

18|Wide&Deep:怎样让你的模型既有想象力又有记忆力?

该思维导图由 AI 生成,仅供参考
Wide&Deep 模型的结构
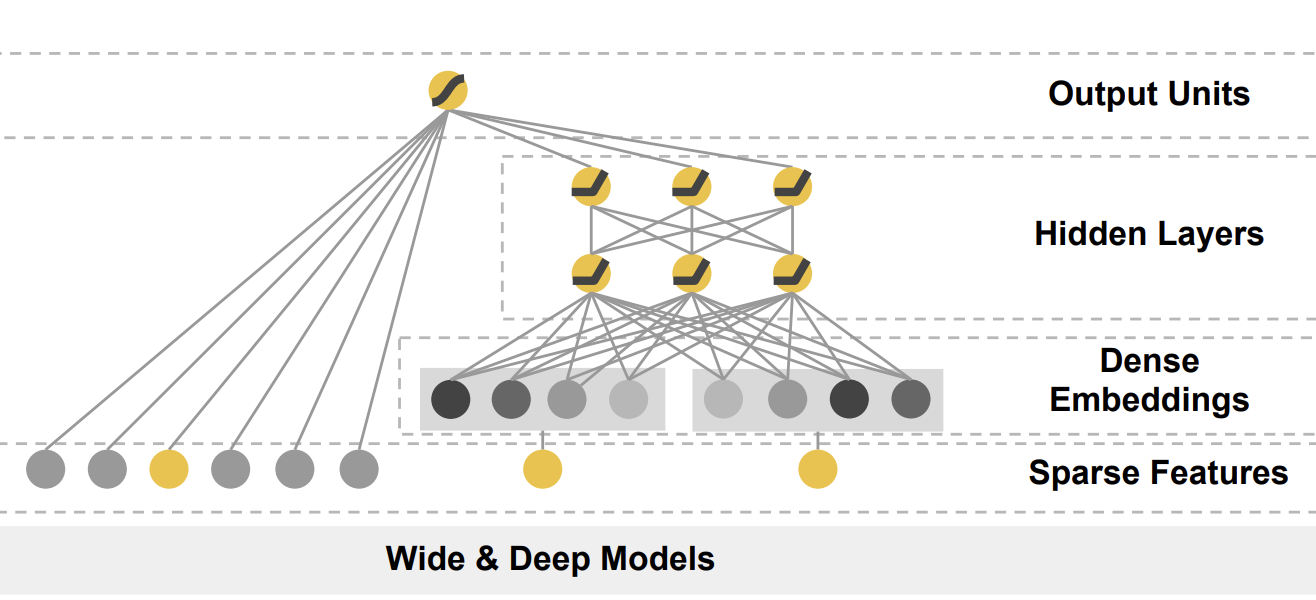
(出自Wide & Deep Learning for Recommender Systems )
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

Wide&Deep模型是Google推荐系统领域的重要模型,结合了“宽”和“深”的特点,旨在兼具“记忆能力”和“泛化能力”。文章介绍了Wide&Deep模型的结构和在Google Play应用推荐场景中的应用。Wide部分主要用于增强模型的“记忆能力”,通过学习历史数据中的共现频率来记住重要规则;而Deep部分则用于增强模型的“泛化能力”,对新鲜样本和未出现过的特征组合进行预测。文章还提供了Wide&Deep模型的TensorFlow实现代码,重点关注了模型的Deep部分和Wide部分的特征选择和构建。通过结合线性模型和深度网络,Wide&Deep模型实现了综合能力更强的推荐模型。整体而言,Wide&Deep模型以其独特的结构和应用场景,为推荐系统的发展提供了重要的思路和方法。
《深度学习推荐系统实战》,新⼈⾸单¥68

