

30|应用开发:北京市小客车(汽油车)摇号趋势分析

课前准备
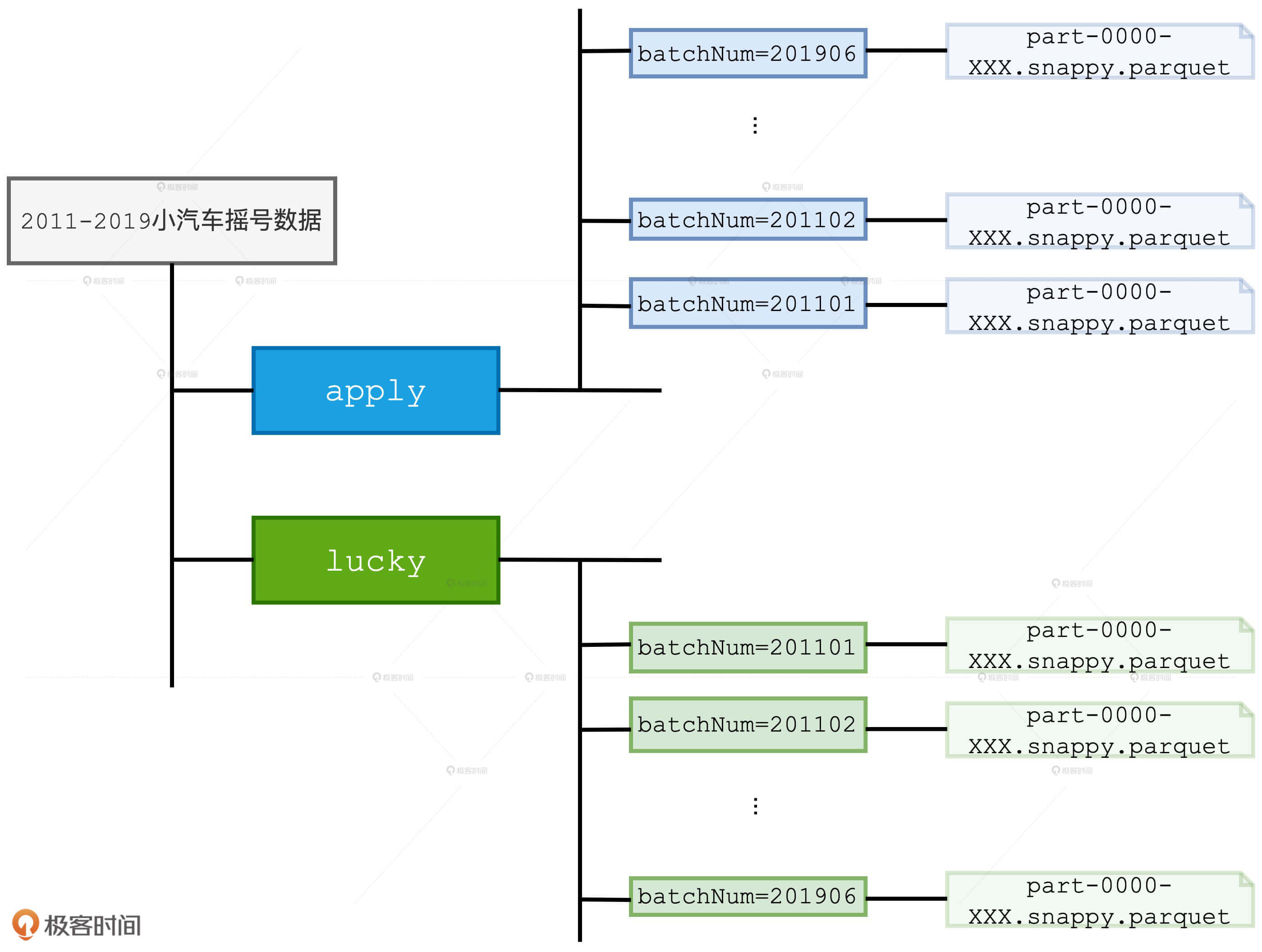
准备数据
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

北京小客车摇号一直备受关注,但为何如此艰难?本文作者吴磊分享了开发一个北京市小汽车摇号趋势分析应用的过程。文章通过技术分析,深刻揭示了北京小客车摇号的复杂性和难度,为读者提供了深入的技术视角和洞察。作者详细讲解了应用开发的过程,包括人数统计和摇号次数分布的案例分析。通过数据分析和代码实现,展示了申请者和中签者的分布情况,中签者的摇号次数越多,数量越少,以及中签率的变化趋势。文章通过技术分析,深刻揭示了北京小客车摇号的复杂性和难度,为读者提供了深入的技术视角和洞察。同时,对倍率分布情况和不同倍率人群的中签比例进行了观察。通过对摇号次数分布、中签率变化趋势、中签率的大变动、倍率分布与中签比例的分析,为读者提供了全面的了解和洞察。
《Spark 性能调优实战》,新⼈⾸单¥59

全部留言(6)
- 最新
- 精选
 猪猪吴磊老师好~ 默默学了老师的课程,哈哈这节课关注点完全在为啥我没中签了。关键还是我和老公两个8倍率摇号都不中,这大概只能怪人品了呢。。。 官方的倍数太简单粗暴了,我觉得可以考虑用指数方式进行放大摇号时间长的人的倍数。两个初步想法,应该还得更多考虑公平再加细化。 (1)倍率=EXP(LOG2(MAX(1,累计摇号期数-MagicNum))。 经初步计算,假设MagicNum为36,摇号71期的可以有1.1%的中签率;MagicNum为48,摇号71期的可以有3.3%的中签率;MagicNum为60,摇号71期的可以有3.8%的中签率。 (2)倍率=100.0*sigmoid(累计摇号期数-MagicNum)。其中sigmoid=1/(1+exp(-z))为常用的函数,它的取值范围(0,1)。 为了保证总参与摇号样本数不至于过多还可以考虑同比例缩小倍数等等。初步尝试添加一些权重换算后发现这两种方法都可以把摇号很久的概率提高到百分之几。 另外老师我想请问下,所有批次一起统计官方倍率下中签率会不会是幸存者偏差导致的正态分布,因为中签的后面批次就不参与摇号了。我统计每一批次官方倍数下中签率,除了13,12倍数据基数太小不满足统计规律外,整体中签率确实是倍数越高中签率越高的。但是其实高那么零点几百分比完全无效哈哈。我用sql把意思写在下面,希望老师指正。 批次 倍数 参与人数 中签人数 中签率 201906 13 47 0 0.000% 201906 12 81094 338 0.417% 201906 11 102792 436 0.424% 201906 10 142112 530 0.373% 201906 9 235860 789 0.335% 201906 8 248556 712 0.286% 201906 7 263499 677 0.257% 201906 6 378509 829 0.219% 201906 5 407661 746 0.183% 201906 4 381066 585 0.154% 201906 3 362343 391 0.108% 201906 2 359586 244 0.068% 201906 1 372312 107 0.029% # 1. 