

17 | 为什么CPU结构也会影响Redis的性能?
蒋德钧

该思维导图由 AI 生成,仅供参考
你好,我是蒋德钧。
很多人都认为 Redis 和 CPU 的关系很简单,就是 Redis 的线程在 CPU 上运行,CPU 快,Redis 处理请求的速度也很快。
这种认知其实是片面的。CPU 的多核架构以及多 CPU 架构,也会影响到 Redis 的性能。如果不了解 CPU 对 Redis 的影响,在对 Redis 的性能进行调优时,就可能会遗漏一些调优方法,不能把 Redis 的性能发挥到极限。
今天,我们就来学习下目前主流服务器的 CPU 架构,以及基于 CPU 多核架构和多 CPU 架构优化 Redis 性能的方法。
主流的 CPU 架构
要了解 CPU 对 Redis 具体有什么影响,我们得先了解一下 CPU 架构。
一个 CPU 处理器中一般有多个运行核心,我们把一个运行核心称为一个物理核,每个物理核都可以运行应用程序。每个物理核都拥有私有的一级缓存(Level 1 cache,简称 L1 cache),包括一级指令缓存和一级数据缓存,以及私有的二级缓存(Level 2 cache,简称 L2 cache)。
这里提到了一个概念,就是物理核的私有缓存。它其实是指缓存空间只能被当前的这个物理核使用,其他的物理核无法对这个核的缓存空间进行数据存取。我们来看一下 CPU 物理核的架构。
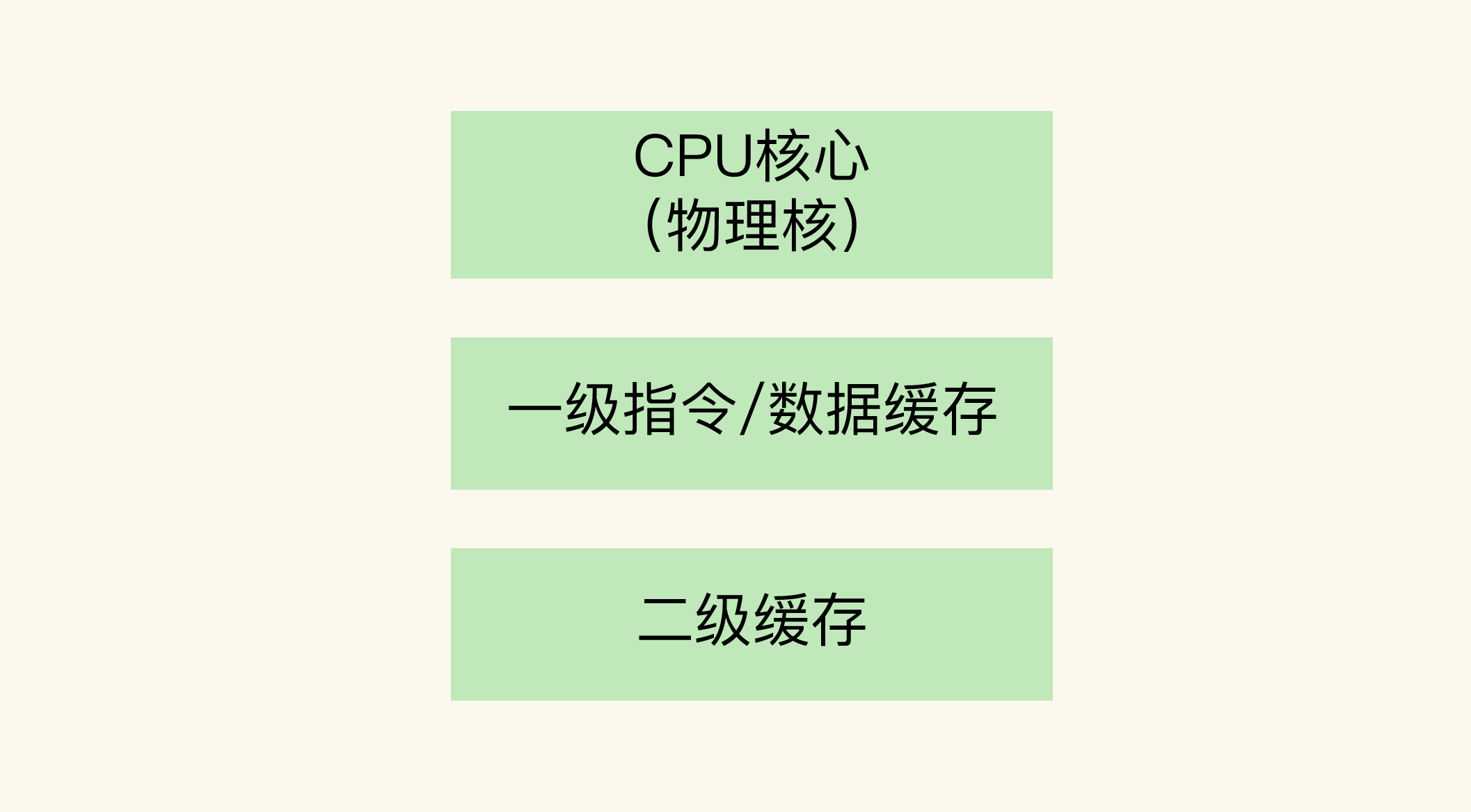
因为 L1 和 L2 缓存是每个物理核私有的,所以,当数据或指令保存在 L1、L2 缓存时,物理核访问它们的延迟不超过 10 纳秒,速度非常快。那么,如果 Redis 把要运行的指令或存取的数据保存在 L1 和 L2 缓存的话,就能高速地访问这些指令和数据。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

Redis性能受CPU架构影响深远,多核CPU环境下频繁调度到不同核上运行会增加请求处理时间。绑定Redis实例和CPU核可降低尾延迟,提升性能。NUMA架构会增加应用程序延迟,建议将Redis实例和网络中断处理程序绑在同一CPU Socket下的不同核上。绑定一个物理核可缓解CPU资源竞争,源码优化可避免主线程、子进程和后台线程竞争。在多核服务器上部署Redis切片集群时,应根据网络数据读取影响选择合适方案。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《Redis 核心技术与实战》,新⼈⾸单¥68
《Redis 核心技术与实战》,新⼈⾸单¥68
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(60)
- 最新
- 精选
 薛定谔的猫小白请教一下,网络中断处理程序是指什么呢?
薛定谔的猫小白请教一下,网络中断处理程序是指什么呢?作者回复: 当网卡接收到数据后,会触发网卡中断,用来通知操作系统内核进行数据处理。因此,操作系统内核中用来处理网卡中断事件,把数据从内核的缓冲区拷贝到应用程序缓冲区的程序就是指网卡中断处理程序。
2020-11-25763 许峰阿里云ecs主机都是vcpus, 这玩意算物理核心吗? 比如一个4vcpu, lscpu可以看到 NUMA node0 CPU(s): 0-3 这么绑?
