

04 | 特征工程:推荐系统有哪些可供利用的特征?

该思维导图由 AI 生成,仅供参考
什么是特征工程
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

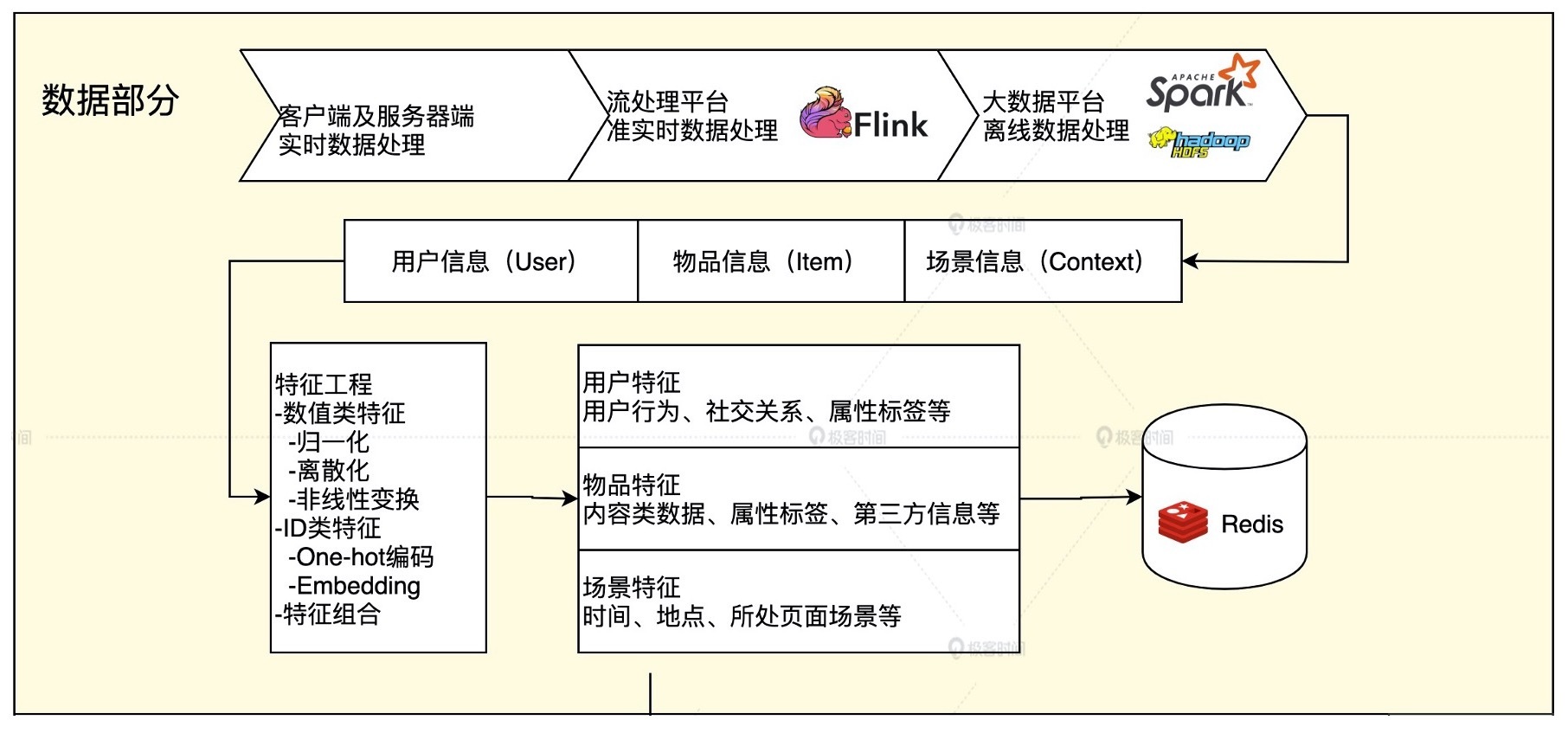
推荐系统特征工程是推荐系统中至关重要的一环。本文详细介绍了特征工程的定义、原则和常用特征。特征工程是从用户信息、物品信息和场景信息中提取特征的过程,是推荐系统的关键环节。构建推荐系统特征工程的原则是尽可能保留有用信息,摒弃冗余信息。文章列举了推荐系统中常用的特征,包括用户行为数据和用户关系数据等五大类特征。特别强调了隐性反馈行为在特征挖掘中的重要性。总的来说,本文通过理论和实际案例,为读者系统地介绍了推荐系统特征工程的基本原则和常用特征,对于深入理解和应用推荐系统具有重要的指导意义。文章还提到了属性标签、内容数据和场景信息等特征来源,以及它们在推荐系统中的处理方法。特征工程的重要性就像准备食材一样,直接影响到推荐系统的效果。读者可以通过本文了解特征工程的基本原则和常用特征,以及在实际应用中的重要性,为推荐系统的设计和优化提供指导。
《深度学习推荐系统实战》,新⼈⾸单¥68

全部留言(48)
- 最新
- 精选
 朱月俊选择音乐,哪些因素是我关注的? 我经常会听五类歌曲: 1.听网络流行歌曲(听大家听的); 2.听一些我喜欢的风格的歌曲(励志类,空灵类,感伤类); 3.听一些我喜欢的歌手唱的歌,比如汪峰等; 4.听我看过的电视剧,电影,动漫中的背景音乐; 5.听一些朋友推荐的歌曲; 如果我是音乐app特征提取工程师的话,我会提取哪些特征? 首先将特征分为文中提及的五类吧。 1.用户行为数据 用户在音乐app上的行为,包括浏览,收藏,评论,点击,播放,时长,次数等。 2.用户关系数据 用户的关系数据。 3.属性,标签类数据 歌曲的多维特征,用户的多维特征。 4.内容类数据 对音乐进行语音识别,提取关键特征。 5.场景信息(上下文信息) 跟小作文几要素差不多。 时间,地点,人物,情节。
朱月俊选择音乐,哪些因素是我关注的? 我经常会听五类歌曲: 1.听网络流行歌曲(听大家听的); 2.听一些我喜欢的风格的歌曲(励志类,空灵类,感伤类); 3.听一些我喜欢的歌手唱的歌,比如汪峰等; 4.听我看过的电视剧,电影,动漫中的背景音乐; 5.听一些朋友推荐的歌曲; 如果我是音乐app特征提取工程师的话,我会提取哪些特征? 首先将特征分为文中提及的五类吧。 1.用户行为数据 用户在音乐app上的行为,包括浏览,收藏,评论,点击,播放,时长,次数等。 2.用户关系数据 用户的关系数据。 3.属性,标签类数据 歌曲的多维特征,用户的多维特征。 4.内容类数据 对音乐进行语音识别,提取关键特征。 5.场景信息(上下文信息) 跟小作文几要素差不多。 时间,地点,人物,情节。作者回复: 非常好和全面,赞一个。
