

开篇词 | 这样学Redis,才能技高一筹

该思维导图由 AI 生成,仅供参考
为什么懂得了一个个技术点,却依然用不好 Redis?
课程是如何设计的?

 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

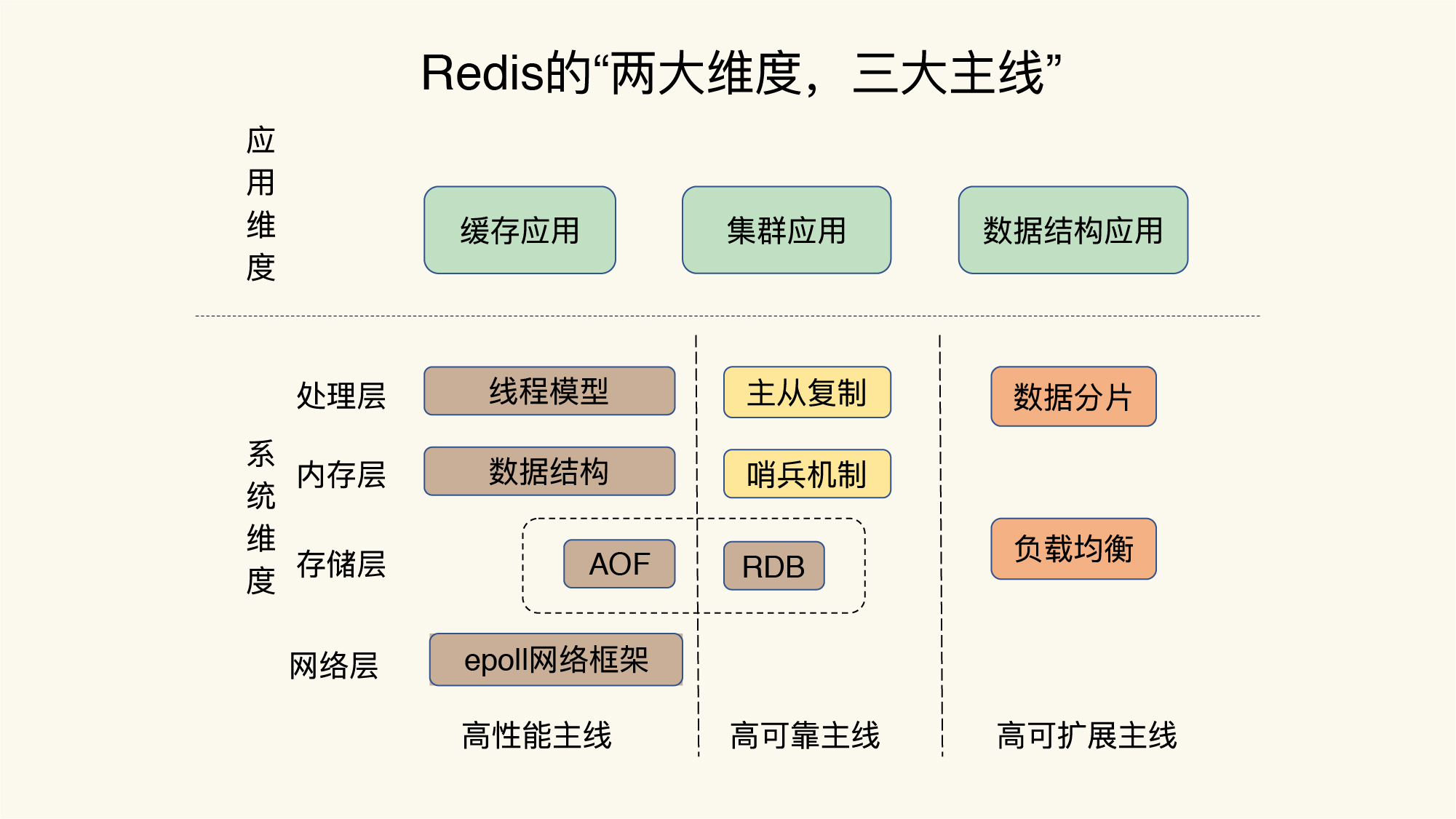
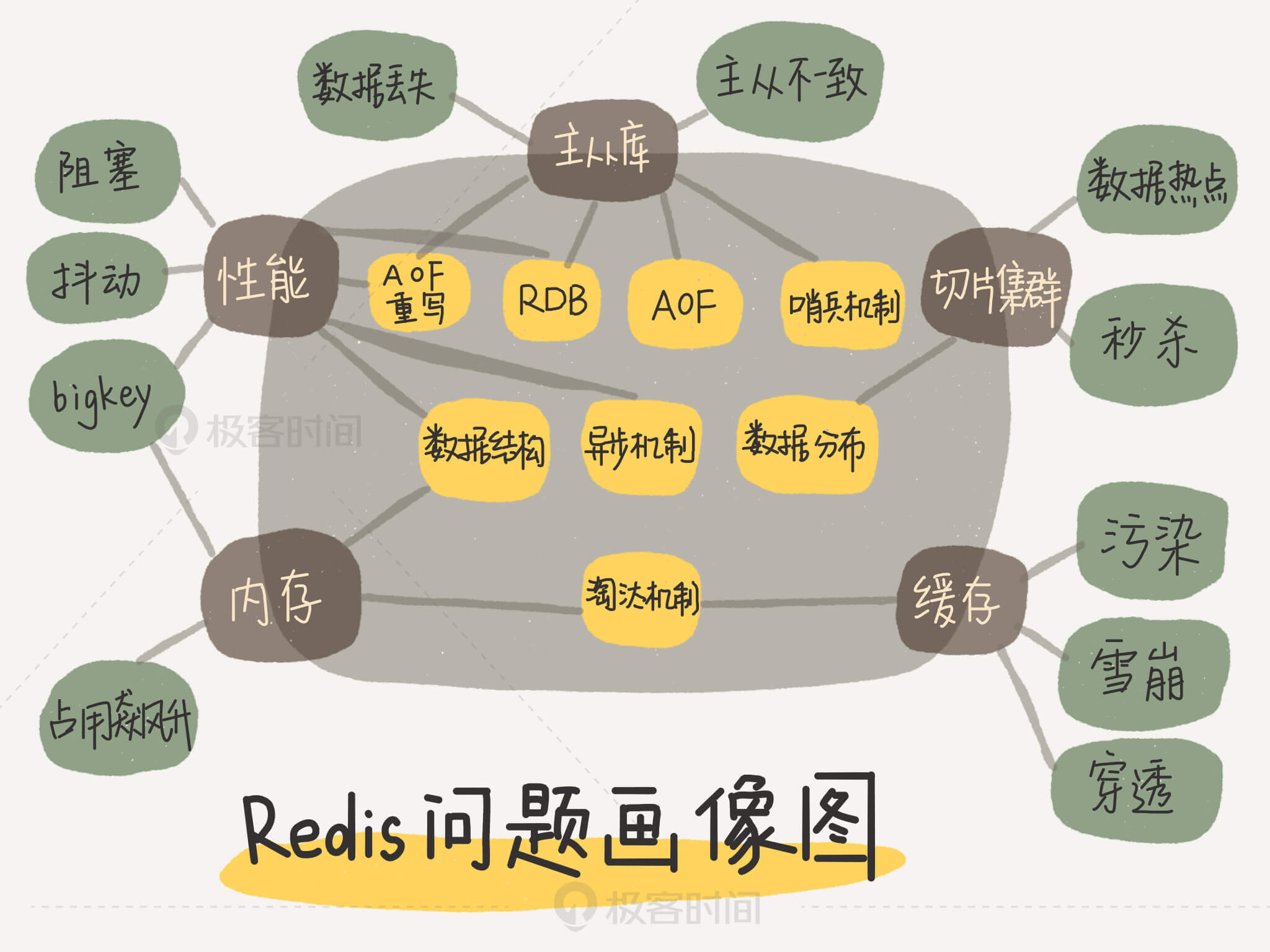
这篇文章以“为什么懂得了一个个技术点,却依然用不好Redis?”为题,由中科院计算所副研究员蒋德钧撰写,分享了他在Redis领域的研究和实践经验。作者深入研究了Redis的源代码、架构设计和核心控制点,并与蚂蚁金服、百度、华为、中兴等公司合作解决生产环境中的各种问题。他还提到了团队研发的高性能键值数据库。在文章的后半部分,作者总结了在实践中遇到的一些技术难题,包括CPU使用、内存使用、存储持久化和网络通信方面的挑战。文章强调了建立完整的知识框架和系统观的重要性,提出了“两大维度,三大主线”的Redis知识全景图,并分享了如何高效地形成系统观的方法。作者还介绍了一张Redis的问题画像图,帮助读者快速定位和解决问题。整体而言,这篇文章涵盖了作者在Redis领域的丰富经验和深入研究成果,对于想要深入了解Redis技术特点和解决实际问题的读者来说,具有很高的参考价值。
2020-08-03840人觉得很赞给文章提建议
《Redis 核心技术与实战》,新⼈⾸单¥68

