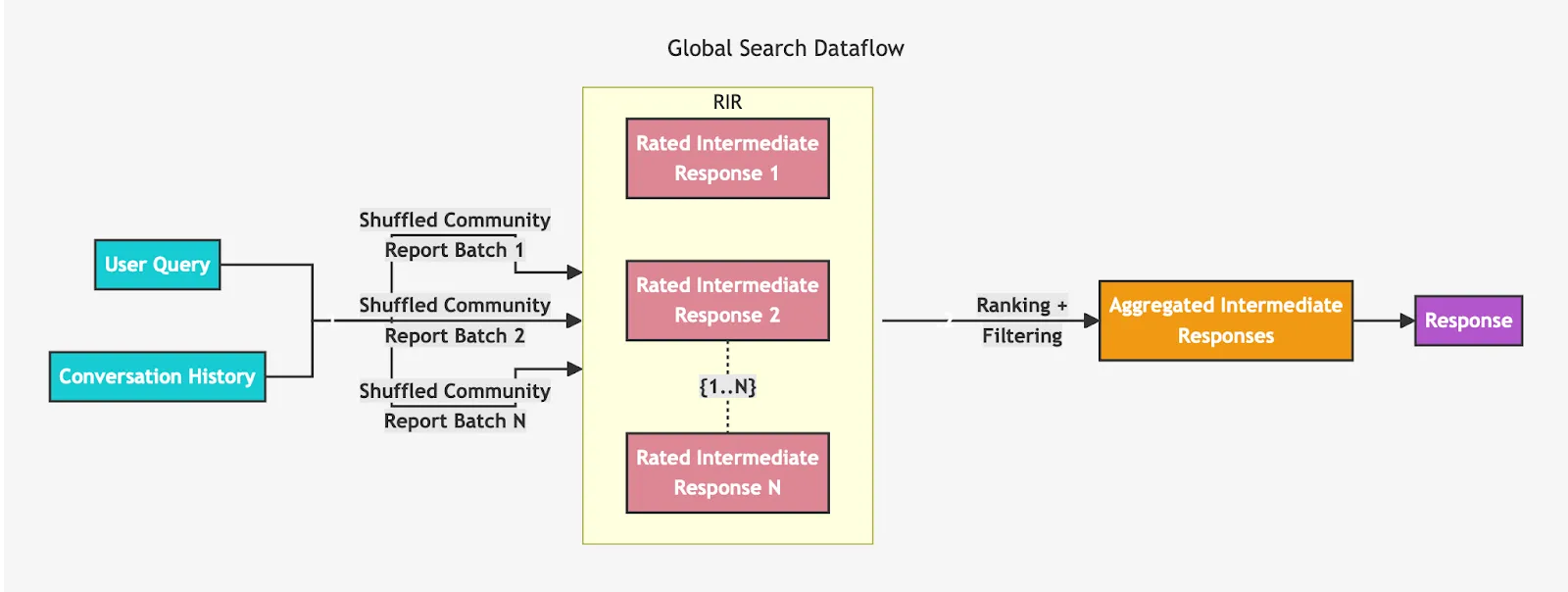
因此,当用户提出宏观问题时,系统能够跳过逐字逐句的精确检索,直接从这些社区摘要中快速找到最相关的总结内容。接下来,大模型可以基于这些预先总结的信息,进一步加工、推理并生成最终答案。这一功能显著提升了系统处理复杂全局问题的能力,尤其在需要跨领域综合知识的场景中表现出色。文末提供了基于 LLaMA 3 实现的 GraphRAG 示例,展示了其具体应用效果。
GraphRAG 的局限性和注意要点
尽管 GraphRAG 展示了强大的搜索和推理能力,但在实际应用中仍然存在一些局限性和需要关注的要点。
1. 性能瓶颈
在构建索引过程中,特别是在进行社区划分和全局搜索时,系统需要进行大量的推理计算。这种高强度的计算需求可能导致性能瓶颈,尤其是在处理大规模数据集时。因此,建议监控系统资源的使用情况,并根据需要进行优化,以确保在满足性能需求的同时,高效完成信息检索和生成任务。
2. 实体识别的模型选择
命名实体识别(NER)是构建知识图谱的关键步骤,负责从文本中提取相关实体。尽管 NER 重要,但其本质相对简单,并不总是需要复杂的大型模型。考虑到资源消耗,可以使用体量较小、效率更高的模型来执行 NER 任务,以提高整体系统的响应速度和处理效率。这一调整不仅能减少资源消耗,还能确保系统在处理高频率请求时的稳定性。
3. 动态更新机制
随着信息的不断更新,静态的知识图谱可能会迅速过时。因此,保持知识图谱的动态性和时效性至关重要。未来的工作可以考虑实现自动化的更新机制,确保知识库中的信息始终是最新的。这样一来,系统在生成内容时将更加准确和相关,能够更好地满足用户的需求。
小结
学到这里,我们做个总结吧。这节课我们讨论了如何利用 LLaMA 3 来优化 RAG 模型的索引构建工作,关键在于通过构建知识图谱来提高信息提取和生成的效果。首先,LLaMA 3 能够高效进行命名实体识别(NER),从原始文本中提取三元组(主语 - 谓语 - 宾语),为知识图谱提供结构化的数据基础。通过准确识别实体及其属性,LLaMA 3 为后续的检索和生成阶段奠定了坚实的基础。
在实体识别过程中,LLaMA 3 还能够分析并提取实体之间的关系,增强生成内容的上下文相关性。此外,GraphRAG 通过应用层次聚类技术对知识图谱进行社区划分,并为每个社区生成主题摘要。这一策略使系统在处理复杂查询时能够快速找到最相关的信息,而无需逐字检索。
LLaMA 3 将这些优化整合到索引生成中,显著提升了 RAG 模型在面对复杂问题时的表现,从而确保系统在检索和生成内容时的准确性和效率。
思考题
在哪些特定场景下,全局搜索能够提供更好的结果?
