

12 基础篇 | TCP收发包过程会受哪些配置项影响?
邵亚方

该思维导图由 AI 生成,仅供参考
你好,我是邵亚方。我们这节课来讲一下,TCP 数据在传输过程中会受到哪些因素干扰。
TCP 收包和发包的过程也是容易引起问题的地方。收包是指数据到达网卡再到被应用程序开始处理的过程。发包则是应用程序调用发包函数到数据包从网卡发出的过程。你应该对 TCP 收包和发包过程中容易引发的一些问题不会陌生,比如说:
网卡中断太多,占用太多 CPU,导致业务频繁被打断;
应用程序调用 write() 或者 send() 发包,怎么会发不出去呢;
数据包明明已经被网卡收到了,可是应用程序为什么没收到呢;
我想要调整缓冲区的大小,可是为什么不生效呢;
是不是内核缓冲区满了从而引起丢包,我该怎么观察呢;
…
想要解决这些问题呢,你就需要去了解 TCP 的收发包过程容易受到哪些因素的影响。这个过程中涉及到很多的配置项,很多问题都是这些配置项跟业务场景不匹配导致的。
我们先来看下数据包的发送过程,这个过程会受到哪些配置项的影响呢?
TCP 数据包的发送过程会受什么影响?
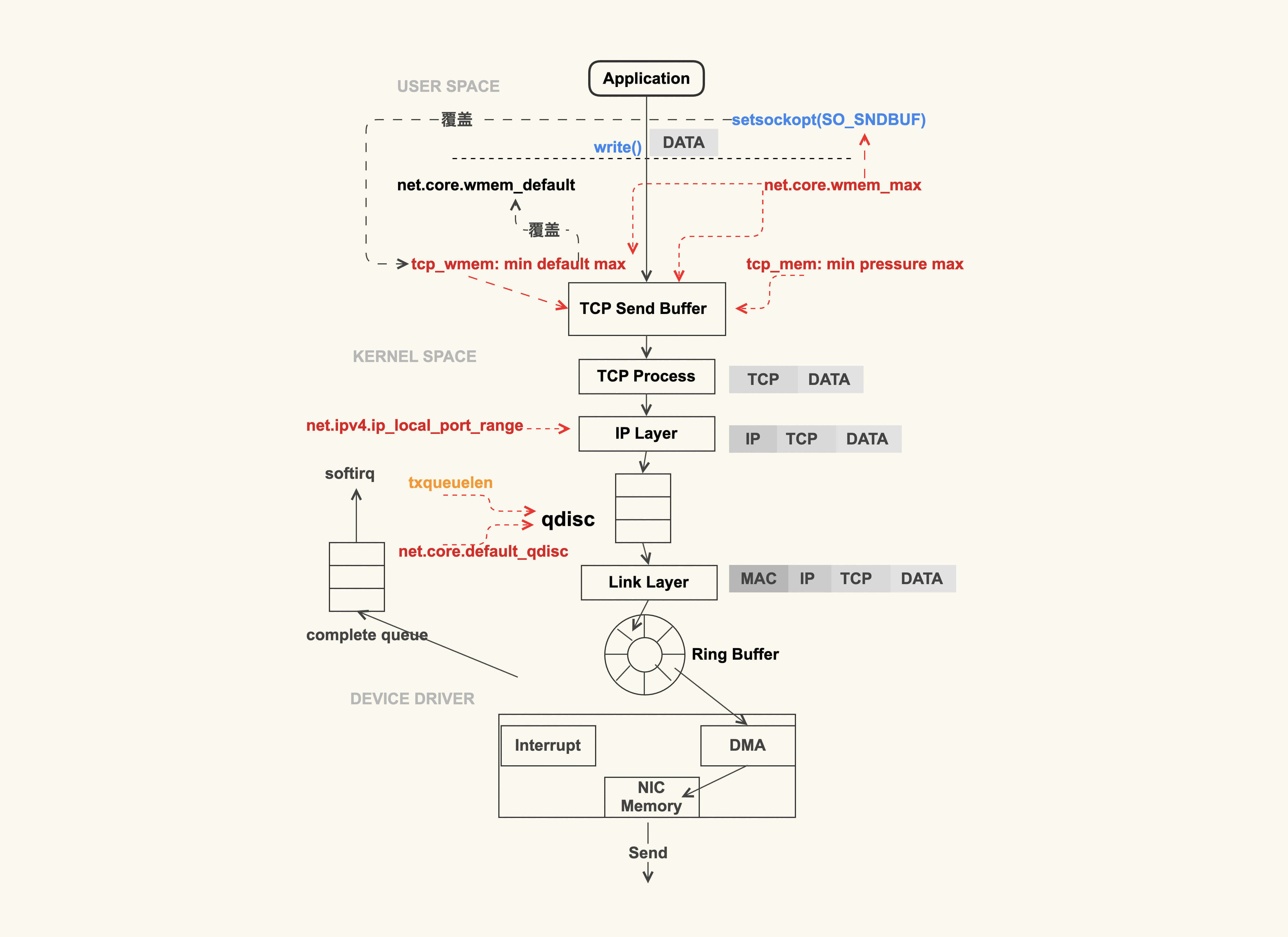
TCP数据包发送过程
上图就是一个简略的 TCP 数据包的发送过程。应用程序调用 write(2) 或者 send(2) 系列系统调用开始往外发包时,这些系统调用会把数据包从用户缓冲区拷贝到 TCP 发送缓冲区(TCP Send Buffer),这个 TCP 发送缓冲区的大小是受限制的,这里也是容易引起问题的地方。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

TCP数据包的接收过程受多个配置项影响,包括中断处理机制、NAPI机制、net.core.netdev_budget配置项、TCP接收缓冲区大小控制等。在高性能网络场景下,NAPI机制通过批量处理数据包来提升效率,减少网卡中断带来的性能开销。通过调整net.core.netdev_budget配置项的值,可以一次性地处理更多的数据包,但需要注意可能带来的CPU调度延迟。TCP接收缓冲区大小受控制,可以通过tcp_rmem和tcp_moderate_rcvbuf进行动态调整,也可以通过setsockopt()中的配置选项SO_RCVBUF来控制。另外,还提到了使用SNMP计数来观察系统中是否存在因TCP接收缓冲区不足而引发的丢包问题。文章还总结了一些配置项的调优建议,并提到了在接收过程中是否使用qdisc的讨论。 总的来说,本文重点介绍了TCP数据包的接收过程中受多个配置项影响的情况,以及针对这些配置项的调优建议,适合需要了解TCP数据包接收过程及性能调优的读者阅读。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《Linux 内核技术实战课》,新⼈⾸单¥59
《Linux 内核技术实战课》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(13)
- 最新
- 精选
