

17 基础篇 | CPU是如何执行任务的?

该思维导图由 AI 生成,仅供参考
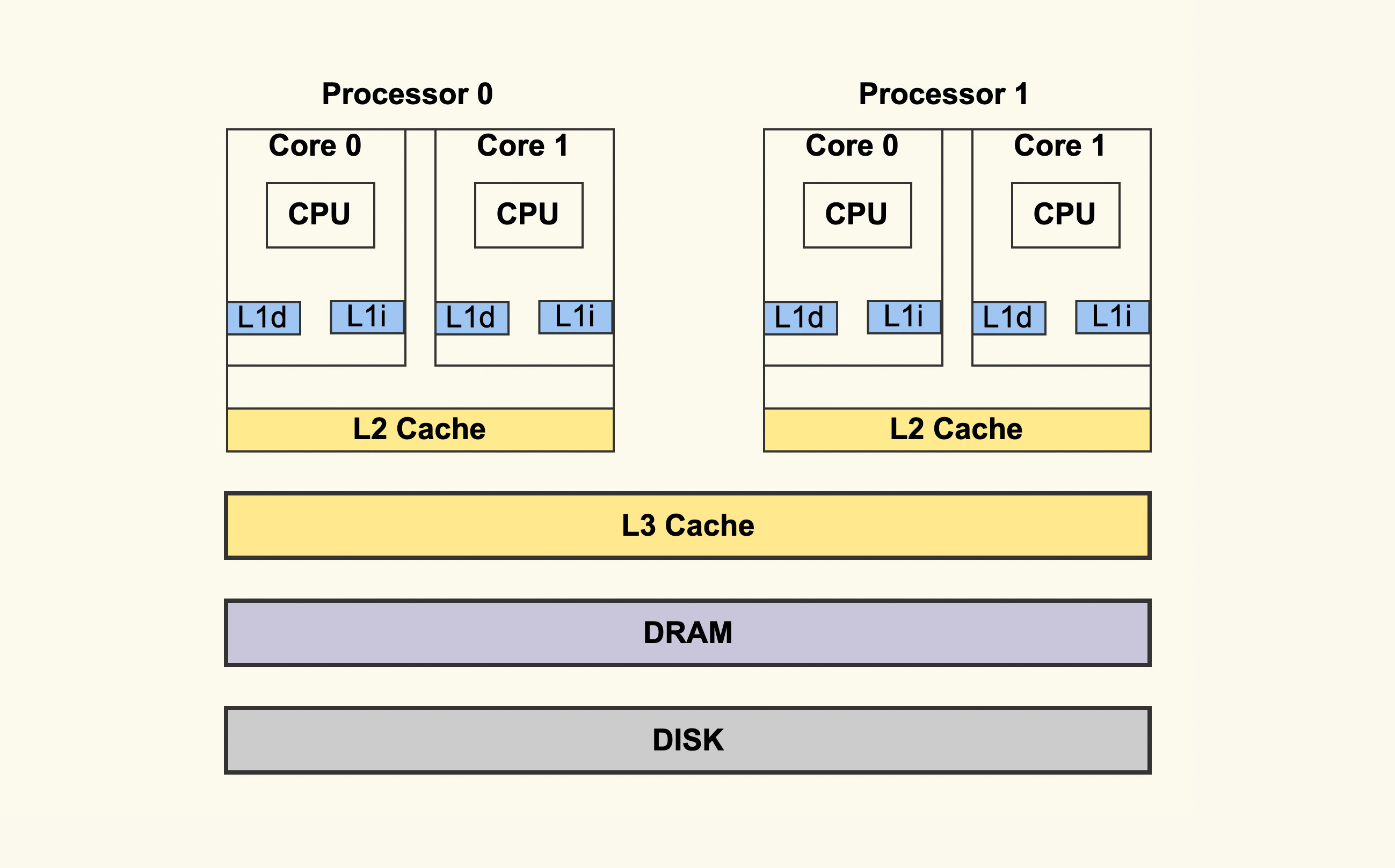
CPU 是如何读写数据的 ?
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了CPU执行任务的相关技术问题,包括CPU架构、内存访问延迟、Cache伪共享和竞争问题等。首先介绍了CPU的架构,包括L1、L2和L3 Cache的关系,以及不同存储层次的访问延迟对性能的影响。随后通过实际案例说明了Cache伪共享问题对性能的影响,并提出了解决方案。此外,还介绍了内存中的竞争问题和位操作的相关知识。最后,文章提到了CPU如何选择线程来执行任务,以及在高并发场景下的调度策略。对于想要深入了解CPU执行任务过程的读者来说,这篇文章提供了全面而深入的技术知识,值得一读。
《Linux 内核技术实战课》,新⼈⾸单¥59