如果没有全局搜索的需求,知识图谱的方案是否仍然比文档切片检索更有效?
根据课后给出的步骤,将你日常使用的技术文档构建成 GraphRAG,看看是否能够达到意想不到的效果。
欢迎你把你的经验分享到留言区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
1. 创建环境
我们先为 GraphRAG 创建一个新的虚拟环境,使用 Conda 进行方便的管理。执行以下命令来创建并激活环境:
注意:使用 Python 3.11 是因为它与 GraphRAG 和 Ollama 兼容。
2. 安装 GraphRAG 和 Ollama
在环境创建好之后,执行以下命令来安装 GraphRAG 和 Ollama:
3. 准备工作区
创建一个目录来存放 RAG 项目文件:
将你的输入文本文件添加到 input 目录中。请保持文本简短,以减少索引生成所需的时间和计算资源。
4. 初始化 GraphRAG 工作区
执行以下命令来初始化 GraphRAG 工作区:
这个命令将在 ./demo 目录下生成 .env 和 settings.yaml 文件。
.env文件包含了运行 GraphRAG 所需的环境变量,默认情况下会生成一个 GRAPHRAG_API_KEY=<API_KEY>。
settings.yaml文件是 GraphRAG 的设置文件,可以根据需求修改。
5. 配置 GraphRAG 使用 Ollama
修改 .env
将 .env 文件中的 GRAPHRAG_API_KEY 设置为空值:
修改 settings.yaml
在 settings.yaml 文件中进行以下修改,配置 Ollama 进行嵌入计算:
6. 设置 Ollama 进行嵌入计算
安装完成后,执行以下命令来拉取嵌入模型:
这将会下载 nomic-embed-text 嵌入模型,用于 GraphRAG 的嵌入计算。
7. 修改 GraphRAG 代码以支持 Ollama
为了让 Ollama 嵌入模型与 GraphRAG 兼容,我们需要修改 GraphRAG 的部分代码。
查找 GraphRAG 安装目录:
查看输出的 Location 字段,比如 /Users/username/miniconda3/envs/graphenv/lib/python3.11/site-packages。
然后导航到该目录,并找到 graphrag/llm/openai/openai_embeddings_llm.py 文件,替换其内容为以下代码:
保存修改。
8. 运行 GraphRAG
配置完成后,导航到 demo 目录,并执行以下命令来生成索引:
等待索引生成完成。
9. 查询 GraphRAG
一旦索引生成完成,你就可以开始查询了。以下是全局查询的示例:
根据需求,你可以进行更多种类的查询。有关详细查询方式,请参考 GraphRAG 文档。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

1. RAG 模型中的检索阶段对生成阶段的表现具有决定性影响,需要专注于优化检索阶段的表现,包括提高知识库的覆盖面、检索算法的准确度,以及过滤无关信息的能力。 2. 基于文章片段向量检索存在语义信息碎片化、歧义性问题和缺乏全局知识等局限性,影响了生成结果的连贯性与准确性。 3. 通过LLaMA 3 模型构建 GraphRAG,结合知识图谱与向量检索,可以优化信息的检索与生成,提升 RAG 模型的性能。 4. 知识图谱提供了更深层次的上下文理解,能够帮助系统更好地处理复杂关系,增强生成结果的连贯性与准确性。 5. 利用 LLaMA 3 模型作为 NER 工具,可以识别出更复杂和细粒度的实体关系,从而构建结构化的知识图谱。 6. GraphRAG 提供了结构化的索引,为 RAG 提供了基础的知识图谱支持。 7. 知识图谱的构建为后续的信息检索和推理提供了结构化的数据支持。 8. 本地搜索和全局搜索是两个关键的检索策略,帮助在知识图谱中高效检索信息。 9. 优化 RAG 模型的性能需要对原始数据进行更加高级的处理,结合更丰富的知识,以提升生成结果的准确性和相关性。 10. LLaMA 3 模型在实体识别和关系识别阶段能够高效识别出复杂的命名实体,并为它们添加合适的语义标签。
2024-11-06给文章提建议
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《LLaMA 3 前沿模型实战课》,新⼈⾸单¥59
《LLaMA 3 前沿模型实战课》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论