

06|数据存储:如何实现单机持久化的存储服务?
许文强

本课程为精品小课,不标配音频
你好,我是文强。
上节课我们完成了 Server 模块的开发,接下来我们来实现元数据存储服务中的单机存储层。首先,我们需要来看一下单机存储层的技术方案如何选型。
存储层实现设计考量
如下图所示,我们知道了元数据存储服务的核心是 KV 模型数据的存储。
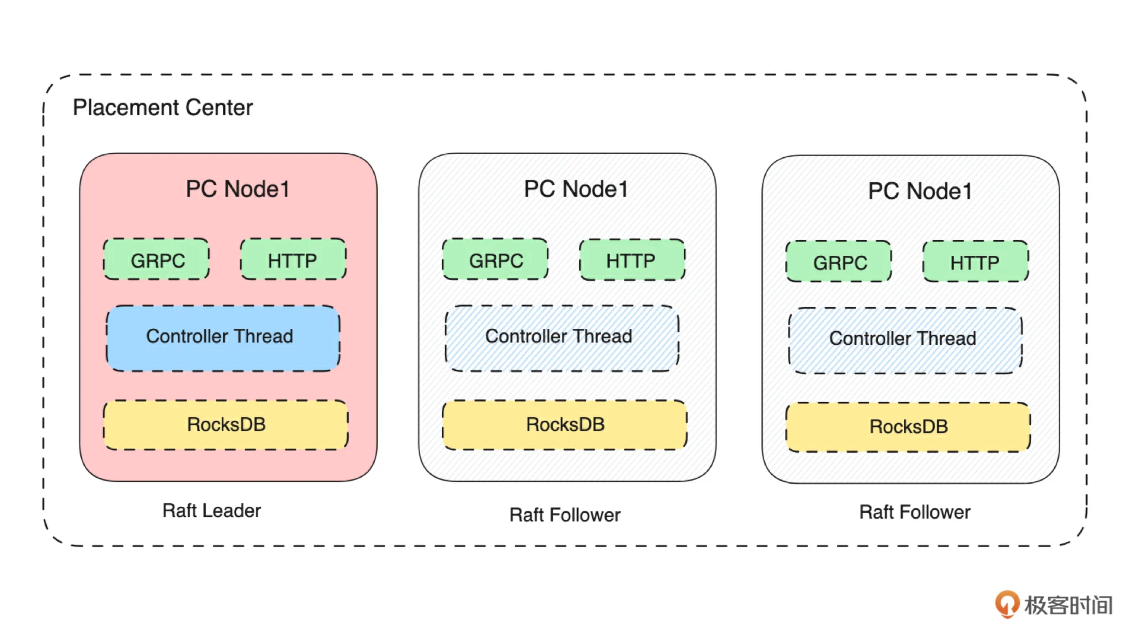
那如何来实现这个存储层呢?从技术上来看,一般有三个思路:
基于文件系统从头实现数据存储。
基于现有成熟的分布式存储引擎完成数据的存储,比如 ZooKeeper、etcd 等。
基于现有成熟的嵌入式键值数据库实现,比如 RocksDB、LevelDB 等。
第一种方案很直观,可能也是我们在选型时首先想到的思路,但是这种方案是最不推荐的。因为从零开始写一个生产级别的存储层是非常困难的,周期很长,稳定性差。比如需要处理硬件和操作系统随时都有可能丢失或损坏数据的情况,另外写入性能优化需要大量时间投入,还得处理代码 Bug 等情况。
第二种方案是常用的方案,依赖成熟的分布式存储引擎存储数据,是比较快速且稳定的方案。但是这种方案的缺点是需要依赖外部系统,会导致架构复杂,长期运维成本高,另外外部依赖组件的稳定性也会影响主系统的稳定。因为我们要实现的消息队列其中一个设计目标就是:高内聚和弱外部依赖。如果选择这种方案,就破坏了这个目标,长期来看,不太合理。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

1. 选择基于现有成熟的嵌入式键值数据库实现存储层的方案,具体选用了RocksDB,考虑了其开发成本低、性能和可靠性有保证等优势。 2. RocksDB的功能介绍,包括提供的主要功能函数调用,以及其作为一个被项目引用的库,存储在单机本地硬盘的文件中,以及基于LSM-Tree实现的本地存储引擎。 3. 介绍了RocksDB中的列簇(ColumnFamily)的概念,以及其在元数据存储服务中的应用。 4. 选择基于RocksDB实现存储层的优势,包括开发成本低、性能和可靠性有保证等方面的考量。 5. Rust中使用RocksDB的基本流程,包括构建RocksDB配置、初始化RocksDB实例、写数据、读取数据、删除数据等操作的实现。 6. 实现了RocksDB中的前缀搜索功能,通过seek方法定位匹配前缀的第一个key,然后通过next方法逐个获取数据,同时判断数据的Key是否匹配所需的前缀。 7. 使用现成的嵌入式键值库简化了高性能高可靠单机存储层的开发,体现了RocksDB、LevelDB设计的初衷。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《Rust 实战 · 手写下一代云原生消息队列》
《Rust 实战 · 手写下一代云原生消息队列》
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论