2020-10-103105 张弛 Conor我在选歌的时候,信息重要性从高到低依次是: 1.听歌的目的。比如是为了放松,冥想,学习还是运动。目的决定了歌曲是安静还是激昂,舒缓还是节奏感强烈。 2.歌曲或歌单是否受欢迎。定下基调后,我一般会选择收藏或播放量较多的歌曲。这样一般不容易采坑。 3.歌曲的旋律与当下状态的匹配度。当下的状态可能是心情,情绪或身体的疲劳程度,而旋律与状态的匹配也很重要。 如果我是一名音乐 APP 工程师, 1.用户听歌的目的很难准确预测,但是可以通过“隐性”数据去推测,比如搜索关键词等。 2.歌曲或歌单是否受欢迎,则可以通过歌曲或歌单的播放量、收藏量去建立特征,而具体到人和歌曲的关系时,还可以进一步具体到单曲循环的次数等来细化特定用户对特定歌曲的喜好程度。 3.当下的状态也很难显性的获得,则可以根据历史听歌记录去推测用户的生理节律,例如夜晚会愿意听舒缓的歌曲,运动会愿意听节奏感强烈的歌曲等等。
张弛 Conor我在选歌的时候,信息重要性从高到低依次是: 1.听歌的目的。比如是为了放松,冥想,学习还是运动。目的决定了歌曲是安静还是激昂,舒缓还是节奏感强烈。 2.歌曲或歌单是否受欢迎。定下基调后,我一般会选择收藏或播放量较多的歌曲。这样一般不容易采坑。 3.歌曲的旋律与当下状态的匹配度。当下的状态可能是心情,情绪或身体的疲劳程度,而旋律与状态的匹配也很重要。 如果我是一名音乐 APP 工程师, 1.用户听歌的目的很难准确预测,但是可以通过“隐性”数据去推测,比如搜索关键词等。 2.歌曲或歌单是否受欢迎,则可以通过歌曲或歌单的播放量、收藏量去建立特征,而具体到人和歌曲的关系时,还可以进一步具体到单曲循环的次数等来细化特定用户对特定歌曲的喜好程度。 3.当下的状态也很难显性的获得,则可以根据历史听歌记录去推测用户的生理节律,例如夜晚会愿意听舒缓的歌曲,运动会愿意听节奏感强烈的歌曲等等。作者回复: 非常好的答案,比我之前看到的答案还细致一些。能够完全从用户角度考虑,然后反映到工程实践上。
2020-10-12243 逆流向善的阿鱼音乐App 1.影响我做决定的关键信息: A. 个人主观角度 a.不同时间段【起床刷牙、工作时间、跑步时间、洗漱时间、睡前时间】 喜欢的类型不同 b.地理位置【寝室、办公室、室外、健身房】, 对应不同的状态 c. 心情/ 情绪状态 【 不同情绪状态 会 持续 听 不同类型 的歌曲】 B. 客观角度 a. 最近热议的 新歌 【流行度】 b. 最近热议的电影 的主题曲 【流行度】 c. 朋友最近在听的歌曲【用户关系】 d. 热门歌曲【我自己个人对这类歌曲喜好度偏低】 e. 所在地区大部分人都喜欢的歌曲 作为音乐App工程师的角度的特征 A. 易被工程化: a. 不同时间段 喜欢的 音乐 b. 不同地理位置 喜欢的音乐 c. 热门歌曲【当地热门,全球热门,中国地区热门】 e. 基于社交网络的歌曲推荐【基于用户的协同过滤、基于好友关系的推荐】 B. 不易被工程化: 心情/情绪【或许可以尝试短期内在听歌曲类型去提取?】 