

37 | 数据分布优化:如何应对数据倾斜?
蒋德钧

该思维导图由 AI 生成,仅供参考
你好,我是蒋德钧。
在切片集群中,数据会按照一定的分布规则分散到不同的实例上保存。比如,在使用 Redis Cluster 或 Codis 时,数据都会先按照 CRC 算法的计算值对 Slot(逻辑槽)取模,同时,所有的 Slot 又会由运维管理员分配到不同的实例上。这样,数据就被保存到相应的实例上了。
虽然这种方法实现起来比较简单,但是很容易导致一个问题:数据倾斜。
数据倾斜有两类。
数据量倾斜:在某些情况下,实例上的数据分布不均衡,某个实例上的数据特别多。
数据访问倾斜:虽然每个集群实例上的数据量相差不大,但是某个实例上的数据是热点数据,被访问得非常频繁。
如果发生了数据倾斜,那么保存了大量数据,或者是保存了热点数据的实例的处理压力就会增大,速度变慢,甚至还可能会引起这个实例的内存资源耗尽,从而崩溃。这是我们在应用切片集群时要避免的。
今天这节课,我就来和你聊聊,这两种数据倾斜是怎么发生的,我们又该怎么应对。
数据量倾斜的成因和应对方法
首先,我们来看数据量倾斜的成因和应对方案。
当数据量倾斜发生时,数据在切片集群的多个实例上分布不均衡,大量数据集中到了一个或几个实例上,如下图所示:
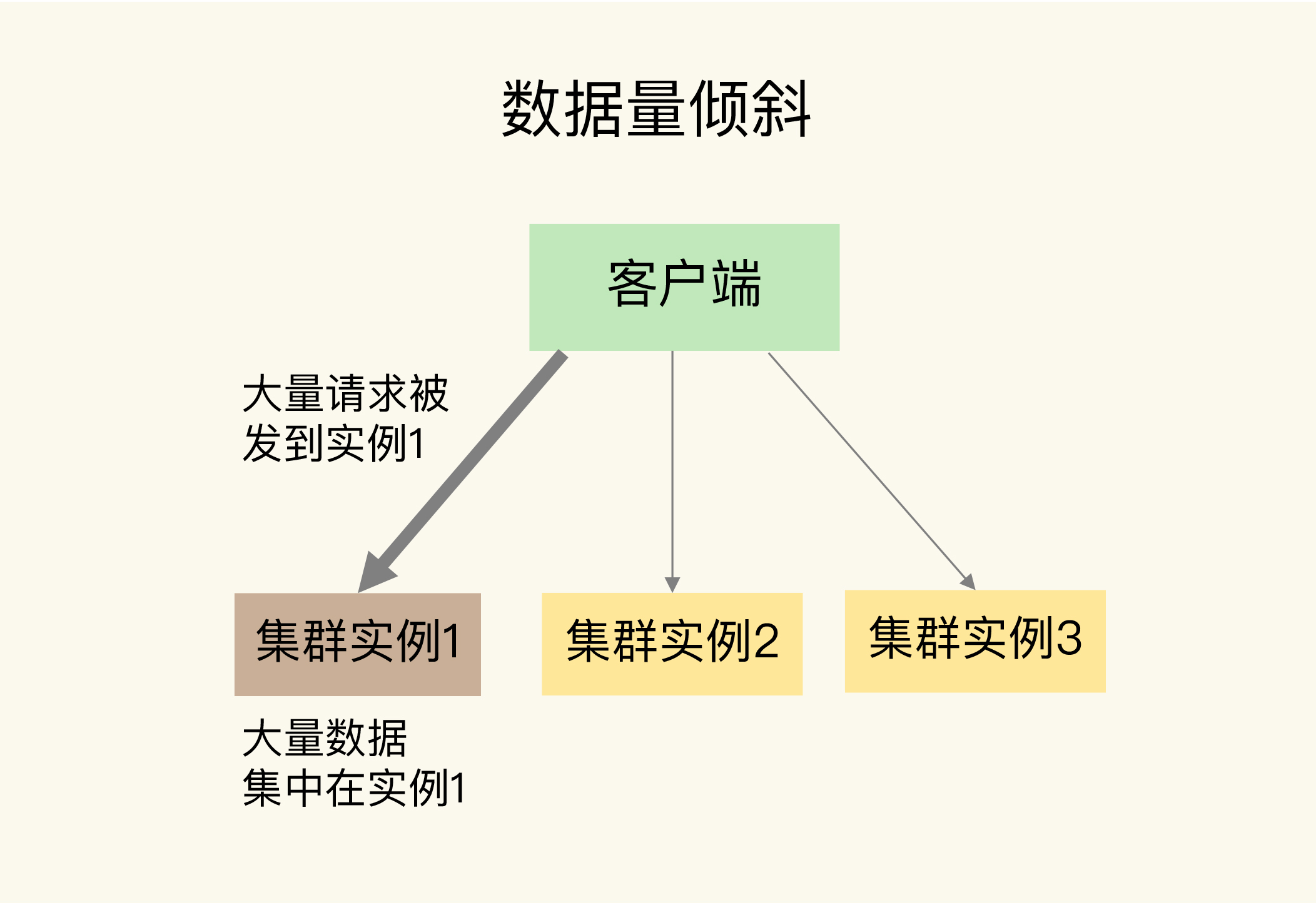
那么,数据量倾斜是怎么产生的呢?这主要有三个原因,分别是某个实例上保存了 bigkey、Slot 分配不均衡以及 Hash Tag。接下来,我们就一个一个来分析,同时我还会给你讲解相应的解决方案。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

数据分布优化是切片集群中的重要问题,本文介绍了数据倾斜的成因和应对方法。数据倾斜主要包括数据量倾斜和数据访问倾斜两种情况。数据量倾斜可能由bigkey、Slot分配不均衡以及Hash Tag等原因导致。针对bigkey导致的倾斜,建议在业务层生成数据时避免将过多数据保存在同一个键值对中,或者将bigkey拆分成小的集合类型数据分散保存在不同实例上。对于Slot分配不均衡导致的倾斜,需要避免过多Slot分配到同一个实例,可以通过迁移命令将部分Slot迁移到其他实例上来避免数据倾斜。此外,文章还介绍了在Redis Cluster和Codis中查看和迁移Slot的具体操作方法。通过本文的总结,读者可以了解数据倾斜的成因及相应的解决方案,为优化数据分布提供了有益的参考。 文章还介绍了Hash Tag导致的数据倾斜问题,以及在Redis Cluster和Codis中使用Hash Tag的场景和潜在问题。针对数据访问倾斜的问题,文章提出了采用热点数据多副本的方法来应对,以及针对有读有写的热点数据需要增加实例资源的建议。最后,文章总结了数据倾斜的原因和应对方法,并提供了关于实例资源配置的小建议。 总的来说,本文通过详细介绍数据倾斜的成因和解决方法,为读者提供了全面的数据分布优化方案,使其能够更好地应对切片集群中可能出现的数据倾斜问题。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《Redis 核心技术与实战》,新⼈⾸单¥68
