

06 | 故障发现:如何建设On-Call机制?

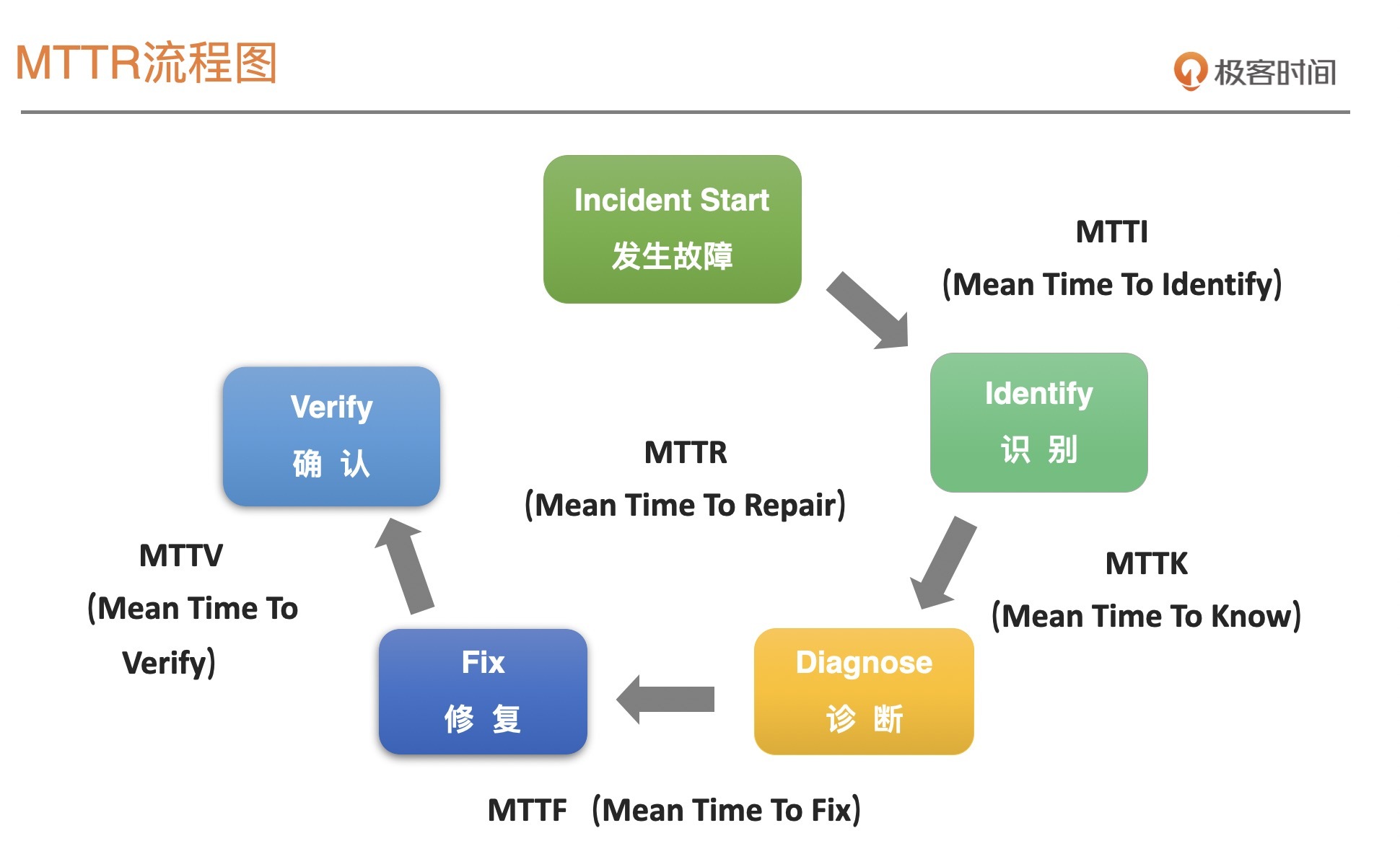
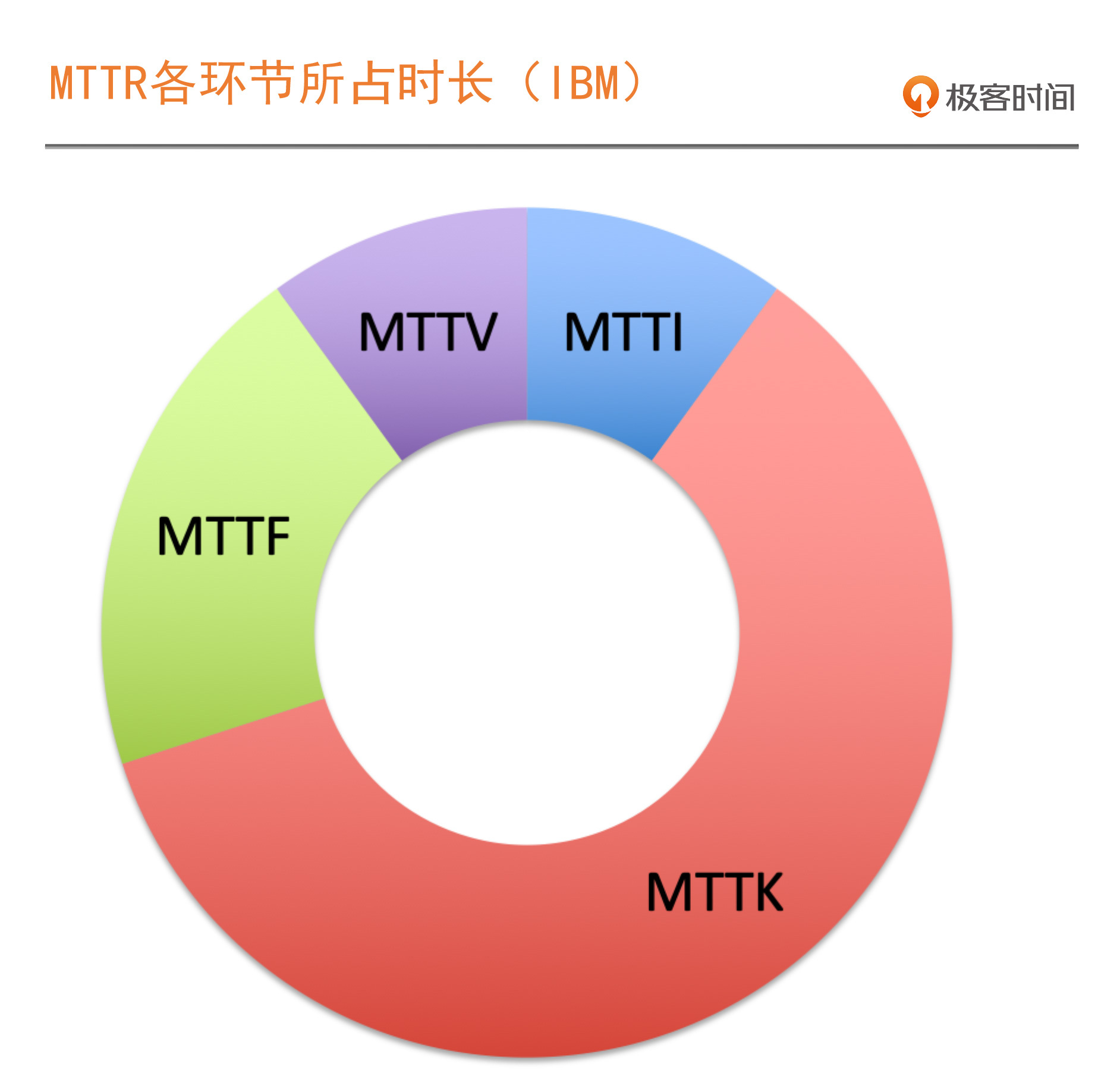
聚焦 MTTR,故障处理的关键环节
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

建设On-Call机制是保障系统稳定性的关键环节。文章首先介绍了SRE的基础概念,包括SLI、SLO和Error Budget策略。随后重点讨论了故障处理的关键环节MTTR,着重分析了MTTI环节的重要性。在实际情况中,MTTI的时间分布可能与传统统计有所不同,特别是在分布式软件系统中。针对MTTI环节,文章提出了提高处理效率的措施,包括利用SLO和错误预算判定故障等级,以及建设On-Call机制。在On-Call阶段,监控和告警体系起着关键作用,需要根据SLO响应告警,并强调了On-Call的流程机制建设的重要性。整体而言,文章强调了建设On-Call机制对于故障处理效率和系统稳定性的重要性,为读者提供了实用的建议和思路。 文章中分享了两个关于On-Call的案例,强调了协作机制的重要性。