

05 |数据结构(下):如何设计页面业务问题相关的数据结构?
唐俊开

你好,我是三桥。
上节课,我们重点学习了如何根据最少字段的原则设计链路日志格式的 17 个通用字段。
然而,这些字段并不包含问题信息。假如我们希望提前发现问题,又该怎么把问题涉及的信息提前存储在链路日志里面呢?这节课,我们一起设计记录问题的字段方案。
我从代码维度把日志分成了异常信息、性能数据、操作行为三套数据模型,如下图。
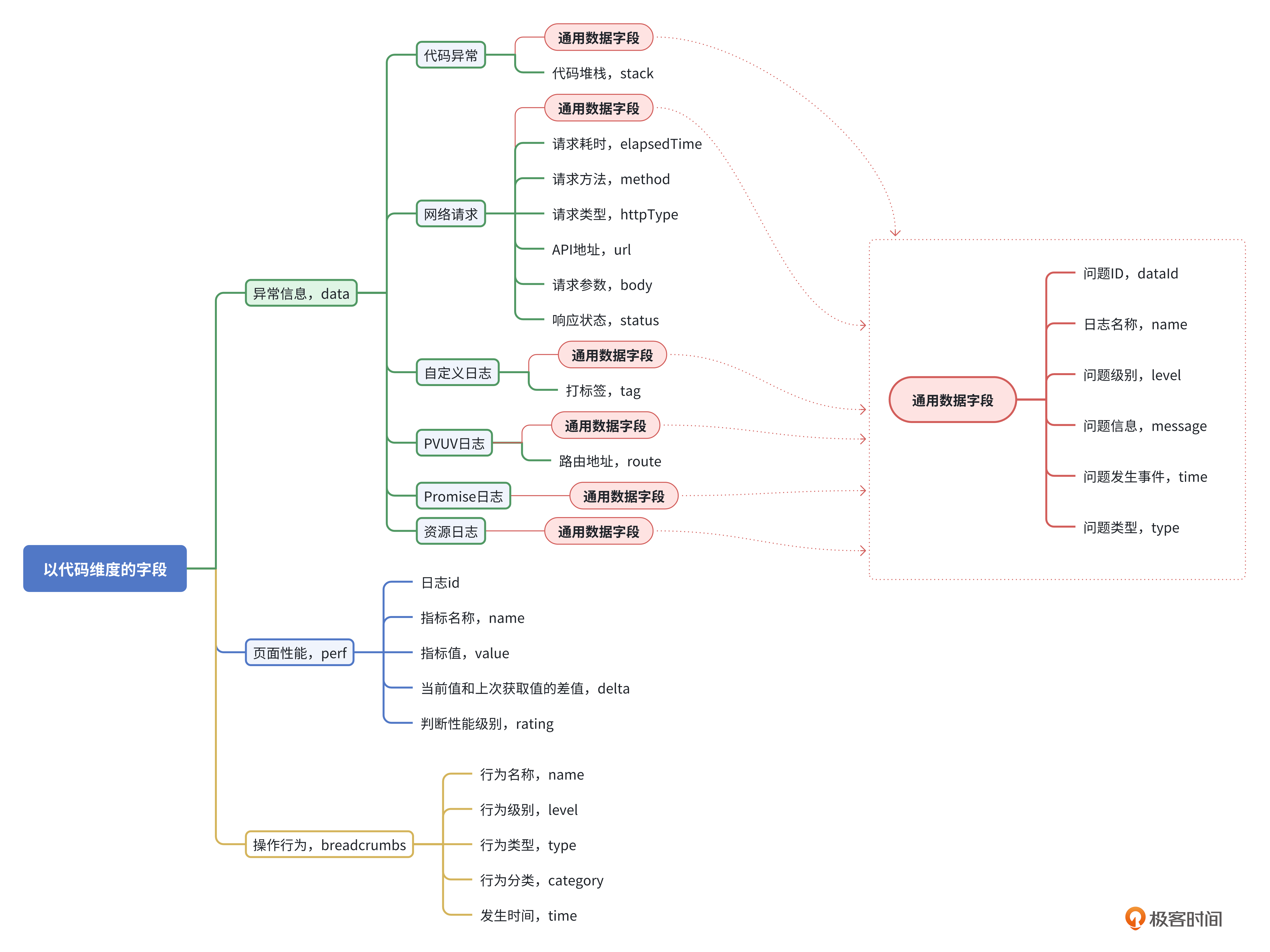
基于这三套数据模型,我们分别用 data 字段记录异常信息、perf 字段记录页面性能信息以及 breadcrumbs 字段记录用户操作行为。参考代码如下。
关于这三个字段的用法,我会在本节课的最后跟大家探讨。我们先从异常信息类型说起。
异常信息类型
虽然前端异常情况有很多,但总结下来,实际主要就是 6 种情况。
代码异常。不仅包括脚本失败,还应该包含 trycatch 中的 catch 异常。
Promise 异常。这主要是由异步代码引起的逻辑问题。
网络请求。通常来说,发起 http 请求都无法保证 100% 的成功率。
资源异常信息。和网络请求同理,但这里的重点在于监控图片和一些外部资源的请求状态。
PV/UV 日志。用于记录用户访问的次数和频率,它也是唯一的非异常日志。
自定义日志。目的是在一些特殊场景下记录日志,以便快速定位问题。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

1. 本节课主要讨论了如何设计页面业务问题相关的数据结构,包括异常信息、性能数据和操作行为三套数据模型。 2. 异常信息类型主要包括代码异常、Promise异常、网络请求、资源异常信息、PV/UV日志和自定义日志,通过抽象化方法设计了通用数据字段和特殊字段组合,遵循最少字段设计原则。 3. 页面性能数据的设计使用了WebVitals来评估页面性能,设计了6个指标、12个属性值的数据模型,以便清晰地了解每个指标值的实际情况。 4. 操作行为类型的设计包括了5个属性字段,定义了行为日志和行为动作相关的信息,以及两个枚举类型的区别和定义。 5. 整合一份完整的链路日志类型定义,包括记录错误信息、操作行为和性能信息,以确保字段命名不重复并根据实际情况设定是否需要上报到服务器端。 6. 异常信息类型的设计是以最少字段为原则,分为异常信息类、网页指标类和操作行为类,其中代码异常和网络请求是最常见且重要的场景,需要特别重视。 7. 网页指标类型的设计基于WebVitals的理论,定义了6个核心指标和12个字段属性,以适应每个页面指标的获取并不同步的情况。 8. 用户的操作行为类型设计了6个字段,以保证能够还原出用户交互的一个快照,帮助快速了解用户的真实情况。 9. 在前端项目中,最常遇到的线上问题是关于哪一类业务的,以及在没有链路日志和监控的情况下,如何通过埋点解决这些问题。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《前端全链路优化实战课》,新⼈⾸单¥59
《前端全链路优化实战课》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(2)
- 最新
- 精选
 Cloudy请问本文中使用到的类型 BaseTraceInfo 是在哪儿定义的?看最后的案例,感觉是前一篇文章中定义的类型 BaseTraceData2024-04-24归属地:广东
Cloudy请问本文中使用到的类型 BaseTraceInfo 是在哪儿定义的?看最后的案例,感觉是前一篇文章中定义的类型 BaseTraceData2024-04-24归属地:广东- Sklei
 pv数据是自动采集还是需要用户手动埋点采集2024-04-24归属地:广东
pv数据是自动采集还是需要用户手动埋点采集2024-04-24归属地:广东
收起评论