《Redis 核心技术与实战》,新⼈⾸单¥68
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(32)
- 最新
- 精选
- xuanyuan赞,很多设计思想可以和mysql对比着看,收获颇丰
作者回复: 是的,如果能和其他系统对比起来学习,一般会有更多收获。这是个好方法。
2020-12-098 
 Kaito在有数据访问倾斜时,如果热点数据突然过期了,而 Redis 中的数据是缓存,数据的最终值保存在后端数据库,此时会发生什么问题? 此时会发生缓存击穿,热点请求会直接打到后端数据库上,数据库的压力剧增,可能会压垮数据库。 Redis 的很多性能问题,例如导致 Redis 阻塞的场景:bigkey、集中过期、大实例 RDB 等等,这些场景都与数据倾斜类似,都是因为数据集中、处理逻辑集中导致的耗时变长。其解决思路也类似,都是把集中变分散,例如 bigkey 拆分为小 key、单个大实例拆分为切片集群等。 从软件架构演进过程来看,从单机到分布式,再到后来出现的消息队列、负载均衡等技术,也都是为了将请求压力分散开,避免数据集中、请求集中的问题,这样既可以让系统承载更大的请求量,同时还保证了系统的稳定性。2020-11-165200
Kaito在有数据访问倾斜时,如果热点数据突然过期了,而 Redis 中的数据是缓存,数据的最终值保存在后端数据库,此时会发生什么问题? 此时会发生缓存击穿,热点请求会直接打到后端数据库上,数据库的压力剧增,可能会压垮数据库。 Redis 的很多性能问题,例如导致 Redis 阻塞的场景:bigkey、集中过期、大实例 RDB 等等,这些场景都与数据倾斜类似,都是因为数据集中、处理逻辑集中导致的耗时变长。其解决思路也类似,都是把集中变分散,例如 bigkey 拆分为小 key、单个大实例拆分为切片集群等。 从软件架构演进过程来看,从单机到分布式,再到后来出现的消息队列、负载均衡等技术,也都是为了将请求压力分散开,避免数据集中、请求集中的问题,这样既可以让系统承载更大的请求量,同时还保证了系统的稳定性。2020-11-165200 Summer 空城我们把热点数据复制多份,在每一个数据副本的 key 中增加一个随机前缀,让它和其它副本数据不会被映射到同一个 Slot 中。 这样做了以后怎么查呢?key前边加了随机数,客户端也不知道用啥key去查数据了2020-11-271716
Summer 空城我们把热点数据复制多份,在每一个数据副本的 key 中增加一个随机前缀,让它和其它副本数据不会被映射到同一个 Slot 中。 这样做了以后怎么查呢?key前边加了随机数,客户端也不知道用啥key去查数据了2020-11-271716 nxcat终于追上了,期待课代表的留言!课后问题我理解的话,只读模式下会发生缓存击穿,严重的话还可能造成雪崩。2020-11-1610
nxcat终于追上了,期待课代表的留言!课后问题我理解的话,只读模式下会发生缓存击穿,严重的话还可能造成雪崩。2020-11-1610- 静感觉后面干货越来越少了,前几篇,一篇一看就是一晚上,后面一晚上看8,9篇,还是我变强了呢?2021-09-2625
