

07|生产端:生产者客户端的SDK有哪些设计要点?

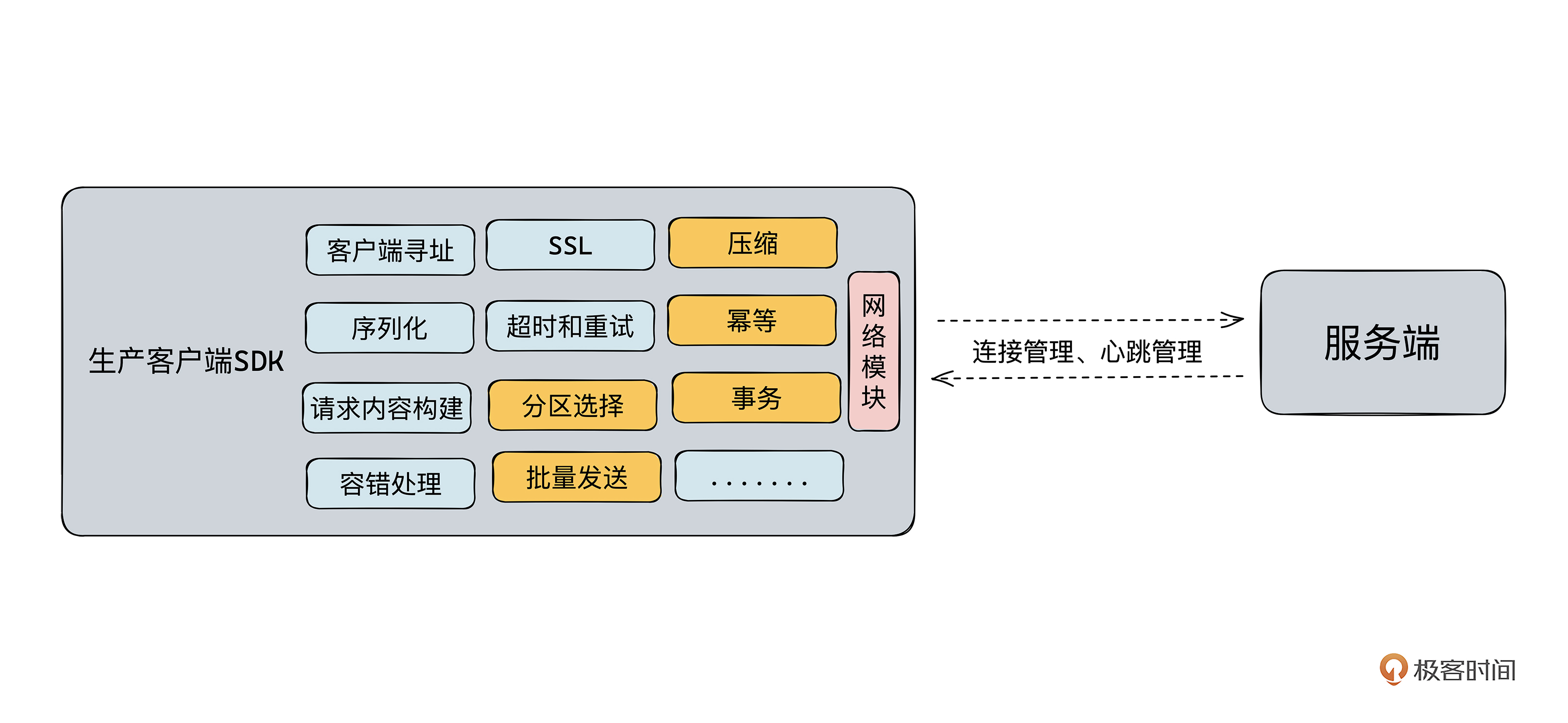
客户端基础功能
连接管理
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文深入介绍了消息队列生产者客户端SDK设计的关键要点,包括连接管理、心跳检测、错误处理和重试机制等功能。建议晚建立连接以提高资源利用率,并通过TCP的KeepAlive保活机制或应用层主动探测实现心跳检测,以保持连接活跃。客户端通过策略进行重试以确保生产流程的顺利进行,并支持重试次数和退避时间的配置。此外,客户端还支持传输加密、压缩、事务、幂等等功能。文章还介绍了客户端寻址机制和生产分区分配策略,以及批量语义和数据发送方式。总体而言,本文深入探讨了消息队列生产者客户端SDK的实现原理和功能特点,对读者了解该领域具有重要参考价值。
《深入拆解消息队列 47 讲》,新⼈⾸单¥59

全部留言(11)
- 最新
- 精选
 张申傲【重试机制】也可以参考下spring-retry框架(仅针对Java的同学),个人认为设计地比较完善,里面的maxAttempts、backoff、RetryCallback等机制都是具有通用性的~ https://github.com/spring-projects/spring-retry
张申傲【重试机制】也可以参考下spring-retry框架(仅针对Java的同学),个人认为设计地比较完善,里面的maxAttempts、backoff、RetryCallback等机制都是具有通用性的~ https://github.com/spring-projects/spring-retry作者回复: 是的,非常好~ 这块都是通用的。 大家理解了设计原理,就自然可以看到在很多知名组件里面都是这么玩的。
2023-07-05归属地:北京6 aoe对「服务端内部转发机制」相对于「Metadata 寻址机制」多了一次转发的思考: 1. 导致成倍消耗资源(内存、网络带宽),不适合大流量、高吞吐场景 2. 增加了消息丢失的风险 3. 「计算目标节点」对 CPU 的消耗并没有增加,只是从「客户端」转移到了「服务端」,没有优化的空间
aoe对「服务端内部转发机制」相对于「Metadata 寻址机制」多了一次转发的思考: 1. 导致成倍消耗资源(内存、网络带宽),不适合大流量、高吞吐场景 2. 增加了消息丢失的风险 3. 「计算目标节点」对 CPU 的消耗并没有增加,只是从「客户端」转移到了「服务端」,没有优化的空间作者回复: 1. 是的 2. 我个人理解应该还好,转发失败就是写入失败,客户端是有感知的,此时重新发送就可以。此时只要写入成功,数据应该不会丢失。 3. 是的, 主要成本在于客户端SDK的寻址模块的开发成本