接着,文章总结了“On-Call关键5步法”,包括确保关键角色在线、组织War Room应急组织、建立合理的呼叫方式、确保资源投入的升级机制以及与云的联合On-Call。这些步骤为建设高效的On-Call机制提供了具体指导。最后,文章提出了一个思考题,引导读者思考监控体系和高效的On-Call机制在故障处理中的重要性及如何结合更有效。 通过本文,读者可以快速了解到建设On-Call机制对系统稳定性的重要性,以及如何通过具体步骤来建设高效的On-Call流程机制,为故障处理提供了有益的思路和建议。
《SRE 实战手册》,新⼈⾸单¥29

全部留言(22)
- 最新
- 精选
 美美置顶谷歌SRE应急时间处理策略有一条是:由万(全)能工程师解决生产问题 向 手持“运维手册”的经过演练的on-call工程师 演进,核心思路是建设故障处理SOP,保证SRE可以处理大多数故障。这个思路是否和确保关键角色在线冲突!
美美置顶谷歌SRE应急时间处理策略有一条是:由万(全)能工程师解决生产问题 向 手持“运维手册”的经过演练的on-call工程师 演进,核心思路是建设故障处理SOP,保证SRE可以处理大多数故障。这个思路是否和确保关键角色在线冲突!作者回复: “由万(全)能工程师解决生产问题 向 手持“运维手册”的经过演练的on-call工程师 演进,核心思路是建设故障处理SOP,保证SRE可以处理大多数故障” 感谢你的分享,直接道出了我们oncall应该追求的目标,对于我们内容是非常好的补充。 内容里我们提到的关键角色在线,就是指on-call工程师必须在值守过程中准实时在线,目的是为了及时响应,这个是机制上的保障,然后在处理问题时,需要有故障处理SOP,并且能按照SOP执行,这个是能力上的要求。 所以,两者不矛盾。再次感谢你的补充,非常棒。
2020-03-3120 soong监控体系解决的问题是给我们提供一个视角,更快发现或感知到问题发生。On-Call机制想要解决的在于真正去处理、解决问题的部分,关注点是有效性与机制建设本身。 没有监控系统的支撑,感知到故障发生所需的时间就要很久;没有高效的On-Call机制,处理并解决故障问题的时间也会被拉长,老师文中也有举例!从重要性的层面来看,两者是相互促进、相互支撑的作用。 从公司的发展过程来看,我个人认为,先建设一个能有效运行的监控系统,随后跟进On-Call机制的建设,是一个可行的路线!先建设On-Call机制,如果缺乏有效的监控系统,从提升系统的稳定性来看,针对性似显不足。希望看到老师的观点!