许峰阿里云ecs主机都是vcpus, 这玩意算物理核心吗? 比如一个4vcpu, lscpu可以看到 NUMA node0 CPU(s): 0-3 这么绑?作者回复: ECS主机提供的vCPU是指虚拟核,一般对应一个物理核心上的一个超线程,这是因为底层服务器一般会开启超线程。通常,一个物理核心会对应2个超线程,每个超线程对应一个vCPU。多个vCPU一般是在同一个NUMA节点上。 如果希望减少CPU超线程对性能的影响,可以通过阿里云SDK的选项关闭超线程。
2020-11-30226 T很多人都认为 Redis 和 CPU 的关系很简单,就是 Redis 的线程在 CPU 上运行,CPU 快,Redis 处理请求的速度也很快。 这种认知其实是片面的。CPU 的多核架构以及多 CPU 架构,也会影响到 Redis 的性能。如果不了解 CPU 对 Redis 的影响,在对 Redis 的性能进行调优时,就可能会遗漏一些调优方法,不能把 Redis 的性能发挥到极限。
T很多人都认为 Redis 和 CPU 的关系很简单,就是 Redis 的线程在 CPU 上运行,CPU 快,Redis 处理请求的速度也很快。 这种认知其实是片面的。CPU 的多核架构以及多 CPU 架构,也会影响到 Redis 的性能。如果不了解 CPU 对 Redis 的影响,在对 Redis 的性能进行调优时,就可能会遗漏一些调优方法,不能把 Redis 的性能发挥到极限。作者回复: CPU有多核,即使单核上也会有超线程技术。除了多核,多处理器会形成NUMA架构,这些都会对系统性能产生影响。 所以,计算机体系结构的知识点对系统优化还是很有帮助的:)
2020-11-1215
 Kaito这篇文章收获很大!对于CPU结构和如何绑核有了进一步了解。其实在NUMA架构下,不光对于CPU的绑核需要注意,对于内存的使用,也有很多注意点,下面回答课后问题,也会提到NUMA架构下内存方面的注意事项。 在一台有2个CPU Socket(每个Socket 8个物理核)的服务器上,我们部署了有8个实例的Redis切片集群(8个实例都为主节点,没有主备关系),采用哪种方案绑核最佳? 我更倾向于的方案是:在两个CPU Socket上各运行4个实例,并和相应Socket上的核绑定。这么做的原因主要从L3 Cache的命中率、内存利用率、避免使用到Swap这三个方面考虑: 1、由于CPU Socket1和2分别有自己的L3 Cache,如果把所有实例都绑定在同一个CPU Socket上,相当于这些实例共用这一个L3 Cache,另一个CPU Socket的L3 Cache浪费了。这些实例共用一个L3 Cache,会导致Cache中的数据频繁被替换,访问命中率下降,之后只能从内存中读取数据,这会增加访问的延迟。而8个实例分别绑定CPU Socket,可以充分使用2个L3 Cache,提高L3 Cache的命中率,减少从内存读取数据的开销,从而降低延迟。 2、如果这些实例都绑定在一个CPU Socket,由于采用NUMA架构的原因,所有实例会优先使用这一个节点的内存,当这个节点内存不足时,再经过总线去申请另一个CPU Socket下的内存,此时也会增加延迟。而8个实例分别使用2个CPU Socket,各自在访问内存时都是就近访问,延迟最低。 3、如果这些实例都绑定在一个CPU Socket,还有一个比较大的风险是:用到Swap的概率将会大大提高。