

31 | 性能调优:手把手带你提升应用的执行性能

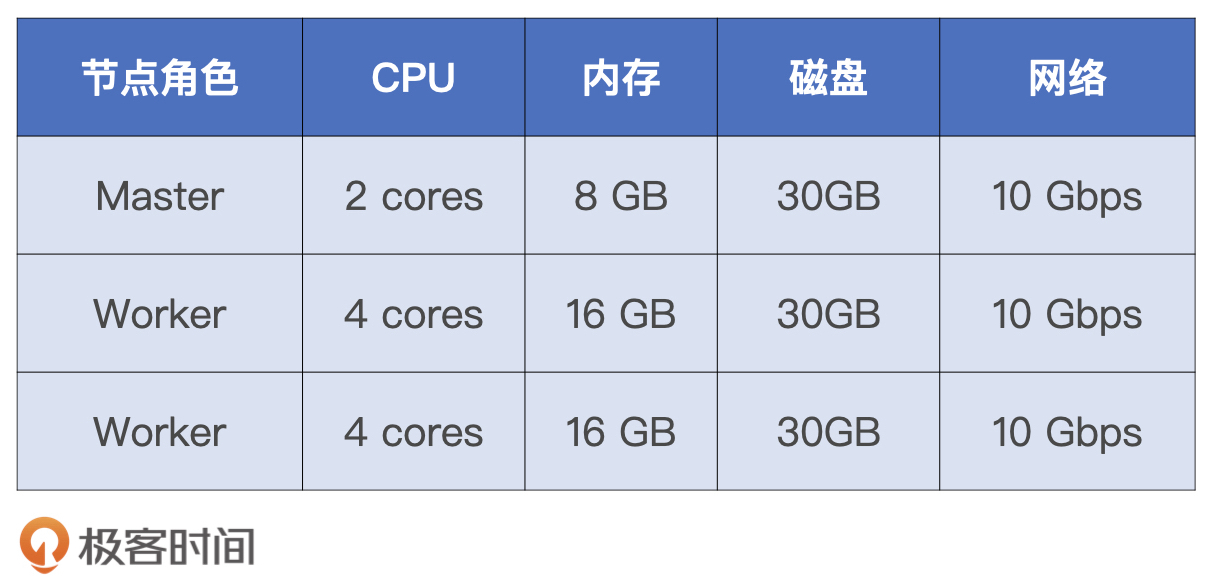
运行环境
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了通过性能调优来提升应用的执行性能,并以小汽车摇号趋势分析的应用开发为例,对5个案例进行了性能调优。作者详细介绍了每个案例的优化空间、可能的调优方法以及方法的效果。文章首先介绍了性能测试所采用的硬件资源和配置项设置,然后逐一分析了每个案例的代码实现和优化思路。在案例1中,作者通过对数据集的引用次数和运行成本占比进行分析,提出了利用Cache机制来提升执行性能的方法,并展示了调优后的性能提升效果。在案例2中,作者针对场景1的代码实现进行了详细分析,提出了常规操作、数据分区合并、加Cache等多种调优思路,并强调了在实际工作中应优先解决主要矛盾,再逐步应对次要问题的调优方法论。案例3中,作者重点关注了单表Shuffle的调优思路与技巧,以及广播变量优化数据关联的调优技巧。案例4则着重介绍了如何利用DPP机制来提升执行性能。通过案例5的性能调优,读者可以深入了解性能调优的实际操作和效果,为应用性能提升提供了有力的参考。整体而言,本文通过实际案例详细介绍了性能调优的方法和效果,对于需要提升应用执行性能的技术人员具有一定的参考价值。
《Spark 性能调优实战》,新⼈⾸单¥59