特征方面: 用户交互特征: 点击、收藏、点赞、踩、评分、评论【好/坏】、转发、播放完成度、浏览评论时长 用户属性特征:年龄、性别、职业、收入范围、所在地区、地理位置、不同时间段对各音乐类型的偏好度、不同地理位置对音乐类型的偏好度 用户关系特征:好友关系、亲密好友关系、有相同爱好的人群【基于用户协同过滤top K得出】 场景特征:用户当前所处位置、用户当前状态【用户自行设置?】、当前时间段、是否工作日、是否周末、是否节假日、 音乐特征:是否优质音乐【评分】、音乐风格、音乐时长、歌手、专辑、发行年月、所属标签、流行度、被重复播放的中位数 思考: 特征的更新频率: 用户:分为长中短期用户画像、仅保存三个月内活跃过的用户的画像以减少存储? 音乐:流行度需要按日期更新、热门程度也可能需要跟节假日相关【圣诞节=》圣诞结】
逆流向善的阿鱼音乐App 1.影响我做决定的关键信息: A. 个人主观角度 a.不同时间段【起床刷牙、工作时间、跑步时间、洗漱时间、睡前时间】 喜欢的类型不同 b.地理位置【寝室、办公室、室外、健身房】, 对应不同的状态 c. 心情/ 情绪状态 【 不同情绪状态 会 持续 听 不同类型 的歌曲】 B. 客观角度 a. 最近热议的 新歌 【流行度】 b. 最近热议的电影 的主题曲 【流行度】 c. 朋友最近在听的歌曲【用户关系】 d. 热门歌曲【我自己个人对这类歌曲喜好度偏低】 e. 所在地区大部分人都喜欢的歌曲 作为音乐App工程师的角度的特征 A. 易被工程化: a. 不同时间段 喜欢的 音乐 b. 不同地理位置 喜欢的音乐 c. 热门歌曲【当地热门,全球热门,中国地区热门】 e. 基于社交网络的歌曲推荐【基于用户的协同过滤、基于好友关系的推荐】 B. 不易被工程化: 心情/情绪【或许可以尝试短期内在听歌曲类型去提取?】 特征方面: 用户交互特征: 点击、收藏、点赞、踩、评分、评论【好/坏】、转发、播放完成度、浏览评论时长 用户属性特征:年龄、性别、职业、收入范围、所在地区、地理位置、不同时间段对各音乐类型的偏好度、不同地理位置对音乐类型的偏好度 用户关系特征:好友关系、亲密好友关系、有相同爱好的人群【基于用户协同过滤top K得出】 场景特征:用户当前所处位置、用户当前状态【用户自行设置?】、当前时间段、是否工作日、是否周末、是否节假日、 音乐特征:是否优质音乐【评分】、音乐风格、音乐时长、歌手、专辑、发行年月、所属标签、流行度、被重复播放的中位数 思考: 特征的更新频率: 用户:分为长中短期用户画像、仅保存三个月内活跃过的用户的画像以减少存储? 音乐:流行度需要按日期更新、热门程度也可能需要跟节假日相关【圣诞节=》圣诞结】作者回复: 非常赞,我见过最全的思考,推荐大家参考。
2021-04-2422- 张弛 Conor老师,想请问一下为什么在用户行为数据中,将评论数据作为隐性反馈行为呢?因为我的理解,显性反馈行为就是用户对物品的直接评价(评分,赞等),但是评论也算是用户对物品的直接评价,所以我很好奇为什么评论会是隐性反馈呢?(我个人的解释是,在某些场景下,用户的评论并不一定是对物品的评价,比如对于新闻来说,评论可能是对于内容本身的讨论,而不是用户是否喜欢该新闻,但是对于电商类网站,对于物品的评论则可以看做是显性反馈行为,不知道这样理解是否正确呢?)