如果这个CPU Socket对应的内存不够了,也可能不会去另一个节点申请内存(操作系统可以配置内存回收策略和Swap使用倾向:本节点回收内存/其他节点申请内存/内存数据换到Swap的倾向程度),而操作系统可能会把这个节点的一部分内存数据换到Swap上从而释放出内存给进程使用(如果没开启Swap可会导致直接OOM)。因为Redis要求性能非常高,如果从Swap中读取数据,此时Redis的性能就会急剧下降,延迟变大。所以8个实例分别绑定CPU Socket,既可以充分使用2个节点的内存,提高内存使用率,而且触发使用Swap的风险也会降低。 其实我们可以查一下,在NUMA架构下,也经常发生某一个节点内存不够,但其他节点内存充足的情况下,依旧使用到了Swap,进而导致软件性能急剧下降的例子。所以在运维层面,我们也需要关注NUMA架构下的内存使用情况(多个内存节点使用可能不均衡),并合理配置系统参数(内存回收策略/Swap使用倾向),尽量去避免使用到Swap。2020-09-1638325
Kaito这篇文章收获很大!对于CPU结构和如何绑核有了进一步了解。其实在NUMA架构下,不光对于CPU的绑核需要注意,对于内存的使用,也有很多注意点,下面回答课后问题,也会提到NUMA架构下内存方面的注意事项。 在一台有2个CPU Socket(每个Socket 8个物理核)的服务器上,我们部署了有8个实例的Redis切片集群(8个实例都为主节点,没有主备关系),采用哪种方案绑核最佳? 我更倾向于的方案是:在两个CPU Socket上各运行4个实例,并和相应Socket上的核绑定。这么做的原因主要从L3 Cache的命中率、内存利用率、避免使用到Swap这三个方面考虑: 1、由于CPU Socket1和2分别有自己的L3 Cache,如果把所有实例都绑定在同一个CPU Socket上,相当于这些实例共用这一个L3 Cache,另一个CPU Socket的L3 Cache浪费了。这些实例共用一个L3 Cache,会导致Cache中的数据频繁被替换,访问命中率下降,之后只能从内存中读取数据,这会增加访问的延迟。而8个实例分别绑定CPU Socket,可以充分使用2个L3 Cache,提高L3 Cache的命中率,减少从内存读取数据的开销,从而降低延迟。 2、如果这些实例都绑定在一个CPU Socket,由于采用NUMA架构的原因,所有实例会优先使用这一个节点的内存,当这个节点内存不足时,再经过总线去申请另一个CPU Socket下的内存,此时也会增加延迟。而8个实例分别使用2个CPU Socket,各自在访问内存时都是就近访问,延迟最低。 3、如果这些实例都绑定在一个CPU Socket,还有一个比较大的风险是:用到Swap的概率将会大大提高。如果这个CPU Socket对应的内存不够了,也可能不会去另一个节点申请内存(操作系统可以配置内存回收策略和Swap使用倾向:本节点回收内存/其他节点申请内存/内存数据换到Swap的倾向程度),而操作系统可能会把这个节点的一部分内存数据换到Swap上从而释放出内存给进程使用(如果没开启Swap可会导致直接OOM)。因为Redis要求性能非常高,如果从Swap中读取数据,此时Redis的性能就会急剧下降,延迟变大。所以8个实例分别绑定CPU Socket,既可以充分使用2个节点的内存,提高内存使用率,而且触发使用Swap的风险也会降低。 