批处理 ETL 已经消亡,Apache Kafka 才是数据处理的未来吗?
Daniel Bryant

在QCon 旧金山2016 会议上,Neha Narkhede 做了“ETL 已死,而实时流长存”的演讲,并讨论了企业级数据处理领域所面临的挑战。该演讲的核心前提是开源的 Apache Kafka 流处理平台能够提供灵活且统一的框架,支持数据转换和处理的现代需求。
Narkhede是 Confluent 的联合创始人和 CTO,在演讲中,他首先阐述了在过去的十年间,数据和数据系统的重要变化。该领域的传统功能包括提供联机事务处理(online transaction processing,OLTP)的操作性数据库以及提供在线分析处理(online analytical processing,OLAP)的关系型数据仓库。来自各种操作性数据库的数据会以批处理的方式加载到数据仓库的主模式中,批处理运行的周期可能是每天一次或两次。这种数据集成过程通常称为抽取 - 转换 - 加载(extract-transform-load,ETL)。
最近的一些数据发展趋势推动传统的 ETL 架构发生了巨大的变化:
单服务器的数据库正在被各种分布式数据平台所取代,这种平台在整个公司范围内运行;
除了事务性数据之外,现在有了类型更多的数据源,比如日志、传感器、指标数据等;
流数据得到了普遍性增长,在速度方面比每日的批处理有了更快的业务需求。
这些趋势所造成的后果就是传统的数据集成方式最终看起来像一团乱麻,比如组合自定义的转换脚本、使用企业级中间件如企业服务总线(ESB)和消息队列(MQ)以及像 Hadoop 这样的批处理技术。
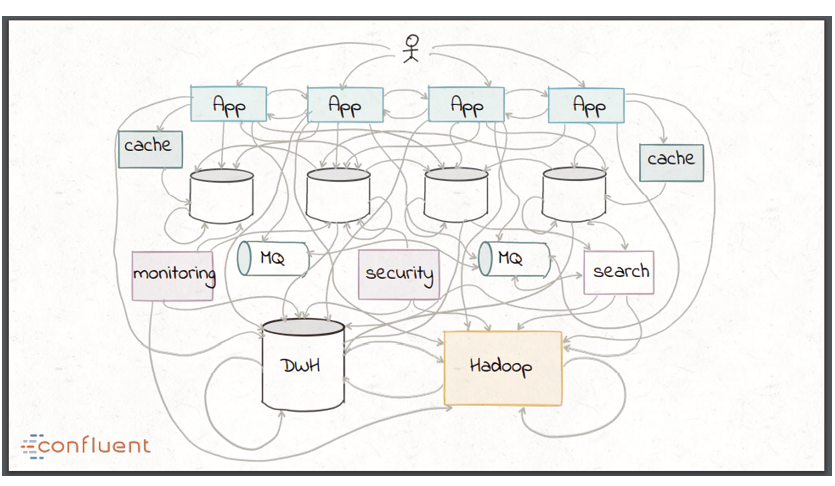
在探讨现代流处理技术如何缓解这些问题之前,Narkhede 简要回顾了一下数据集成的历史。在上世纪 90 年代的零售行业中,业务得到了一些新形式的数据,所以对购买者行为趋势进行分析的需求迫切增长。存储在 OLTP 数据库中的操作性数据必须要进行抽取、转换为目标仓库模式,然后加载到中心数据仓库中。这项技术在过去二十年间不断成熟,但是数据仓库中的数据覆盖度依然相对非常低,这主要归因于 ETL 的如下缺点:
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

Apache Kafka作为流处理平台,正在逐渐取代传统的批处理ETL架构,成为数据处理的未来。在Neha Narkhede的演讲中,她指出了传统ETL架构在面对现代数据处理需求时的种种不足,如需要全局模式、手工操作易出错、操作成本高等。而现代流处理技术如Apache Kafka则能够解决这些问题,它能够处理大量且多样性的数据,支持实时处理,提供向前兼容的数据架构,以及有效的运维和监控。Kafka作为一个开源流平台,已经被广泛应用于世界各地的组织中,每天处理着庞大的消息量。其基于log的理念和发布-订阅的语义,使得它能够实现实时的数据处理和转换,消除了传统ETL架构中定制化的抽取、转换和加载组件的需求。此外,Kafka Streams API提供了便利的DSL和丰富的操作符,支持每次一个事件的流处理,以及对本地状态的支持和流的重新处理。Narkhede认为,Apache Kafka能够提供“ETL的崭新未来”,将实时流处理带入了一个全新的阶段。这一演讲为读者展示了传统ETL架构的不足以及现代流处理技术的优势,为数据处理领域的未来指明了方向。
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论