统计每一批次官方倍数下中签率 SELECT aa.batchnum, aa.times, count(*) all_num, count(bb.carnum) AS lucky_num, count(bb.carnum)/ count(*) AS ratio FROM (SELECT a.batchnum, a.carnum, count(*) AS times FROM apply a GROUP BY a.batchnum, a.carnum) aa LEFT JOIN lucky bb ON (aa.carnum = bb.carnum AND aa.batchnum = bb.batchnum) GROUP BY aa.batchnum, aa.times;
猪猪吴磊老师好~ 默默学了老师的课程,哈哈这节课关注点完全在为啥我没中签了。关键还是我和老公两个8倍率摇号都不中,这大概只能怪人品了呢。。。 官方的倍数太简单粗暴了,我觉得可以考虑用指数方式进行放大摇号时间长的人的倍数。两个初步想法,应该还得更多考虑公平再加细化。 (1)倍率=EXP(LOG2(MAX(1,累计摇号期数-MagicNum))。 经初步计算,假设MagicNum为36,摇号71期的可以有1.1%的中签率;MagicNum为48,摇号71期的可以有3.3%的中签率;MagicNum为60,摇号71期的可以有3.8%的中签率。 (2)倍率=100.0*sigmoid(累计摇号期数-MagicNum)。其中sigmoid=1/(1+exp(-z))为常用的函数,它的取值范围(0,1)。 为了保证总参与摇号样本数不至于过多还可以考虑同比例缩小倍数等等。初步尝试添加一些权重换算后发现这两种方法都可以把摇号很久的概率提高到百分之几。 另外老师我想请问下,所有批次一起统计官方倍率下中签率会不会是幸存者偏差导致的正态分布,因为中签的后面批次就不参与摇号了。我统计每一批次官方倍数下中签率,除了13,12倍数据基数太小不满足统计规律外,整体中签率确实是倍数越高中签率越高的。但是其实高那么零点几百分比完全无效哈哈。我用sql把意思写在下面,希望老师指正。 批次 倍数 参与人数 中签人数 中签率 201906 13 47 0 0.000% 201906 12 81094 338 0.417% 201906 11 102792 436 0.424% 201906 10 142112 530 0.373% 201906 9 235860 789 0.335% 201906 8 248556 712 0.286% 201906 7 263499 677 0.257% 201906 6 378509 829 0.219% 201906 5 407661 746 0.183% 201906 4 381066 585 0.154% 201906 3 362343 391 0.108% 201906 2 359586 244 0.068% 201906 1 372312 107 0.029% # 1. 