全部留言(148)
- 最新
- 精选
 小盖置顶给这个我们打磨了两年的专栏留个印记吧,就像我们编辑说的,希望这不只是一个课程,而且还是一个作品,我们要精益求精,追求卓越。 这不,昨天一上线,我们就发现课程配图虽然够用,但不精致。于是,我们的编辑同学就连夜赶工做了替换。 上周刚做完Java工程师方面的招聘调研,我可以确定地说,绝大多数的一线公司在面试后端岗位时,都会问到Redis相关的问题(RPC、缓存、MQ三驾马车)。咱们就从今天开始,和蒋老师,一起学Redis吧。2020-08-0413372
小盖置顶给这个我们打磨了两年的专栏留个印记吧,就像我们编辑说的,希望这不只是一个课程,而且还是一个作品,我们要精益求精,追求卓越。 这不,昨天一上线,我们就发现课程配图虽然够用,但不精致。于是,我们的编辑同学就连夜赶工做了替换。 上周刚做完Java工程师方面的招聘调研,我可以确定地说,绝大多数的一线公司在面试后端岗位时,都会问到Redis相关的问题(RPC、缓存、MQ三驾马车)。咱们就从今天开始,和蒋老师,一起学Redis吧。2020-08-0413372- Geek_48707a请问一下老师,Redis中sorted set 底层实现是一个dict + 一个zskiplist, Redis底层为什么要如此设计。zadd key score value 这样的形式,那如果底层采用了跳表的数据结构zset到底是如何存储数据的呢?dict中存储的是什么,跳表中存储的又是什么呢
作者回复: 这个问题非常好,对sorted set的底层实现,观察很仔细。 我们一般用sorted set时,会经常根据集合元素的分数进行范围查询,例如ZRANGEBYSCORE或者ZREVRANGEBYSCORE,这些操作基于跳表就可以实现O(logN)的复杂度。此时,跳表的每个节点同时保存了元素值和它的score。感兴趣可以进一步看下,redis源码的server.h中的zskiplistNode结构体。 然后,就是你说的为什么还设计dict。不知道你有没有注意到,sorted set 还有ZSCORE这样的操作,而且它的操作复杂度为O(1)。如果只有跳表,这个是做不到O(1)的,之所以可以做到O(1),就是因为还用了dict,里面存储的key是sorted set的member,value就是这个member的score。
2020-08-04860  闫攀课程最后会梳理怎么更高效的读redis源码吗, 希望可以得到作者的回复
闫攀课程最后会梳理怎么更高效的读redis源码吗, 希望可以得到作者的回复作者回复: 了解源码的确会有很好的帮助,后续会综合大家的整体需求,可能会加个餐,来聊聊源码的阅读
2020-08-03538- Geek_224f63蒋老师你好,不知道研发hikv的背景是什么呢?难道redis都不能满足这个需求吗?
作者回复: HiKV的研发驱动力主要有两方面:一个是希望键值数据库对单点操作,例如PUT/GET,以及对范围操作都能高效支持,Redis的全局组织结构是个哈希表,所以对范围操作支持不高效,例如KEYS操作。 另一个考虑是,大容量非易失内存的出现,使得键值数据库的容量可以更大,但Redis并没有支持非易失内存,或者说内存键值数据库应该如何使用非易失内存,这是要做设计考虑的。 欢迎交流讨论。
2020-08-031029  张晗_Jeremy第一个沙发,收到通知就买了。gogogo!
张晗_Jeremy第一个沙发,收到通知就买了。gogogo!作者回复: 第一个赞就给你了!:)
2020-08-0319- Geek_75d94a两张图给我很深的启发,很好的归纳零散的知识点,让我想尝试用在其他地方建立一下知识体系。
作者回复: 加油!加油!
2020-08-06317  奕如果使用非易失内存 NVM, 这样设计出来的 高性能的健值数据库 是不是就对硬件的依赖就很大了?
奕如果使用非易失内存 NVM, 这样设计出来的 高性能的健值数据库 是不是就对硬件的依赖就很大了?作者回复: Intel去年4月份已经面向市场推出AEP产品了,现在咱们个人也都能买得到,当然主板和CPU还需要做些支持,需要一定型号才行 不过,业界很多大厂更早些时候也在实践NVM。所以这个趋势我觉得是会比较确定的。就像现在SSD应用的很广泛,我们使用也不太会觉得有依赖性,因为使用比较普遍了。我觉得以后NVM也是类似的。
2020-08-03416 型火🔥两大维度和三大主线的系统方法论可以迁移到大部分的中间件体系学习中
型火🔥两大维度和三大主线的系统方法论可以迁移到大部分的中间件体系学习中作者回复: 方法论很重要 :)
2020-08-1312 💕您好,还有就是你说的redis技术,存储数据。是不是说就不用数据库了比如mysql sql server等,直接用redis当数据库了呢?
💕您好,还有就是你说的redis技术,存储数据。是不是说就不用数据库了比如mysql sql server等,直接用redis当数据库了呢?作者回复: Redis是可以直接作为键值数据库,保存的数据一般为key-value这样的数据。 而你说到的mysql,SQL Server是关系型数据库,保存的数据有关系模型。 这两类数据库在支持的数据模型、增删改查操作、事务支持等方面都有差别,所以有了Redis,并不能取代MySQL这类数据库的。
2020-08-1827 与路同飞老师说的以这种问题画像图这种学习方式挺好的,用什么技术点解决什么场景问题,自己在以后学习也要善于用这种方式去归纳总结,不至于学了不会用
与路同飞老师说的以这种问题画像图这种学习方式挺好的,用什么技术点解决什么场景问题,自己在以后学习也要善于用这种方式去归纳总结,不至于学了不会用作者回复: 掌握方法很重要:)
2020-08-0327