全部留言(5)
- 最新
- 精选
 邵亚方置顶课后作业答案: - 这节课的作业就是我们前面提到的思考题:在psi: Move PF_MEMSTALL out of task->flags这个 PATCH 中,为什么没有考虑多线程并行操作新增加的位域(in_memstall)时的竞争问题? 评论区很多同学回到的都很好。 因为新增的位域(in_memstall)只有current会写,而其他线程是只读,所以不存在并行写的问题,也就是没有竞争。2020-10-116
邵亚方置顶课后作业答案: - 这节课的作业就是我们前面提到的思考题:在psi: Move PF_MEMSTALL out of task->flags这个 PATCH 中,为什么没有考虑多线程并行操作新增加的位域(in_memstall)时的竞争问题? 评论区很多同学回到的都很好。 因为新增的位域(in_memstall)只有current会写,而其他线程是只读,所以不存在并行写的问题,也就是没有竞争。2020-10-116 sufish1.不用考虑多线程并发访问:是因为调度机制已经保证了同一时间同个线程只会有一个cpu处理,相当于同一时间只会有一个cpu访问task_struct ,所以就避免了并发访问的问题? 2.关于Cache 伪共享问题的问题,是否可以考虑在全局变量的前面进行空填充,让这个变量在一个cache line里除了他之外,其他的变量都是占位用的。我猜 ____cacheline_aligned; 实际上也是干这个事
sufish1.不用考虑多线程并发访问:是因为调度机制已经保证了同一时间同个线程只会有一个cpu处理,相当于同一时间只会有一个cpu访问task_struct ,所以就避免了并发访问的问题? 2.关于Cache 伪共享问题的问题,是否可以考虑在全局变量的前面进行空填充,让这个变量在一个cache line里除了他之外,其他的变量都是占位用的。我猜 ____cacheline_aligned; 实际上也是干这个事作者回复: 1. 回答的准确。 2. 是的,____cacheline_aligned;就是干这个事的。
2020-09-28210 我来也课后思考题,如果不是老师的提示,估计我们是没法理解的了. 由于PF_*可能被其他线程写,而task_struct只能被当前运行的线程写,所以这样更改后最终的效果都一样,但是避免了写时冲突的可能. 我有两个疑问: 1. 这样调整后,实际的性能有多少提升呢? 写时冲突是减少了,但读时,理论上还是可能引发类似伪共享的问题吧. (由于我对内核不太了解,也不清楚`current->flags`与`current->in_memstall`在其他地方被使用的频率.还请老师见谅) 2. 如何获取patch的更多上下文信息呢? 老师对内核提交了很多patch,我很是佩服. 每次commit的message也写的比较详细了. 但我还是想了解更多相关的信息,比如别人的一些讨论,中间做过的一些尝试等等. 目前老师附带的链接中只能看到`Link`(https://lkml.kernel.org/r/1584408485-1921-1-git-send-email-laoar.shao@gmail.com) 由这个Link可以查看到`Subject`,`Message-ID`. 但尝试了很久也没找类似issue的讨论信息. 由于linux内核维护有自己的一套流程,好像走的邮件列表,我们外行对这些不太了解. 如果老师觉得这个问题太简单的话,能否给一个学习资料,便于我们去学习和入门如何获取更多的patch相关信息?
我来也课后思考题,如果不是老师的提示,估计我们是没法理解的了. 由于PF_*可能被其他线程写,而task_struct只能被当前运行的线程写,所以这样更改后最终的效果都一样,但是避免了写时冲突的可能. 我有两个疑问: 1. 这样调整后,实际的性能有多少提升呢? 写时冲突是减少了,但读时,理论上还是可能引发类似伪共享的问题吧. (由于我对内核不太了解,也不清楚`current->flags`与`current->in_memstall`在其他地方被使用的频率.还请老师见谅) 2. 如何获取patch的更多上下文信息呢? 老师对内核提交了很多patch,我很是佩服. 每次commit的message也写的比较详细了. 但我还是想了解更多相关的信息,比如别人的一些讨论,中间做过的一些尝试等等. 目前老师附带的链接中只能看到`Link`(https://lkml.kernel.org/r/1584408485-1921-1-git-send-email-laoar.shao@gmail.com) 由这个Link可以查看到`Subject`,`Message-ID`. 但尝试了很久也没找类似issue的讨论信息. 由于linux内核维护有自己的一套流程,好像走的邮件列表,我们外行对这些不太了解. 如果老师觉得这个问题太简单的话,能否给一个学习资料,便于我们去学习和入门如何获取更多的patch相关信息?作者回复: 你的回答很正确。 关于你的疑问: 1. 这样调整的目的不是为了性能提升,而是为了解决PF_*不足的问题。理论上是会存在cache伪共享的问题,不过改写的地方都是在慢速路径上,所以不会成为性能瓶颈。 2. 方式有很多: 1). 去lore上查找对应子系统的信息https://lore.kernel.org/linux-mm/ 然后搜索相应的subject,或者author。 2)lkml上可能也会有(抄送给linux-kernel的邮件) https://lkml.org/ 3)订阅邮件列表 http://vger.kernel.org/vger-lists.html 4)通过git blame来查看文件历史修改记录 看看这些patch被commit之前的一些讨论还是很有帮助的,希望对你能有帮助。
2020-09-2725 那时刻老师的思考题,我的想法是这个in_memstall 的位域,是每个线程独享(排它)一个位域么?这样每个线程可以独立操作其所属位域,不存在竞争了。不知理解是否正确?
那时刻老师的思考题,我的想法是这个in_memstall 的位域,是每个线程独享(排它)一个位域么?这样每个线程可以独立操作其所属位域,不存在竞争了。不知理解是否正确?作者回复: 这个位域其其他线程也能看到,通过task->in_memstall.,但是其他线程是只读,而只有current才会写,也就是同时只会有一个线程写,所以不会存在竞争。
2020-09-27 Linuxer请教一下邵老师:经常看到CPU高,而IPC不高,说是性能问题,这种是不是跟cache miss有关呢?另外使用perf之类的需要对PMU这些有所了解,请问有这块的资料推荐吗?2020-11-17
Linuxer请教一下邵老师:经常看到CPU高,而IPC不高,说是性能问题,这种是不是跟cache miss有关呢?另外使用perf之类的需要对PMU这些有所了解,请问有这块的资料推荐吗?2020-11-17

