

20|安全:如何设计高吞吐和大流量分布式集群的限流方案?
许文强

你好,我是文强。
上节课讲了网络隔离、传输加密、认证、鉴权,今天我们继续讲消息队列系统安全的第二部分:数据自我保护和服务自我保护。
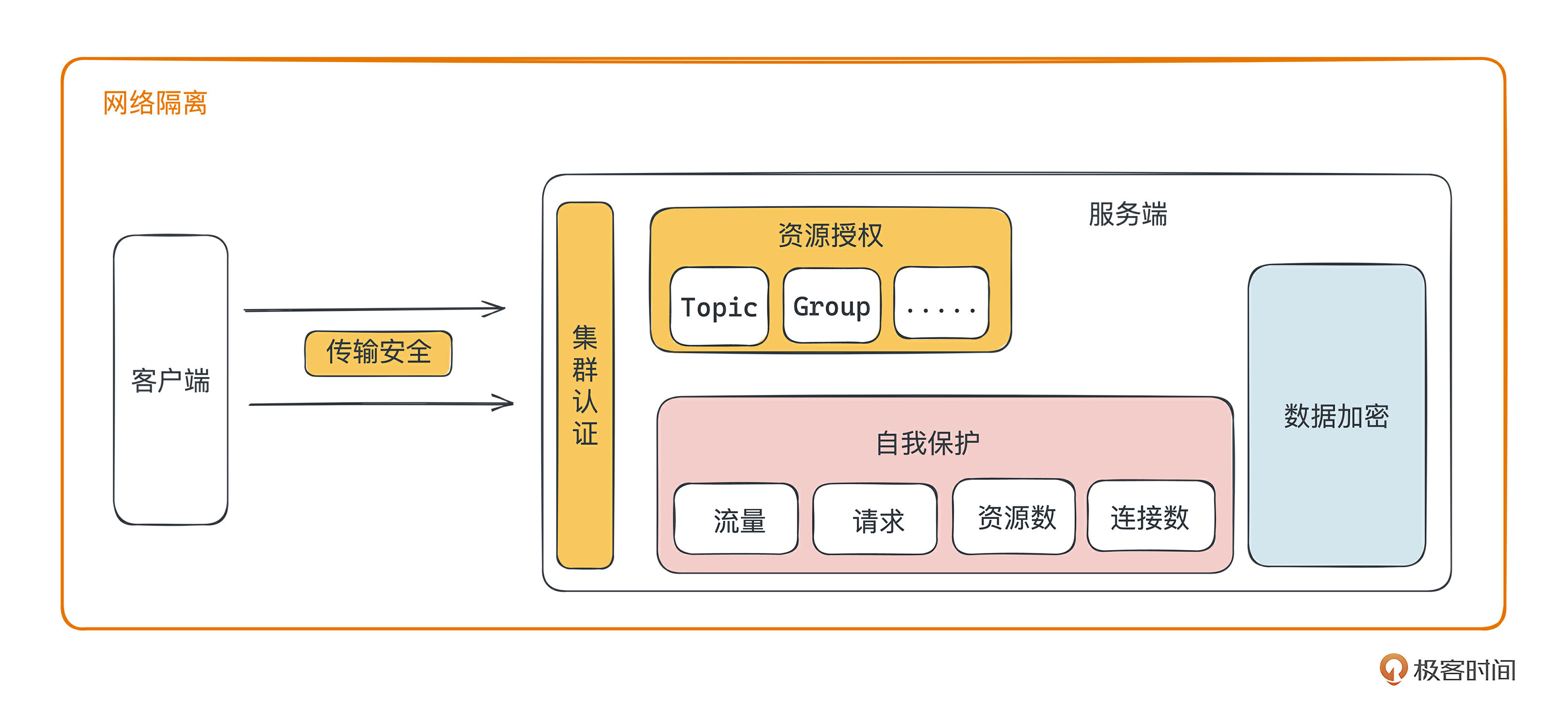
数据维度的自我保护主要指如何保证服务端数据的安全,不被窃取。服务维度的自我保护主要指集群的限流机制,通过限制客户端的流量、请求、连接等保护自身不被击垮。
我们先来看一下如何保证存储的数据不会被第三方窃取。
集群中的数据加密
如果你从事金融或证券领域,因为企业的数据比较重要,应该经常会问:发送到消息队列中的数据能不能加密后再存储?
这个问题希望达到的效果是:当客户端发送消息 A(比如 hello world)到 Broker,Broker 保存到磁盘的数据是一串内容 A 加密后的字符串,当消费端消费数据时,Broker 将加密后的字符串解密成消息 A 返回给消费端。
在业务看来,数据加密配合传输加密、认证、鉴权等机制,在数据的安全性上是非常强的。
要实现这个效果一般有以下两种方案:
第一种就是上面说的,由服务端自动化做好加密解密。工作量全在服务端,客户端没有任何工作量。
第二种是客户端在生产的时候自助做好加密逻辑,在消费的时候自助做好解密操作。好处在于消息队列服务端没有任何工作量,坏处在于工作量全部在客户端,所有的客户端和消费端都需要感知加密的逻辑,在编码和协调各方的成本方面较高。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了设计高吞吐和大流量分布式集群的限流方案,主要涉及消息队列系统安全的数据自我保护和服务自我保护。在数据维度的自我保护方面,讨论了数据加密的实现方案和加密算法的选择。在服务维度的自我保护方面,探讨了消息队列限流机制的实现机制和常见算法,并对全局限流和单机限流进行了比较和选择建议。文章还提出了对资源和维度进行限流的建议。总体而言,本文为设计高吞吐和大流量分布式集群的限流方案提供了有益的参考。文章还讨论了对哪些资源和维度进行限流,以及发生限流后的处理方式。此外,还介绍了消息队列全局限流设计和消息队列的服务降级策略。整体而言,本文对消息队列系统安全的相关技术特点进行了深入探讨,为读者提供了全面的技术概览。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《深入拆解消息队列 47 讲》,新⼈⾸单¥59
《深入拆解消息队列 47 讲》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(1)
- 最新
- 精选
 贝氏倭狐猴老师您好,关于全局限流问个问题。如果均摊总限流数到各个broker,会导致发生限流时总流量低于总阈值,因为broker之间的流量可能是不均衡的。而且如果只是简单均摊的话,也不需要redis等中间存储介质了。2023-08-05归属地:江苏
贝氏倭狐猴老师您好,关于全局限流问个问题。如果均摊总限流数到各个broker,会导致发生限流时总流量低于总阈值,因为broker之间的流量可能是不均衡的。而且如果只是简单均摊的话,也不需要redis等中间存储介质了。2023-08-05归属地:江苏
收起评论