作者回复: 评论应该一般是以文本的形式存在的,所以其实很难直接判断出用户的好恶,需要进一步通过nlp等手段处理。这和评分是不一样的,评分能可以直接通过分数的高低判断用户的喜好程度。
2020-10-1218  Crystal-clear选择音乐我关注的点,理性总结来说分为三个方向: 1.歌本身:歌名,歌手,歌曲风格,歌词语言,歌曲发布时间,是否约束vip等 2.个人:心情,在做什么,好友推荐等 3.其他:所处环境,歌在APP内的位置,歌的播放量,评论数等 作为一名音乐推荐工程师,在关注用户历史行为信息的同时,现在更应该在乎用户新的行为变化。这是我自己的经验,我一直喜欢听比较宁静一点的歌,但是有一天我突然想听欢快很多的歌,我面临了很多问题,第一我怎么去搜索,第二搜索结果那么多,我怎么选择,第三在搜索结果中随意选择一首总会让自己失望,第四下一次我又该怎么办呢等等,同时你的搜索结果中依旧会出现原来风格的歌曲,这让自己局限在一个风格的“茧房”里面,很难受很无语。所以用户新行为是在推荐系统已经盛行的时代里面更应该关注的地方!
Crystal-clear选择音乐我关注的点,理性总结来说分为三个方向: 1.歌本身:歌名,歌手,歌曲风格,歌词语言,歌曲发布时间,是否约束vip等 2.个人:心情,在做什么,好友推荐等 3.其他:所处环境,歌在APP内的位置,歌的播放量,评论数等 作为一名音乐推荐工程师,在关注用户历史行为信息的同时,现在更应该在乎用户新的行为变化。这是我自己的经验,我一直喜欢听比较宁静一点的歌,但是有一天我突然想听欢快很多的歌,我面临了很多问题,第一我怎么去搜索,第二搜索结果那么多,我怎么选择,第三在搜索结果中随意选择一首总会让自己失望,第四下一次我又该怎么办呢等等,同时你的搜索结果中依旧会出现原来风格的歌曲,这让自己局限在一个风格的“茧房”里面,很难受很无语。所以用户新行为是在推荐系统已经盛行的时代里面更应该关注的地方!作者回复: 非常好的答案。 对于最后一点的想法我觉得非常好,也是我们一直强调的time decay已经exploration的思想,推荐其他同学借鉴思路。
2020-12-01215- shenhuaze王老师,在线预测的时候,模型所需的特征是直接从数据库读取,还是在线实时组装?我在想如果只是用户或者物品自身的特征的话,可以从数据库读取,但如果是用户和物品的交叉特征的话,是不是必须实时组装?