2023-07-05归属地:浙江1 cykuo回答一下思考题目,大方向上可以从功能上拆分为最基本的消息生产,消息消费,连接创建,连接管理。在消息重试机制上要考虑消息生产和消息消费ack机制,在消息批量发送上要考虑消息打包和拆包,以及生产之前的编码和消费消息后的解码,,,要考虑的真的好多,感觉做一个生产可用的企业级消息中间件太了不起了
cykuo回答一下思考题目,大方向上可以从功能上拆分为最基本的消息生产,消息消费,连接创建,连接管理。在消息重试机制上要考虑消息生产和消息消费ack机制,在消息批量发送上要考虑消息打包和拆包,以及生产之前的编码和消费消息后的解码,,,要考虑的真的好多,感觉做一个生产可用的企业级消息中间件太了不起了作者回复: 是的,要考虑的东西非常多,所以需要有一个系统的了解。可以根据本节的内容,尝试再细化一下这个答案,比如画个思维导图,梳理有哪些模块,如何选型,如何实现等等
2023-07-06归属地:北京 文敦复为了保证元数据的即时性,可以采用下面2种方式。 1. 定期更新 2. 请求出错时更新 对于第2种,是不是意味着如果出错后的更新还没有找到分区信息就属于就属于不可恢复异常了?
文敦复为了保证元数据的即时性,可以采用下面2种方式。 1. 定期更新 2. 请求出错时更新 对于第2种,是不是意味着如果出错后的更新还没有找到分区信息就属于就属于不可恢复异常了?作者回复: 是不是意味着如果出错后的更新还没有找到分区信息就属于就属于不可恢复异常了? --------- 在实际实现上,找不到分区会直接定义为”可重试异常“,然后不停的重试。这样的好处是: 1. 如果一开始topic不存在,然后配合服务端自动创建topic,只要服务端有了topic,客户端业务就自动恢复正常了 2. 如果Leader 切换,也可能在一段时间内会报这个异常,一直重试,可以解决这种leader切换的场景。 3. 在一些其他的场景,只要客户端不断重试,只要客户端分区存在了,客户端就会立即恢复正常,不需要客户端手动去处理。 整体下来,总结好处就是客户端不会报错,会自动恢复,显得更加友好。
2023-07-05归属地:四川- 文敦复请教下老师,这个地方不太清楚,文章提到:“因为单个 TCP 连接发送性能存在上限,我们就需要在客户端启动多个生产者,提高并发读写的能力。一般情况下,每个生产者会有一个唯一的 ID 或唯一标识来标识客户端,比如 ProduceID 或客户端的 IP+Port。” 这里的“客户端”指什么?我的理解其并不是一个物理上的客户端节点吧,而是整个客户端组?
