

10|分布式:实现集群化、多副本KV存储引擎
许文强

本课程为精品小课,不标配音频
你好,我是文强。
从技术上看,分布式系统都是基于多副本来实现数据的高可靠存储。因此接下来,我们先来看一下副本和我们前面构建的 Raft 集群的关系。
集群和副本
先来看下图:
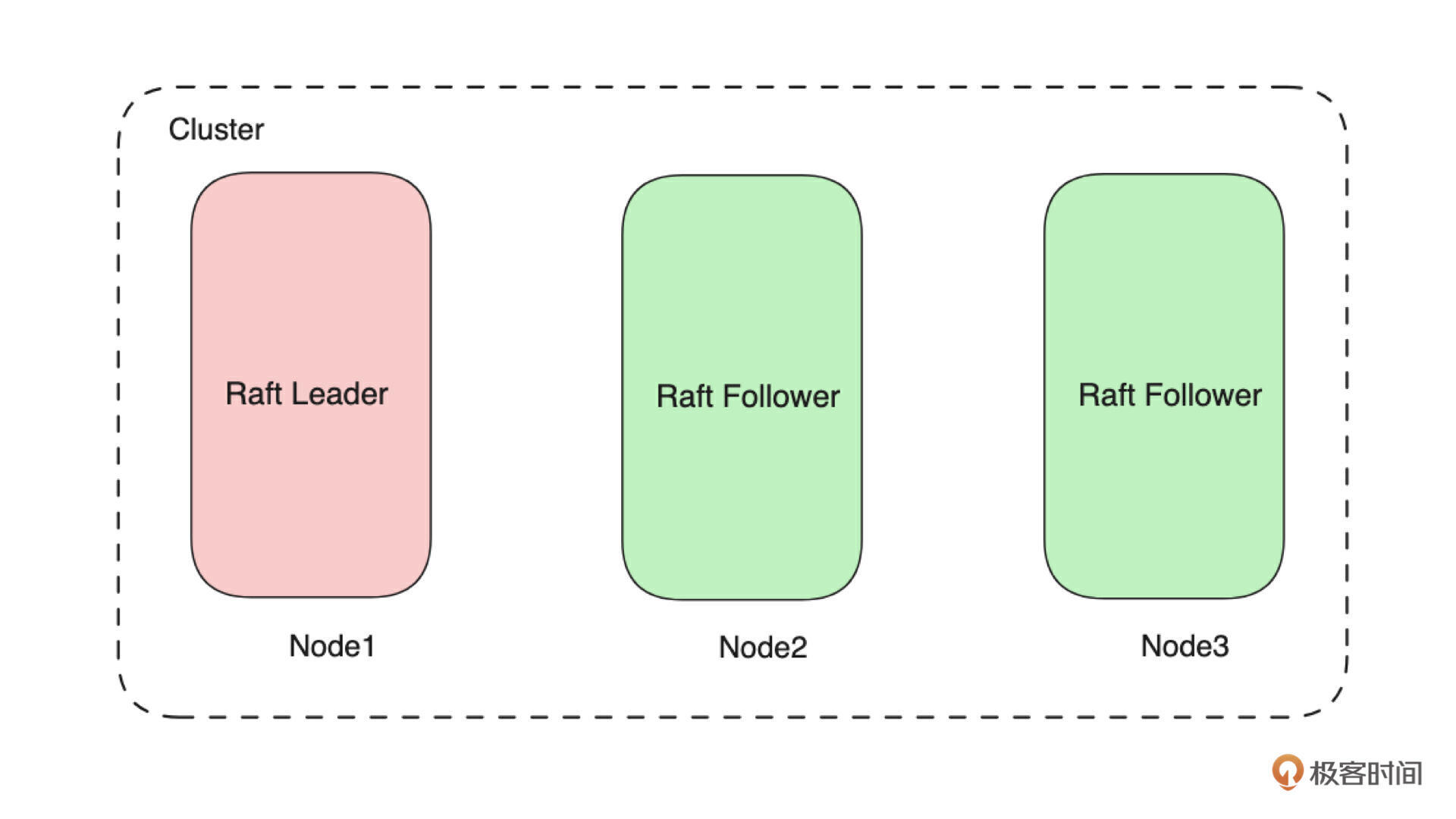
可以看到,这是一个由 3 个节点组成的、基于 Raft 协议构建的集群,它包含 1 个 Leader 节点和 2 个 Follower 节点。因此写入数据时,数据会先写入 Leader 节点,Leader 节点再将数据分发到两个 Follower 节点。
从技术上看这个集群只有一个 Raft 状态机,这个状态机由 3 个 Voter(Node)组成。所以整个集群只能有一个 Leader,也就是在上图中一个节点就是一个副本。如下图所示,如果需要需要新增一个副本,就需要再增加一个节点。
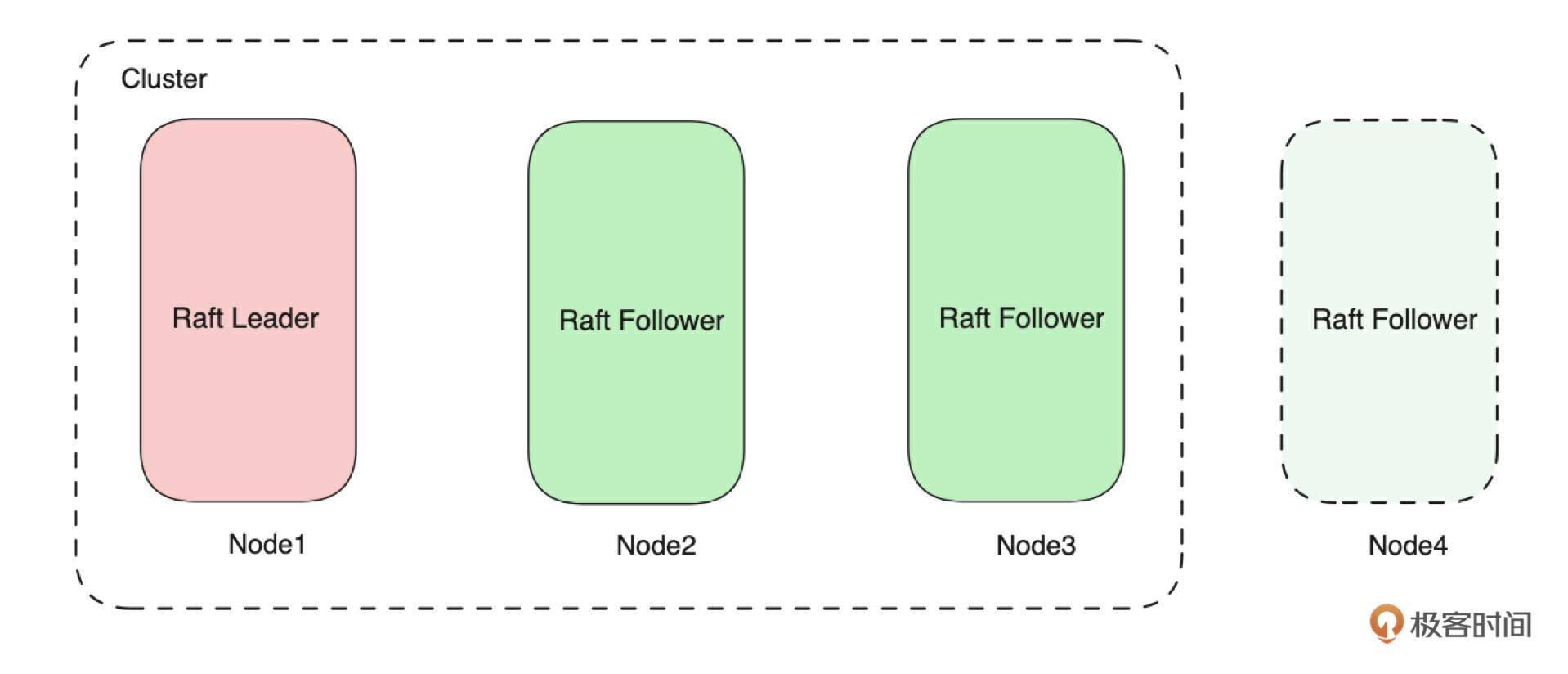