作者回复: 非常好的点。一般来说如果组合特征可以在线处理,最好能够在线处理,因为组合特征有组合爆炸问题,为了节约宝贵的存储资源,一般不直接存储。 但是对于有些不得不存储的组合特征,比如 用户x物品的曝光、点击记录,如果线上模型需要的话,还是要存储到数据库中,因为这些特征你没办法在线组合。
2020-10-09512  金鹏音乐产品更加依赖场景性和心情,在工作、学习、跑步、睡眠、开车、高兴、优伤等等,希望听到的音乐是不同的。所以市面上的音乐目前主要以歌单的形式来推,可以更好的让用户快速找到符合自己当下场景的音乐,感觉更是个强搜索型的产品,音乐的推荐策略更像是一种补充。 针对我个人而言,听音乐时所处的场景或心情、喜欢的音乐类型、喜欢的音乐明星、音乐新热榜、收藏过的歌单 音乐所处的场景 | 用户位置POI数据、历史时段听音乐歌单 | POI数据与音乐匹配度 心情 | 可以通过近几次搜索数据对推荐做干预 | 搜索关键词语义分析 感兴趣的音乐 | 播放历史 | 音乐相似度(可以是音乐Tag、旋律,现在可以基于旋律做歌曲的归类) 喜欢的音乐明星 | 明星收藏、历史播放、点赞、购买等行为 | 音乐新热榜 | 新内容池、热度内容池 | 多样性探索、新鲜度、热度数据 收藏过的歌单 | 收藏数据 | 收藏相似度
金鹏音乐产品更加依赖场景性和心情,在工作、学习、跑步、睡眠、开车、高兴、优伤等等,希望听到的音乐是不同的。所以市面上的音乐目前主要以歌单的形式来推,可以更好的让用户快速找到符合自己当下场景的音乐,感觉更是个强搜索型的产品,音乐的推荐策略更像是一种补充。 针对我个人而言,听音乐时所处的场景或心情、喜欢的音乐类型、喜欢的音乐明星、音乐新热榜、收藏过的歌单 音乐所处的场景 | 用户位置POI数据、历史时段听音乐歌单 | POI数据与音乐匹配度 心情 | 可以通过近几次搜索数据对推荐做干预 | 搜索关键词语义分析 感兴趣的音乐 | 播放历史 | 音乐相似度(可以是音乐Tag、旋律,现在可以基于旋律做歌曲的归类) 喜欢的音乐明星 | 明星收藏、历史播放、点赞、购买等行为 | 音乐新热榜 | 新内容池、热度内容池 | 多样性探索、新鲜度、热度数据 收藏过的歌单 | 收藏数据 | 收藏相似度作者回复: 非常好了。如果是歌单的形式的话,确实歌单更像一个搜索词,更接近一个搜索问题。
2020-10-0910- 马龙流像多模态或者是通过其它预训练方法得到的向量,直接加到推荐排序模型作为特征的话,感觉都没有效果。不知道你这边有没有碰到类似问题呢。我理解是预训练学习的目标和排序学习目标并不一致,不知道大佬怎么看这个问题
作者回复: 确实存在多模态特征效果不强的问题。我觉得还是目前多模态的技术本质上还处于比较初期的阶段。 比如用一些CV的技术去处理视频图像,识别出一些物品,比如视频里有汽车,有甜品之类。但你要说这些物品对于推荐效果到底有没有影响,我觉得还是过于微弱了。远不及知名演员一个要素的影响大。 所以问题本质上还是出在你对特征的理解和业务场景本身的理解上。
2020-10-1269  pedro回答课后问题,按照电影的套路,关联的信息大概有:歌是谁唱的?(比如我的idol),歌的风格是什么?(比如我超喜欢r&b),歌的时长(太长的一律跳过),至少点击过或者单曲循环过?至少听过类似的或者听过该歌手的? 歌的内容即歌词,旋律,副歌?等等 难以被工程化的是歌词内容,毕竟大家都不是专业音乐人,flow和verse这种东西没法去很好的量化,因此特征提取的关键是该特征是否能被量化,如果可以,那可定是可以用来提取特征的,比如说歌的作者和种类,是否单曲循环等。
pedro回答课后问题,按照电影的套路,关联的信息大概有:歌是谁唱的?(比如我的idol),歌的风格是什么?(比如我超喜欢r&b),歌的时长(太长的一律跳过),至少点击过或者单曲循环过?至少听过类似的或者听过该歌手的? 歌的内容即歌词,旋律,副歌?等等 难以被工程化的是歌词内容,毕竟大家都不是专业音乐人,flow和verse这种东西没法去很好的量化,因此特征提取的关键是该特征是否能被量化,如果可以,那可定是可以用来提取特征的,比如说歌的作者和种类,是否单曲循环等。作者回复: 歌词通过nlp,旋律通过一些模式识别也许可以提取出一些风格相似性之类的特征。但正如课程中说的,这些内容类信息都需要进一步处理后才可被推荐系统利用。
2020-10-095- 夜雨声烦影响因素:当时的心情,时间,天气,歌名,歌手,歌曲类型,播放量,是否top,好友中有人听过; 工程师角度: 当时的心情(无法获取)、时间(24小时划分成十个时间段表示)、天气(晴、阴、雨)、歌名(Embedding)、歌手(Embedding)、歌曲类型(onehot)、播放量、是否top(onehot)、好友中有人听过(onehot).
作者回复: 非常好,唯一确实的可能是自己的行为历史,就是听过哪些歌,以及这些历史跟当前要推荐歌曲的联系。
2020-10-0924