作者回复: 客户端是指我们自己的业务应用,我们用来调用消息队列的服务的应用。 比如订单服务,它需要使用到RocketMQ,此时就需要在订单服务创建多个生产者,以提高写入/消费的性能。 此时,客户端就是指我们的业务应用。
2023-07-05归属地:四川2 - Geek_f31639不知道专栏会不会给出一个简单mq实现的代码例子?
作者回复: 有这个诉求的同学蛮多的,我自己后面有这个计划。可以加课程的微信群沟通交流哈。 当前这门课你可以理解是一个技术选型,方案设计的过程,在结课的时候技术方案就设计完成了。 接下来就是实操去写一个简单的MQ了。
2023-07-05归属地:上海2  Spoon以RocketMQ为例,这个集群管理SDK连接的是 1、NameSrv 2、Broker 3、NameSrv+Broker 比较adminSDK是怎么实现了,作者这里说的比较少,准备看看RocketMQ源码探寻一下2024-03-10归属地:浙江
Spoon以RocketMQ为例,这个集群管理SDK连接的是 1、NameSrv 2、Broker 3、NameSrv+Broker 比较adminSDK是怎么实现了,作者这里说的比较少,准备看看RocketMQ源码探寻一下2024-03-10归属地:浙江 shan客户端基础功能总结 1. 连接管理 (1)初始化创建连接:客户端在初始化时创建与各个Broker的连接,缺点是需要提前创建好连接,可能导致连接空跑消耗一定资源; (2)使用时创建连接:需要向Broker发送数据时才建立连接,连接使用率高,缺点是会增加本次请求的耗时;(建议方式) 2.心跳检测 心跳检测是客户端和服务端之间一种保活机制,当一方不可用时及时发现对资源进行回收避免浪费。 (1)基于TCP的KeepAlive保活机制:TCP/IP协议层内置功能,需要手动打开。这种方式实现简单,缺点是需要服务端主动发出检测包,如果客户端异常,可能出现很多不可用TCP连接占用内存资源,导致性能下降; (2)应用层主动探测:客户端主动向服务端发起心跳请求,如果服务端在一定时间内没有收到请求就断开连接,一般采用的是这种方式; 3.错误处理 发生错误后,一般会提供重试策略。当消息发送失败时会重试,超过一定次数后抛弃消息或者投递到指定好的队列。 这里说下RocketMQ,可以配置的失败重试次数,并且提供了故障延迟机制,假设向某个Broker发送失败,之后会在某个时间段内规避这个Broker,避免往这个Broker发送数据。 4. 生产相关功能 一、客户端寻找发送到哪个Broker (1)服务端提供获取全量元数据的接口,客户端通过接口拿到数据之后缓存到本地,根据元数据中的信息查找需要往哪个Broker上发送数据。 (2)服务端内部转发,每一台Broker都缓存所有节点元数据信息,生产者如果发给Broker之后,分区不在当前节点上,再进行查找将消息转发到目标Broker,不适合大流量高吞吐的消息队列,目前RabbitMQ采用的这个方案。 二、数据写入到哪个分区/消息队列 (1)轮询方式写入到各个分区; (2)按Key计算hash值,根据分区总数取余; (3)手动指定; (4)自定义分区分配策略; 三、批量 一般在客户端内存中维护一个队列,先将数据写入到这个内存队列,再通过某个策略从内存队列读取数据发送到服务端。 四、数据发送方式 同步发送、异步发送、发送即忘; 五、集群管控 一般会提供多种集群管理方式,比如命令行、客户端、HTTP 接口等。2023-09-23归属地:美国