全部留言(8)
- 最新
- 精选
 Unknown element老师您好,问下 bypass 排序操作为什么要求计算逻辑不涉及聚合呢?reduceByKey 感觉也不需要排序啊。。
Unknown element老师您好,问下 bypass 排序操作为什么要求计算逻辑不涉及聚合呢?reduceByKey 感觉也不需要排序啊。。作者回复: 好问题,像reduceByKey这些操作,确实本身并不需要排序,但是,在Spark的实现里面,其实很多地方都需要排序,比如说,data文件和index文件的merge。bypass的要求,其实是不允许有map端的combine,简单理解,就是操作本身不能带Aggregate。 原因在于,如果操作有Aggregate的话,那么在实现层面,Spark会用AppendOnlyMap来缓存RDD分片中的数据,随着分片不断填充,AppendOnlyMap的内容会溢出,这些temp file最终会merge到一起,这些内容merge的话,其实sort merge是最经济实惠的。不管是data文件、还是index文件,都是这样。另外一个方面,就是复用sort shuffle manager的代码,提高代码复用率。
2022-01-249 斯盖丸老师,我看到很多hdfs源的spark job,它们task建议的大小是128M,也就是一个HDFS block的大小。请问咱们这边说的一个task最佳大小是200多M是怎么来的?
斯盖丸老师,我看到很多hdfs源的spark job,它们task建议的大小是128M,也就是一个HDFS block的大小。请问咱们这边说的一个task最佳大小是200多M是怎么来的?作者回复: 好问题,200M是无数次调优得来的经验值~ 128MB是HDFS的推荐大小,用在Spark的Task上,有些偏小了。
2021-05-3126 felicity老师你好,这里的例子是基于spark3.0的版本讲的,已经有了aqe,但是我们公司使用的spark版本还是2系列的,短时间内也不会升级到3,像aqe这种,2系列没有,能否讲解一下针对spark2版本的优化思路,谢谢
felicity老师你好,这里的例子是基于spark3.0的版本讲的,已经有了aqe,但是我们公司使用的spark版本还是2系列的,短时间内也不会升级到3,像aqe这种,2系列没有,能否讲解一下针对spark2版本的优化思路,谢谢作者回复: 版本是2.x的话,其实不妨关注下专栏中除了AQE的部分。因为3.x的话,其实主要AQE、DPP是亮点,把这两个拿掉,其余的优化手段和方法,都适用于2.x。更何况DPP本身坦白说还是有些鸡肋的,因此主要是AQE。 像大表关联小表、大表关联大表、内存利用率、CPU利用率,这些都是比较常规的调优手段。
2021-08-091- 边边爱学习磊哥,shuffle read blocked time 特别长,占据任务的70%以上的时间,应该尝试哪方面的优化呀
作者回复: shuffle read 时间长,可能只是个表象,至少有两种可能。一个是磁盘读取效率低,这个把spark.local.dir设置到SSD可能会有改善。另一个是,map端输出的就慢,也就是上个stage计算本身就慢,所以下一个stage的reduce task再去拉数据,就会“看上去”很慢。所以不妨看看上一个stage在干嘛,有哪些比较heavy的计算负载? 另外,这里面有没有失败重试,shuffle read过程中有没有频繁失败、然后又尝试,如果有的话,那就更复杂,就要看是哪些tasks失败,是不是有数据倾斜,等等。
2021-08-28 - 斯盖丸老师,请问数据分片200mb是最佳的,这个结论是如何得出的?因为我自己也试过几次发现确实如此,一旦分片数再大执行时间反而更慢。很好奇老师是怎么知道这个知识点的,我去stackoverflow上查过,没有什么收获
作者回复: 前面回复过了哈,无数次实战得到的经验值~
2021-05-31  淡C作为一个准大四的学生,一开始学习了spark基础之后,很荣幸遇到磊哥的两个spark专栏,这两个专栏让我对spark的理解有了全新的理解,起码让我在实习的时候可以正式员工battle,值得二刷,spark调优甚至值得三刷,争取二刷之后我也可以称自己为spark初学者了。2022-07-152
淡C作为一个准大四的学生,一开始学习了spark基础之后,很荣幸遇到磊哥的两个spark专栏,这两个专栏让我对spark的理解有了全新的理解,起码让我在实习的时候可以正式员工battle,值得二刷,spark调优甚至值得三刷,争取二刷之后我也可以称自己为spark初学者了。2022-07-152- 会飞的企鹅老师 我想问了:怎么评估spark所需的资源。需要多少cpu和mem?2022-05-19
 wayne老师,请问如何注册永久的pyspark pandas_udf,比如使用sparksql 都可以自动加载2022-03-201
wayne老师,请问如何注册永久的pyspark pandas_udf,比如使用sparksql 都可以自动加载2022-03-201