 邵亚方置顶课后作业答案: - 在 TCP 发送过程中使用到了 qdisc,但是在接收过程中没有使用它,请问是为什么?我们可以在接收过程中也使用 qdisc 吗? qdisc的主要目的是流控,流控一般都是在发送端进行控制;对于接收端而言,它已经收到这个包了,再进行流控的话,也就只有选择性的丢包。如果在接收端也使用qdisc之类的流控机制,也需要将它模拟为发送端,也就是增加一个中间设备来做。2020-10-1117
邵亚方置顶课后作业答案: - 在 TCP 发送过程中使用到了 qdisc,但是在接收过程中没有使用它,请问是为什么?我们可以在接收过程中也使用 qdisc 吗? qdisc的主要目的是流控,流控一般都是在发送端进行控制;对于接收端而言,它已经收到这个包了,再进行流控的话,也就只有选择性的丢包。如果在接收端也使用qdisc之类的流控机制,也需要将它模拟为发送端,也就是增加一个中间设备来做。2020-10-1117 我来也终于到TCP篇了. 看了文中的`TCP数据包发送过程`图,有几个疑问: 1. 如果用tcpdump抓包,它是在哪一层抓的包呢?(IP Layer / Link Layer) 最近遇到的问题,就是调用write函数有返回值.但是tcpdump抓包来看,并没有迹象. 只知道在此期间有地方把包给丢了,并不知道具体是哪一层丢的.后来发现是内核把包丢了. 2. `TCP Send Buffer`默认是动态调整的. 这个是按需分配的意思么?如果我调整了内核参数,对之前建立的连接产生影响么? 3. 如果`TCP Send Buffer`满了,调用`write`时是阻塞还是返回错误码呢?(是不是跟TCP的阻塞/非阻塞模式有关?) ------------------- 最近在CentOS 7.6上遇到了一个TCP内核方面的问题. 它的内核版本太低了,还是linux-3.10.0-957.21.3.el7. 具体的分析和解决过程参考了这篇博文: [TCP SACK 补丁导致的发送队列报文积压](https://runsisi.com/2019-12-19/tcp-sack-hang)
我来也终于到TCP篇了. 看了文中的`TCP数据包发送过程`图,有几个疑问: 1. 如果用tcpdump抓包,它是在哪一层抓的包呢?(IP Layer / Link Layer) 最近遇到的问题,就是调用write函数有返回值.但是tcpdump抓包来看,并没有迹象. 只知道在此期间有地方把包给丢了,并不知道具体是哪一层丢的.后来发现是内核把包丢了. 2. `TCP Send Buffer`默认是动态调整的. 这个是按需分配的意思么?如果我调整了内核参数,对之前建立的连接产生影响么? 3. 如果`TCP Send Buffer`满了,调用`write`时是阻塞还是返回错误码呢?(是不是跟TCP的阻塞/非阻塞模式有关?) ------------------- 最近在CentOS 7.6上遇到了一个TCP内核方面的问题. 它的内核版本太低了,还是linux-3.10.0-957.21.3.el7. 具体的分析和解决过程参考了这篇博文: [TCP SACK 补丁导致的发送队列报文积压](https://runsisi.com/2019-12-19/tcp-sack-hang)作者回复: 1. 这个tcpdump的原理,我们在后面的课程里会讲到,是在link layer来抓包的。 2. 对的,会按需调整,调整后会影响之前的连接,因为在检查缓冲区大小时会用到这些全局变量。 3. 对的 跟是否设置了阻塞模式有关。 这个blog分享得不错,赞!
