

02 | 数据结构:快速的Redis有哪些慢操作?

该思维导图由 AI 生成,仅供参考
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

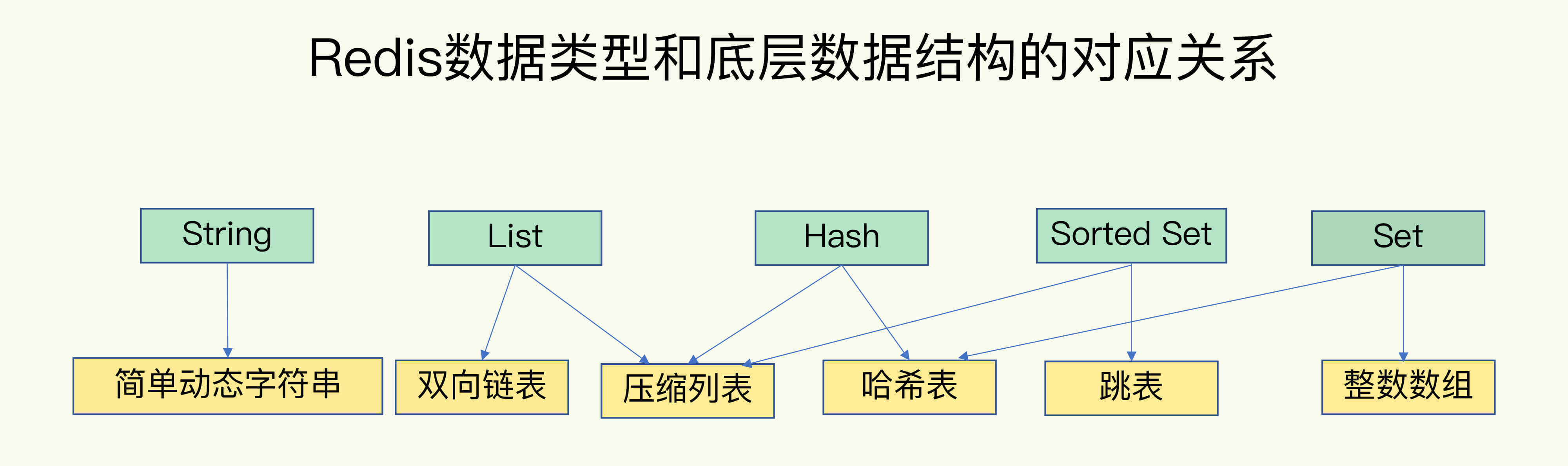
本文主要讨论了Redis中数据结构的重要性和影响因素。作者首先介绍了Redis的快速特性是由内存数据库和高效的数据结构共同实现的。然后详细介绍了Redis中的底层数据结构,包括简单动态字符串、双向链表、压缩列表、哈希表、跳表和整数数组。作者重点解释了全局哈希表的作用和哈希冲突问题,以及Redis中采用的渐进式rehash来解决哈希表扩容时的操作阻塞问题。此外,还介绍了集合类型的操作效率与底层数据结构和操作特点相关。文章总结了集合类型操作的复杂度,包括单元素操作、范围操作、统计操作和特殊情况。最后,强调了掌握数据结构基本原理的重要性,以便能够从原理上推断不同操作的复杂度,从而做出合理的选择。整体而言,本文深入浅出地介绍了Redis中数据结构的重要性和影响因素,为读者理解Redis的性能优势和潜在的“慢操作”提供了基础知识。
《Redis 核心技术与实战》,新⼈⾸单¥68