其实我们可以查一下,在NUMA架构下,也经常发生某一个节点内存不够,但其他节点内存充足的情况下,依旧使用到了Swap,进而导致软件性能急剧下降的例子。所以在运维层面,我们也需要关注NUMA架构下的内存使用情况(多个内存节点使用可能不均衡),并合理配置系统参数(内存回收策略/Swap使用倾向),尽量去避免使用到Swap。2020-09-1638325- Geek_9b08a51.作者讲了什么? 在多核CPU架构和NUMA架构下,如何对redis进行优化配置 2.作者是怎么把这件事将明白的? 1,讲解了主流的CPU架构,主要有多核CPU架构和NUMA架构两个架构 多核CPU架构: 多个物理核,各物理核使用私有的1、2级缓存,共享3级缓存。物理核可包含2个超线程,称为逻辑核 NUMA架构: 一个服务器上多个cpu,称为CPU Socket,每个cpu socker存在多个物理核。每个socket通过总线连接,并且有用私有的内存空间 3.为了讲明白,作者讲了哪些要点,哪些亮点? 1、亮点:将主流的CPU架构进行剖析,使人更好理解cpu的原理,有助于后续redis性能的优化 2、要点:cpu架构:一个cpu一般拥有多个物理核,每个物理核都拥有私有的一级缓存,二级缓存。三级缓存是各物理核共享的缓存空间。而物理核又可以分为多个超线程,称为逻辑核,同一个物理核的逻辑核会共享使用 L1、L2 缓存。 3、要点:一级缓存和二级缓存访问延迟不超过10纳秒,但空间很小,只是KB单位。而应用程序访问内存延迟是百纳秒级别,基本上是一二级缓存的10倍 4、要点:不同的物理核还会共享一个共同的三级缓存,三级缓存空间比较多,为几到几十MB,当 L1、L2 缓存中没有数据缓存时,可以访问 L3,尽可能避免访问内存。 5、要点:多核CPU运行redis实例,会导致context switch,导致增加延迟,可以通过taskset 命令把redis进程绑定到某个cup物理核上。 6、要点:NUMA架构运行redis实例,如果网络中断程序和redis实例运行在不同的socket上,就需要跨 CPU Socket 访问内存,这个过程会花费较多时间。 7、要点:绑核的风险和解决方案: 一个 Redis 实例对应绑一个物理核 : 将redis服务绑定到一个物理核上,而不是一个逻辑核上,如 taskset -c 0,12 ./redis-server 优化 Redis 源码。 4.对于作者所讲的,我有哪些发散性思考? 给自己提了几个问题: 1,在多核CPU架构和NUMA架构,那个对于redis来说性能比较好 2,如何设置网络中断处理和redis绑定设置在同个socket上呢? 5.将来在哪些场景里,我能够使用它? 6.留言区收获 如果redis实例中内存不足以使用时,会用到swap那会怎么样?(答案来自@kaito 大佬) 因为Redis要求性能非常高,如果从Swap中读取数据,此时Redis的性能就会急剧下降,延迟变大。2020-12-3032
 test课后问题:我会选择方案二。首先一个实例不止有一个线程需要运行,所以方案一肯定会有CPU竞争问题;其次切片集群的通信不是通过内存,而是通过网络IO。2020-09-16215