全部留言(27)
- 最新
- 精选
 giraffa126冒昧问一下,deep的输出是128,wide是10000,两个不在一个量纲,感觉直接这么concate,会不会削弱deep的效果,模型退化成LR?
giraffa126冒昧问一下,deep的输出是128,wide是10000,两个不在一个量纲,感觉直接这么concate,会不会削弱deep的效果,模型退化成LR?作者回复: 这是个很好的问题,也推荐其他同学思考。 我的思考是不会,因为wide部分一般来说都是非常稀疏的特征,虽然总的维度很大,但是在实际inference的过程中,wide部分往往只有几个维度是有值的,而deep部分一般都是稠密的特征向量,所以理论上两个部分对结果的影响不存在太大的bias。
2020-12-19344 Alan答:改进空间大致上我能想到两种方式:我选2 1、手动人工两个特征交叉或求解相关性(即,电影风格类型较低情况下,数据维度较低、数据量较小情况下是可以的,但是在实际工业应用领域是不切实际的), 2、改进算法的wide部分,提升记忆能力,使用端到端模型,减少人工操作。例如DCNMix、DeepFM。以DeepFM这个模型都可以很好学习到高低特征与交叉。(实际业界常用,推荐) 普及一下高低阶特征知识: 低阶特征:是指线性-线性组合,只能算一个有效的线性组合,线性-非线性-线性,这样算两个有效的线性组合,一般常说的低阶特征只有小于等于2阶; 高阶特征:说高阶特征,可以理解为经过多次线性-非线性组合操作之后形成的特征,为高度抽象特征,一般人脑很难解析出原有的特征了
Alan答:改进空间大致上我能想到两种方式:我选2 1、手动人工两个特征交叉或求解相关性(即,电影风格类型较低情况下,数据维度较低、数据量较小情况下是可以的,但是在实际工业应用领域是不切实际的), 2、改进算法的wide部分,提升记忆能力,使用端到端模型,减少人工操作。例如DCNMix、DeepFM。以DeepFM这个模型都可以很好学习到高低特征与交叉。(实际业界常用,推荐) 普及一下高低阶特征知识: 低阶特征:是指线性-线性组合,只能算一个有效的线性组合,线性-非线性-线性,这样算两个有效的线性组合,一般常说的低阶特征只有小于等于2阶; 高阶特征:说高阶特征,可以理解为经过多次线性-非线性组合操作之后形成的特征,为高度抽象特征,一般人脑很难解析出原有的特征了作者回复: 说的很好,推荐其他同学参考。
2021-03-1828 范闲电影本身风格和用户倾向风格可以做个融合~~用户偏离本身风格的程度~~
范闲电影本身风格和用户倾向风格可以做个融合~~用户偏离本身风格的程度~~作者回复: 很好的idea,人工的特征组合有时候反而效果是好的。不能因为有深度学习就完全不考虑一些手动的特征组合。
2020-12-0219 那时刻请问老师,文中例子中把类别型特征放入到wide里,如果把数值型特征放到wide部分,是否需要做normalization呢?
那时刻请问老师,文中例子中把类别型特征放入到wide里,如果把数值型特征放到wide部分,是否需要做normalization呢?作者回复: 做不做normalization还是看你自己的实践。我一般推荐在实际工作中做normalization或者bucketize。会有助于模型收敛。
2020-11-20216- 马龙流用户喜欢的风格和电影本身自己的风格,做attention做为一个值喂给mlp,这种做法是否可以
作者回复: 这个思路非常好。跟之后我们要讲的DIN中的attention机制做法一致了。
2020-11-2514  骚动请问老师,我觉得Wide&Deep和GBDT+LR在逻辑上很像,Wide对应LR,Deep对应GBDT,不知道我的想法对不对?这两个模型对比,老师能给我讲下吗,有什么共性?另外,GBDT+LR中输入LR的数据,也是原始特征+GBDT训练的特征,是否可以理解为原始特征就是模型的记忆能力,GBDT训练的组合特征就是泛化能力?
骚动请问老师,我觉得Wide&Deep和GBDT+LR在逻辑上很像,Wide对应LR,Deep对应GBDT,不知道我的想法对不对?这两个模型对比,老师能给我讲下吗,有什么共性?另外,GBDT+LR中输入LR的数据,也是原始特征+GBDT训练的特征,是否可以理解为原始特征就是模型的记忆能力,GBDT训练的组合特征就是泛化能力?作者回复: 不可以这样理解,wide&deep两部分是并列的,GBDT+LR,两部分是先后关系。 至于具体的区别,自己找GBDT+LR的结构去深入理解。
2021-01-1635- Geek_b027e7老师,deepfm中crossed_column是不是只写了一个好评电影的交叉例子,按文中意思是把所有好评过的历史电影与所有电影做交叉
作者回复: 是的,可以自己多修改,多尝试
2020-12-0625  江峰在工业界应用wide deep模型的时候,wide侧和deep侧分别应该放什么样的特征呢? 我在实践过程中都是把 原始id特征放到deep侧,把id类别大的,和其他id特征的交叉放在wide侧。比如adid和分词交叉,memberid和分词交叉等。这样处理合适吗? 把这种交叉特征同时放在wide侧和deep侧,是不是会更好?
江峰在工业界应用wide deep模型的时候,wide侧和deep侧分别应该放什么样的特征呢? 我在实践过程中都是把 原始id特征放到deep侧,把id类别大的,和其他id特征的交叉放在wide侧。比如adid和分词交叉,memberid和分词交叉等。这样处理合适吗? 把这种交叉特征同时放在wide侧和deep侧,是不是会更好?作者回复: 当然按照原文的思路,是把维度很高的交叉类特征放在wide侧,把比较稠密的特征放在deep侧,我们的实践也基本依次逻辑。 但是我觉得倒也没必要一成不变的按它的逻辑,你这种实践出真知的过程是最好的。
2021-02-2424 王继伟请问老师,文中说Wide 部分就是把输入层直接连接到输出层。 1、如果输入层特征特别稀疏(上千万维的one_hot)这样即使是直接连接到输出层也会增加上千万个参数,这样会降低模型训练速度吗? 2、如果Wide 部分输入的稀疏特征维度上亿,那wide部分的训练的参数会比deep部分训练的参数还要多,这样合理吗? 还是说wide部分的输入是要控制特征维度的?
王继伟请问老师,文中说Wide 部分就是把输入层直接连接到输出层。 1、如果输入层特征特别稀疏(上千万维的one_hot)这样即使是直接连接到输出层也会增加上千万个参数,这样会降低模型训练速度吗? 2、如果Wide 部分输入的稀疏特征维度上亿,那wide部分的训练的参数会比deep部分训练的参数还要多,这样合理吗? 还是说wide部分的输入是要控制特征维度的?作者回复: 这两个问题都不错: 1、其实深度模型一般都有处理稀疏id的部分,即使没有wide部分,大量其他模型的embedding也需要处理这样的特征。所以肯定会降低训练速度,但深度学习模型几乎都必须有这样的结构 2、虽然稀疏特征维度很大,但是往往仅有很少的几个维度在inference过程中是1。所以对结果的贡献不会淹没deep部分。这是从原理上说的,从实践上说的话,自己去做evaluation。
2021-02-134 Jacky老师,您好!我想咨询一下,我在pycharm里运行py文件的时候,出现了cast string to int32 is not supported的问题,想咨询一下如何修改代码。谢谢您!感谢!
Jacky老师,您好!我想咨询一下,我在pycharm里运行py文件的时候,出现了cast string to int32 is not supported的问题,想咨询一下如何修改代码。谢谢您!感谢!作者回复: 微信上已经回复你了吧?这些小问题自己多调试,可能不能一一帮助大家。
2021-01-2174