全部留言(249)
- 最新
- 精选

 Kaito两方面原因: 1、内存利用率,数组和压缩列表都是非常紧凑的数据结构,它比链表占用的内存要更少。Redis是内存数据库,大量数据存到内存中,此时需要做尽可能的优化,提高内存的利用率。 2、数组对CPU高速缓存支持更友好,所以Redis在设计时,集合数据元素较少情况下,默认采用内存紧凑排列的方式存储,同时利用CPU高速缓存不会降低访问速度。当数据元素超过设定阈值后,避免查询时间复杂度太高,转为哈希和跳表数据结构存储,保证查询效率。
Kaito两方面原因: 1、内存利用率,数组和压缩列表都是非常紧凑的数据结构,它比链表占用的内存要更少。Redis是内存数据库,大量数据存到内存中,此时需要做尽可能的优化,提高内存的利用率。 2、数组对CPU高速缓存支持更友好,所以Redis在设计时,集合数据元素较少情况下,默认采用内存紧凑排列的方式存储,同时利用CPU高速缓存不会降低访问速度。当数据元素超过设定阈值后,避免查询时间复杂度太高,转为哈希和跳表数据结构存储,保证查询效率。作者回复: 回答的很好! 我再提个小问题,如果在数组上是随机访问,对CPU高速缓存还友好不?:)
2020-08-0446555 张德同问 老师 如果渐进式哈希操作 如果有一个value操作很长时间段都没被查到 那渐进式哈希会持续非常长的时间吗 还是会在空闲的时候 也给挪到扩容的hash表里面
张德同问 老师 如果渐进式哈希操作 如果有一个value操作很长时间段都没被查到 那渐进式哈希会持续非常长的时间吗 还是会在空闲的时候 也给挪到扩容的hash表里面作者回复: 渐进式rehash执行时,除了根据键值对的操作来进行数据迁移,Redis本身还会有一个定时任务在执行rehash,如果没有键值对操作时,这个定时任务会周期性地(例如每100ms一次)搬移一些数据到新的哈希表中,这样可以缩短整个rehash的过程。
2020-08-248105 不能扮演天使Redis的List底层使用压缩列表本质上是将所有元素紧挨着存储,所以分配的是一块连续的内存空间,虽然数据结构本身没有时间复杂度的优势,但是这样节省空间而且也能避免一些内存碎片;
不能扮演天使Redis的List底层使用压缩列表本质上是将所有元素紧挨着存储,所以分配的是一块连续的内存空间,虽然数据结构本身没有时间复杂度的优势,但是这样节省空间而且也能避免一些内存碎片;作者回复: 赞!所以不同的设计选择都是有背后的考虑。
2020-08-03576 那时刻请问老师关于zset的问题,您在文中提到Sorted Set内部实现数据结构是跳表和压缩列表。但是我从zset代码看到这样的注释 The elements are added to a hash table mapping Redis objects to scores. At the same time the elements are added to a skip list mapping scores to Redis objects 按照注释应该还有hash table来额外存储数据吧,这样在zset里查找单个元素,可以从O(logN)降低为O(1)。不知道我理解的是否正确?
那时刻请问老师关于zset的问题,您在文中提到Sorted Set内部实现数据结构是跳表和压缩列表。但是我从zset代码看到这样的注释 The elements are added to a hash table mapping Redis objects to scores. At the same time the elements are added to a skip list mapping scores to Redis objects 按照注释应该还有hash table来额外存储数据吧,这样在zset里查找单个元素,可以从O(logN)降低为O(1)。不知道我理解的是否正确?作者回复: 看得非常仔细,赞一个! zset有个ZSCORE的操作,用于返回单个集合member的分数,它的操作复杂度是O(1),这就是收益于你这看到的hash table。这个hash table保存了集合元素和相应的分数,所以做ZSCORE操作时,直接查这个表就可以,复杂度就降为O(1)了。 而跳表主要服务范围操作,提供O(logN)的复杂度。
2020-08-06562 宙斯老师你好,hash表是全局的,这里的全局怎样理解?是‘存放key的数组全局只有一个‘是这样理解吗?
宙斯老师你好,hash表是全局的,这里的全局怎样理解?是‘存放key的数组全局只有一个‘是这样理解吗?作者回复: 这个全局是指Redis数据库中的所有key和value,是由一个哈希表来索引的。通过在这个哈希表中查询key,就可以找到对应的value。然后根据value的具体类型(例如Hash,Set,List等),再通过value的底层数据结构来读取具体的value数据,例如List通过双向链表来读取数据。
2020-12-1432 刘忽悠redis底层的数据压缩搞的很细致,像sds,根据字节长度划分的很细致,另外采用的c99特性的动态数组,对短字符串进行一次性的内存分配;跳表设计的也很秀,简单明了,进行范围查询很方便;dict的扩容没细看,但是看了一下数据结构,应该是为了避免发生扩容的时候出现整体copy; 个人觉得老师应该把sds,dict等具体数据结构的源码也贴上
刘忽悠redis底层的数据压缩搞的很细致,像sds,根据字节长度划分的很细致,另外采用的c99特性的动态数组,对短字符串进行一次性的内存分配;跳表设计的也很秀,简单明了,进行范围查询很方便;dict的扩容没细看,但是看了一下数据结构,应该是为了避免发生扩容的时候出现整体copy; 个人觉得老师应该把sds,dict等具体数据结构的源码也贴上作者回复: dict的渐进式rehash是为了避免扩容时的整体拷贝,这会给内存带来较大压力。 SDS我们后面还会再聊:)
2020-08-03221 米 虫要是加餐中来一偏,一个redis指令的执行过程,那大局观就更深刻了。
米 虫要是加餐中来一偏,一个redis指令的执行过程,那大局观就更深刻了。作者回复: 我们后面的课程会涉及这个过程,再耐心等等哈
2020-08-0419 小飞同学
小飞同学 小问题: 1.rehash的时候为啥存储位置会发生变化?一个对象的hashCode始终是一样的。 还是说rehash是对槽进行取模 2.跳表找元素没太看明白,是二分查找么?怎么感觉找33那个元素不止3次 课后一问: 因为数组占用内存连续,不需要随机读取。同时碎片化问题也不需要考虑。 希望得到老师的解答,谢谢
小问题: 1.rehash的时候为啥存储位置会发生变化?一个对象的hashCode始终是一样的。 还是说rehash是对槽进行取模 2.跳表找元素没太看明白,是二分查找么?怎么感觉找33那个元素不止3次 课后一问: 因为数组占用内存连续,不需要随机读取。同时碎片化问题也不需要考虑。 希望得到老师的解答,谢谢作者回复: 一个对象保存到哈希桶时,实际是要用它的hash值对哈希桶个数取模的,所以rehash时,桶个数发生了变化,那么对象的存储位置也会有所变化。 跳表的查找通过不同层的指针来跳转,指针比较多时,类似于二分查找了。
2020-08-049- 刘忽悠至于问题答案,采用压缩列表或者是整数集合,都是数据量比较小的情况,所以一次能够分配到足够大的内存,而压缩列表和整数集合本身的数据结构也是线性的,对cpu的缓存更友好一些,所以真正的执行的时间因为高速缓存的关系,速度更快
作者回复: 提个小问题哈,如果压缩列表也是随机跳着访问,对CPU缓存还友好不?
2020-08-039  Lywanerehash不仅全局有,单独的值为HASH类型的数据也会有吧
Lywanerehash不仅全局有,单独的值为HASH类型的数据也会有吧作者回复: 是的,哈希表这个结构,整个数据库空间用它来保存键值对,同时HASH类型的键值对也用它作为底层结构。所以,rehash也是两种情况下都有的。
2020-08-177