2020-09-15310- 唐江发送和接收端的缓冲区都是针对单个连接的吗
作者回复: 单个tcp连接有自己的缓冲区控制 tcp协议栈也有针对所有连接的统一的缓冲区控制
2021-05-262  我能走多远又一个问题需要帮忙解答一下,就是网络收包一共会又几次内存拷贝的流程。 看到一篇文章中说DMA也算一次的化,会又三次?(https://blog.csdn.net/gengzhikui1992/article/details/103142848) 对1,2 步中内存拷贝没有理解透。 1、DMA操作,网卡寄存器->内核为网卡分配的缓冲区ring buffer ring buffer存储的描述符的索引,索引对应存储存储报文的物理地址吧/ 2、驱动软件从ring buffer中读取,填充内核skbuff结构(第2次拷贝:内核网卡缓冲区ring buffer->内核专用数据结构skbuff) 它是把填充skbuff头部也当作了一次内存拷贝吗? 3、socket系统调用将数据从内核搬移到用户态。(第3次拷贝:内核空间->用户空间) 这个是系统调用,比较好理解。2020-11-0913
我能走多远又一个问题需要帮忙解答一下,就是网络收包一共会又几次内存拷贝的流程。 看到一篇文章中说DMA也算一次的化,会又三次?(https://blog.csdn.net/gengzhikui1992/article/details/103142848) 对1,2 步中内存拷贝没有理解透。 1、DMA操作,网卡寄存器->内核为网卡分配的缓冲区ring buffer ring buffer存储的描述符的索引,索引对应存储存储报文的物理地址吧/ 2、驱动软件从ring buffer中读取,填充内核skbuff结构(第2次拷贝:内核网卡缓冲区ring buffer->内核专用数据结构skbuff) 它是把填充skbuff头部也当作了一次内存拷贝吗? 3、socket系统调用将数据从内核搬移到用户态。(第3次拷贝:内核空间->用户空间) 这个是系统调用,比较好理解。2020-11-0913 Wade_阿伟从tcp的发送过程和接受过程,讲解过程中可能影响的配置选项。让我既能很好的理解发送和接受过程,又学习了如何结合生产环境业务场景进行性能优化,真是收货满满。2021-09-051
Wade_阿伟从tcp的发送过程和接受过程,讲解过程中可能影响的配置选项。让我既能很好的理解发送和接受过程,又学习了如何结合生产环境业务场景进行性能优化,真是收货满满。2021-09-051 王崧霁流控应该在上游发送端控制,接收端有个开关net.core.devbudget也是控制发端行为2020-09-1911
王崧霁流控应该在上游发送端控制,接收端有个开关net.core.devbudget也是控制发端行为2020-09-1911 上杉夏香捉个虫,课堂总结第一行中关于 tcp_wmem 的说明,应该是「如果通过SO_SNDBUF来设置发送发送缓冲区」而是不「SO_RECVBUF」2023-04-03归属地:北京
上杉夏香捉个虫,课堂总结第一行中关于 tcp_wmem 的说明,应该是「如果通过SO_SNDBUF来设置发送发送缓冲区」而是不「SO_RECVBUF」2023-04-03归属地:北京 小白debug有个疑惑,老师提到qdisc是在ip层里实现的,但在看代码的时候发现,qdisc是在 __dev_queue_xmit (数据链路层)中被使用到,那qdisc是属于哪一层的呢?2022-11-04归属地:上海
小白debug有个疑惑,老师提到qdisc是在ip层里实现的,但在看代码的时候发现,qdisc是在 __dev_queue_xmit (数据链路层)中被使用到,那qdisc是属于哪一层的呢?2022-11-04归属地:上海 团团-BB老师这种情况从何处入手: eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 9001 inet 10.201.80.130 netmask 255.255.224.0 broadcast 10.201.95.255 ether 02:c6:7a:df:c2:09 txqueuelen 1000 (Ethernet) RX packets 55403028044 bytes 88466263876451 (80.4 TiB) RX errors 0 dropped 1432413 overruns 0 frame 0 TX packets 111313645859 bytes 182202219572067 (165.7 TiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 02022-04-08
团团-BB老师这种情况从何处入手: eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 9001 inet 10.201.80.130 netmask 255.255.224.0 broadcast 10.201.95.255 ether 02:c6:7a:df:c2:09 txqueuelen 1000 (Ethernet) RX packets 55403028044 bytes 88466263876451 (80.4 TiB) RX errors 0 dropped 1432413 overruns 0 frame 0 TX packets 111313645859 bytes 182202219572067 (165.7 TiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 02022-04-08 威如果用 sysctl -p 来使得tcp缓冲区配置立刻生效,这样做之后,已建立了的tcp链接缓冲区大小会改变吗2022-02-181
威如果用 sysctl -p 来使得tcp缓冲区配置立刻生效,这样做之后,已建立了的tcp链接缓冲区大小会改变吗2022-02-181
收起评论