那么就会有一个问题:一个节点上能运行多个副本吗?答案肯定是可以的。来看下图:
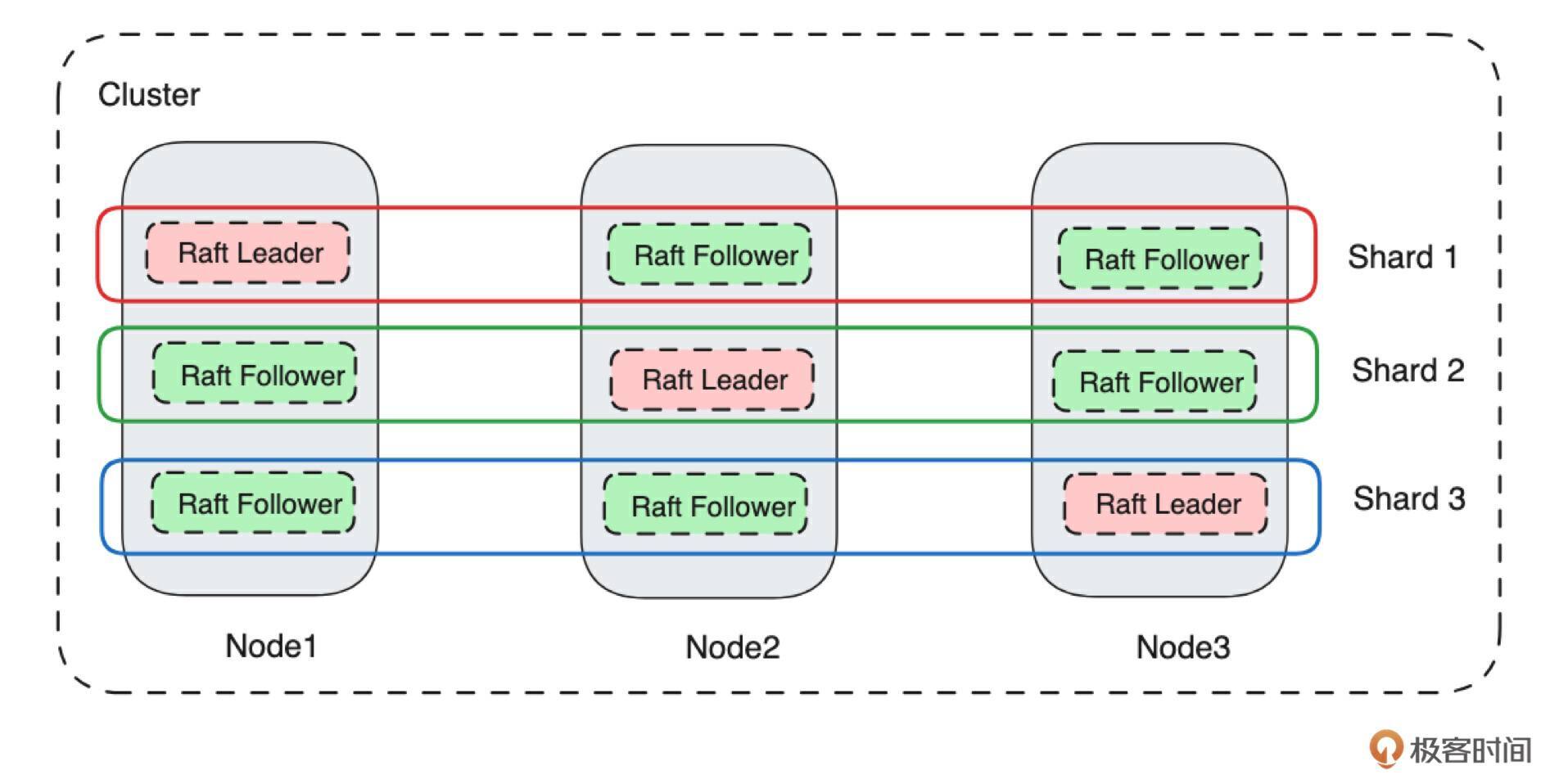
为了在一个节点上运行多个副本,我们首先抽象了 Shard(分片)的概念。从技术上看,一个 Shard 对应一个 Raft 状态机,也就是说每个 Shard 都有自己的 Leader 和 Follower。上图中有 3 个 Shard,每个 Shard 有 1 个 Leader、2 个 Follower。因此总共有 3 个 Leader 及其对应的 6 个 Follower。同一个 Shard 对应的 Leader 和 Follower 都分布在不同的节点上。这是因为副本是为了容灾而存在的,因此同一个 Shard 的不同副本在同一个物理节点上是没有意义的。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

1. 分布式系统基于多副本实现数据的高可靠存储,集群中的节点包含Leader节点和Follower节点,数据先写入Leader节点再分发到Follower节点。 2. 实现集群化、多副本的KV存储引擎需要考虑网络层、一致性协议(Raft)和存储层三部分的交互。 3. 网络层的实现基于gRPC,定义了set/get/delete/exists四个方法及其对应的请求和返回参数,用于客户端读写KV数据。 4. 状态机处理数据的过程是通过apply_propose_message方法将数据传递给Raft状态机处理,并等待处理结果。 5. 需要在网络层和状态机之间实现交互,通过一致性协议(Raft)在Leader、Follower节点之间同步数据,实现数据的高可靠存储。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《Rust 实战 · 手写下一代云原生消息队列》
《Rust 实战 · 手写下一代云原生消息队列》
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论