统计每一批次官方倍数下中签率 SELECT aa.batchnum, aa.times, count(*) all_num, count(bb.carnum) AS lucky_num, count(bb.carnum)/ count(*) AS ratio FROM (SELECT a.batchnum, a.carnum, count(*) AS times FROM apply a GROUP BY a.batchnum, a.carnum) aa LEFT JOIN lucky bb ON (aa.carnum = bb.carnum AND aa.batchnum = bb.batchnum) GROUP BY aa.batchnum, aa.times;作者回复: 有道理!老弟考虑得甚是周到!!!棒👍! 首先,你提的两个倍率算法,我深表赞同,这比官方的简单粗暴合理多了~ 我觉得他们应该给你发offer,帮他忙去完善摇号系统~ 再者,关于不同倍率下的中签率统计,你是对的~ 我仔细想了想,确实忽略了这样一个细节:8倍概率摇中号码的人,他曾经也有过7倍、6倍。。。一直到1倍的倍率,所以不能单纯地去max。你说的对,幸存者偏差了,哈哈哈。感谢老弟的提醒~ 我让编辑把这个留言置顶下~ 老弟思考深入、条理清晰,赞~👍
2021-09-0326 斯盖丸倍率对于中签的贡献微乎其微十分反常识和直觉呀。。。难道是因为日期越近的人他们的隐藏权重也越高,所以和倍率抵消了么。。?
斯盖丸倍率对于中签的贡献微乎其微十分反常识和直觉呀。。。难道是因为日期越近的人他们的隐藏权重也越高,所以和倍率抵消了么。。?作者回复: 关于倍率,我琢磨可能是这么回事,根本原因是基础概率实在是太低了,所以其实乘以个3倍还是8倍已经不重要了,都被稀释掉了。 比如说,基础概率是千分之2,那么3倍的倍率就是千分之6,8倍的倍率就是百分之1.6。 不管是千分之6,还是1.6%,对于庞大的摇号基数来说,其实都可以忽略不计。10的负3次方,这个数量级太低了,而3和8又没有数量级上的差别,因此乘下来差别就微乎其微了。
2021-05-283 猿鸽君从倍率的实现方式来看,感觉就是设计者懒而已。简单的应该可以根据参与次数再计算一个倍率系数,而不是单纯的递增。
猿鸽君从倍率的实现方式来看,感觉就是设计者懒而已。简单的应该可以根据参与次数再计算一个倍率系数,而不是单纯的递增。作者回复: 哈哈,严重同意~
2021-08-262 快跑已经不关心spark了。完全沉浸在为什么我没摇中
快跑已经不关心spark了。完全沉浸在为什么我没摇中作者回复: 哈哈哈[Facepalm]
2021-05-271 Jefitar之前在阿里云买的服务器搭建的集群,太贵了,释放了,现在用台式机搞了64G内存,创建了4台虚拟机搭建了集群,晚上到家跑一下,想想怎么优化,然后再看下一章!😄
Jefitar之前在阿里云买的服务器搭建的集群,太贵了,释放了,现在用台式机搞了64G内存,创建了4台虚拟机搭建了集群,晚上到家跑一下,想想怎么优化,然后再看下一章!😄作者回复: 666~ 64GB内存足够了,哈哈~
2021-06-09- Jefitar买新能源汽车啊,哈哈哈哈
作者回复: 哈哈,有道理~
2021-06-09