test课后问题:我会选择方案二。首先一个实例不止有一个线程需要运行,所以方案一肯定会有CPU竞争问题;其次切片集群的通信不是通过内存,而是通过网络IO。2020-09-16215 小可这篇文章真是太好了!对cpu有了更多的认识,公司服务lscpu挨个看了一遍,不懂的地方也去查了资料,自己也画了NUMA架构下多个cpu socket示意图,给每个逻辑cpu编号,对照图看怎么绑定网络中断和redis实例到同一个cpu socket,怎么绑定一个redis实例到同一个物理核,非常清晰!还有cpu的架构设计思路也可以应用到我们实际系统架构上,不得不赞叹这些神级设计,也感谢老师心细深入的讲解,真的发现宝藏了,O(∩_∩)O哈哈~2021-02-04311
小可这篇文章真是太好了!对cpu有了更多的认识,公司服务lscpu挨个看了一遍,不懂的地方也去查了资料,自己也画了NUMA架构下多个cpu socket示意图,给每个逻辑cpu编号,对照图看怎么绑定网络中断和redis实例到同一个cpu socket,怎么绑定一个redis实例到同一个物理核,非常清晰!还有cpu的架构设计思路也可以应用到我们实际系统架构上,不得不赞叹这些神级设计,也感谢老师心细深入的讲解,真的发现宝藏了,O(∩_∩)O哈哈~2021-02-04311 游弋云端有两套房子,就不用挤着睡吧,优选方案二。老师实验用的X86的CPU吧,对于ARM架构来讲,存在着跨DIE和跨P的说法,跨P的访问时延会更高,且多个P之间的访问存在着NUMA distances的说法,不同的布局导致的跨P访问时延也不相同。2020-09-1611
游弋云端有两套房子,就不用挤着睡吧,优选方案二。老师实验用的X86的CPU吧,对于ARM架构来讲,存在着跨DIE和跨P的说法,跨P的访问时延会更高,且多个P之间的访问存在着NUMA distances的说法,不同的布局导致的跨P访问时延也不相同。2020-09-1611 元末这篇文章很顶2021-07-136
元末这篇文章很顶2021-07-136 zhou在 NUMA 架构下,比如有两个 CPU Socket:CPU Socket 1 和 CPU Socket 2,每个 CPU Socket 都有自己的内存,CPU Socket 1 有自己的内存 Mem1,CPU Socket 2 有自己的内存 Mem2。 Redis 实例在 CPU Socket 1 上执行,网络中断处理程序在 CPU Socket 2 上执行,所以 Redis 实例的数据在内存 Mem1 上,网络中断处理程序的数据在 Mem2上。 因此 Redis 实例读取网络中断处理程序的内存数据(Mem2)时,是需要远端访问的,比直接访问自己的内存数据(Mem1)要慢。2020-09-165
zhou在 NUMA 架构下,比如有两个 CPU Socket:CPU Socket 1 和 CPU Socket 2,每个 CPU Socket 都有自己的内存,CPU Socket 1 有自己的内存 Mem1,CPU Socket 2 有自己的内存 Mem2。 Redis 实例在 CPU Socket 1 上执行,网络中断处理程序在 CPU Socket 2 上执行,所以 Redis 实例的数据在内存 Mem1 上,网络中断处理程序的数据在 Mem2上。 因此 Redis 实例读取网络中断处理程序的内存数据(Mem2)时,是需要远端访问的,比直接访问自己的内存数据(Mem1)要慢。2020-09-165
收起评论