 Sam Fu不过业界中解决热key的话一般不采用hotkey+随机数的方式吧。毕竟如果集群实例个数特别多的话,删除hotkey的话成本有点大。 查看网上资料说解决热key更多的采用是将热点key加入到二级缓存(如JVM缓存) 不知道对不对?2021-02-1335
Sam Fu不过业界中解决热key的话一般不采用hotkey+随机数的方式吧。毕竟如果集群实例个数特别多的话,删除hotkey的话成本有点大。 查看网上资料说解决热key更多的采用是将热点key加入到二级缓存(如JVM缓存) 不知道对不对?2021-02-1335 Lemon课后题:将发生缓存击穿,导致数据库压力激增,可能导致数据库奔溃。与之相对的解决方法是不设置热点 Key 的过期时间,并以采用热点数据多副本的方法减少单实例压力。 疑问:老师您好,热点数据多副本的方法使得每一个数据副本的 key 都有一个随机前缀,那么客户端在读取的时候怎么获取这个随机前缀?又怎么保证带上随机前缀后的热点 Key 会被较为均匀的请求呢?2020-11-1763
Lemon课后题:将发生缓存击穿,导致数据库压力激增,可能导致数据库奔溃。与之相对的解决方法是不设置热点 Key 的过期时间,并以采用热点数据多副本的方法减少单实例压力。 疑问:老师您好,热点数据多副本的方法使得每一个数据副本的 key 都有一个随机前缀,那么客户端在读取的时候怎么获取这个随机前缀?又怎么保证带上随机前缀后的热点 Key 会被较为均匀的请求呢?2020-11-1763 InfoQ_小汤针对流量倾斜问题,对key作切分 理论上其实很简单 但是联合业务实践上挺复杂的,某个key一开始是非热点数据状态的,需要有监控redis key的工具,需要有相关自动切分或者人工干预切分的行为,切分以后业务端查询也需要同步被告知切分的规则,否则业务查询时候无法获取正确的key,切换的过程中新key与旧key需要同时存在一小段时间,否则肯能存在读旧key的请求异常。目前唯一能想到的是通过zookeeper这种配置中心去协调(watch机制),但是大量读会给zookeeper带来比较大的压力。增加二级缓存又会有数据延迟的情况,真的不清楚实际上业务是如何实现这种联动的。2021-11-262
InfoQ_小汤针对流量倾斜问题,对key作切分 理论上其实很简单 但是联合业务实践上挺复杂的,某个key一开始是非热点数据状态的,需要有监控redis key的工具,需要有相关自动切分或者人工干预切分的行为,切分以后业务端查询也需要同步被告知切分的规则,否则业务查询时候无法获取正确的key,切换的过程中新key与旧key需要同时存在一小段时间,否则肯能存在读旧key的请求异常。目前唯一能想到的是通过zookeeper这种配置中心去协调(watch机制),但是大量读会给zookeeper带来比较大的压力。增加二级缓存又会有数据延迟的情况,真的不清楚实际上业务是如何实现这种联动的。2021-11-262- dfuru缓存击穿2020-11-262
 云海热点多副本方案的使用:客户端请求时带上客户端标记即可,不同的客户端请求就会hash分散到不同的热点副本。2020-11-192
云海热点多副本方案的使用:客户端请求时带上客户端标记即可,不同的客户端请求就会hash分散到不同的热点副本。2020-11-192
收起评论