shan客户端基础功能总结 1. 连接管理 (1)初始化创建连接:客户端在初始化时创建与各个Broker的连接,缺点是需要提前创建好连接,可能导致连接空跑消耗一定资源; (2)使用时创建连接:需要向Broker发送数据时才建立连接,连接使用率高,缺点是会增加本次请求的耗时;(建议方式) 2.心跳检测 心跳检测是客户端和服务端之间一种保活机制,当一方不可用时及时发现对资源进行回收避免浪费。 (1)基于TCP的KeepAlive保活机制:TCP/IP协议层内置功能,需要手动打开。这种方式实现简单,缺点是需要服务端主动发出检测包,如果客户端异常,可能出现很多不可用TCP连接占用内存资源,导致性能下降; (2)应用层主动探测:客户端主动向服务端发起心跳请求,如果服务端在一定时间内没有收到请求就断开连接,一般采用的是这种方式; 3.错误处理 发生错误后,一般会提供重试策略。当消息发送失败时会重试,超过一定次数后抛弃消息或者投递到指定好的队列。 这里说下RocketMQ,可以配置的失败重试次数,并且提供了故障延迟机制,假设向某个Broker发送失败,之后会在某个时间段内规避这个Broker,避免往这个Broker发送数据。 4. 生产相关功能 一、客户端寻找发送到哪个Broker (1)服务端提供获取全量元数据的接口,客户端通过接口拿到数据之后缓存到本地,根据元数据中的信息查找需要往哪个Broker上发送数据。 (2)服务端内部转发,每一台Broker都缓存所有节点元数据信息,生产者如果发给Broker之后,分区不在当前节点上,再进行查找将消息转发到目标Broker,不适合大流量高吞吐的消息队列,目前RabbitMQ采用的这个方案。 二、数据写入到哪个分区/消息队列 (1)轮询方式写入到各个分区; (2)按Key计算hash值,根据分区总数取余; (3)手动指定; (4)自定义分区分配策略; 三、批量 一般在客户端内存中维护一个队列,先将数据写入到这个内存队列,再通过某个策略从内存队列读取数据发送到服务端。 四、数据发送方式 同步发送、异步发送、发送即忘; 五、集群管控 一般会提供多种集群管理方式,比如命令行、客户端、HTTP 接口等。2023-09-23归属地:美国 奔腾ing老师,我们选型是rabbitmq,我目前基于开源的librabbitmq-cpp封装了一层,如果业务方之做生产者,在开启心跳功能后,发现rabbitmq不认sdk回复心跳的ack消息,从网络抓包看sdk都是有回复ack消息的,不过rabbitmq每次发送的心跳中ack字段都是1,过一会,rabbitmq日志中会打印因心跳超时断掉连接的情况。如果业务方做消费者,就不会有这个问题。目前的处理思路是,sdk内部在连接上rabbitmq后,主动起一个线程去发送心跳帧。不太明白,为啥rabbitmq会不认,生产者回复的心跳ack消息。2023-08-14归属地:浙江
奔腾ing老师,我们选型是rabbitmq,我目前基于开源的librabbitmq-cpp封装了一层,如果业务方之做生产者,在开启心跳功能后,发现rabbitmq不认sdk回复心跳的ack消息,从网络抓包看sdk都是有回复ack消息的,不过rabbitmq每次发送的心跳中ack字段都是1,过一会,rabbitmq日志中会打印因心跳超时断掉连接的情况。如果业务方做消费者,就不会有这个问题。目前的处理思路是,sdk内部在连接上rabbitmq后,主动起一个线程去发送心跳帧。不太明白,为啥rabbitmq会不认,生产者回复的心跳ack消息。2023-08-14归属地:浙江
 特修斯之船"需要 Server 主动发出检测包,此时如果客户端异常,可能出现很多不可用的 TCP 连接。" 这一句,怎么感觉理由不够充分呢,服务器等一下不也是知道客户端异常了吗,真的需要因为这理由让应用层去再做一层心跳吗?2023-07-19归属地:广东
特修斯之船"需要 Server 主动发出检测包,此时如果客户端异常,可能出现很多不可用的 TCP 连接。" 这一句,怎么感觉理由不够充分呢,服务器等一下不也是知道客户端异常了吗,真的需要因为这理由让应用层去再做一层心跳吗?2023-07-19归属地:广东