soong监控体系解决的问题是给我们提供一个视角,更快发现或感知到问题发生。On-Call机制想要解决的在于真正去处理、解决问题的部分,关注点是有效性与机制建设本身。 没有监控系统的支撑,感知到故障发生所需的时间就要很久;没有高效的On-Call机制,处理并解决故障问题的时间也会被拉长,老师文中也有举例!从重要性的层面来看,两者是相互促进、相互支撑的作用。 从公司的发展过程来看,我个人认为,先建设一个能有效运行的监控系统,随后跟进On-Call机制的建设,是一个可行的路线!先建设On-Call机制,如果缺乏有效的监控系统,从提升系统的稳定性来看,针对性似显不足。希望看到老师的观点!作者回复: 前面两段讲清楚了,监控和on-call机制的关系,很赞。 最后的问题,其实我的建议是,先要有on-call机制,因为问题反馈的渠道不一定只要监控,可能还有用户投诉、同事反馈等等,当遇到这些问题时,也需要有高效的响应机制。而且在早期,有可能监控并不准确,反而是其它渠道的反馈占比更高。
2020-04-0416 EQLTON-call机制重要,毕竟监控体系是持续优化进步的过程,而业务的故障是随时发生,优先恢复业务是最高优先级。良好的on-call机制既能保障业务,也能将处理过的故障快速反馈到监控体系,进一步优化监控体系,达到双赢。
EQLTON-call机制重要,毕竟监控体系是持续优化进步的过程,而业务的故障是随时发生,优先恢复业务是最高优先级。良好的on-call机制既能保障业务,也能将处理过的故障快速反馈到监控体系,进一步优化监控体系,达到双赢。作者回复: 思考的很全面奥
2020-03-309 moqi在某某公司的运维小伙和我提起过,他们那的系统出了问题,SRE的第一件事是写故障报告,第二件事是解决问题,坑爹的是解决问题的时候还得不停的回复boss们的询问,更坑爹的是其他的SRE没有任何的协作机制,看他一人在那忙死,没有丝毫的互备机制,老大们似乎也不觉着这是个巨大的问题。 有再强大的监控体系,但没有协同作战的意识,这样团队里的成员哪来的团队荣誉感 这套On-call响应机制很棒,应该是团队不停的磨合和共创出来的
moqi在某某公司的运维小伙和我提起过,他们那的系统出了问题,SRE的第一件事是写故障报告,第二件事是解决问题,坑爹的是解决问题的时候还得不停的回复boss们的询问,更坑爹的是其他的SRE没有任何的协作机制,看他一人在那忙死,没有丝毫的互备机制,老大们似乎也不觉着这是个巨大的问题。 有再强大的监控体系,但没有协同作战的意识,这样团队里的成员哪来的团队荣誉感 这套On-call响应机制很棒,应该是团队不停的磨合和共创出来的作者回复: 很好的关于感受的分享。 特别是第一段,应该是我们要极力避免的状态和情况。
2020-03-3027 旭东(Frank)熟悉某个系统的最快最好的方式就是参与 On-Call,而不是看架构图和代码。 这块感觉应该是精通系统细节
旭东(Frank)熟悉某个系统的最快最好的方式就是参与 On-Call,而不是看架构图和代码。 这块感觉应该是精通系统细节作者回复: 在炮火中磨炼,会成长的更快,对于细节的了解也会更深入。
2020-04-034 牧野静风对于中小型企业的我们来说,运维能做的就是做好各种监控体系,尽可能在用户反馈问题之前监控到故障,进行恢复。我们的做法是,每个项目有个Leader,出问题运维,开发,DBA协同处理,小团队这样配合解决问题还是挺快的。但是以前遇到过凌晨出现问题,各种人员Call不上,所以我们上线尽量放在周一到周四
牧野静风对于中小型企业的我们来说,运维能做的就是做好各种监控体系,尽可能在用户反馈问题之前监控到故障,进行恢复。我们的做法是,每个项目有个Leader,出问题运维,开发,DBA协同处理,小团队这样配合解决问题还是挺快的。但是以前遇到过凌晨出现问题,各种人员Call不上,所以我们上线尽量放在周一到周四作者回复: 变更是“万恶之源”,所以人员不容易聚集的情况下,尽量避免变更是合理的策略。
2020-05-073 daniel_yc从事一线运维工作6年了,最大的感受就是能力强的能被累死,我们行业比较特殊,基本上每个大的客户现场都有人驻守,加上客户自己的保障人员。有完整的on-call流程,奇葩的是,出现问题,第一反应是找能力强的人来解决,而当时当班的人只是用来传话的。。这就导致能力强的人被累死,基本上没周末没假期。。。。
daniel_yc从事一线运维工作6年了,最大的感受就是能力强的能被累死,我们行业比较特殊,基本上每个大的客户现场都有人驻守,加上客户自己的保障人员。有完整的on-call流程,奇葩的是,出现问题,第一反应是找能力强的人来解决,而当时当班的人只是用来传话的。。这就导致能力强的人被累死,基本上没周末没假期。。。。作者回复: 我遇到过很多这样的情况,其实这不是个人的问题了,这个是公司或机制的问题,应该要能轮转起来,并且一定周期内得对故障或问题的发生有容忍度才可以。另外,对于发生的问题或故障,要有分级才可以,不然啥问题过来都要立即马上处理,这种对oncall的同事来说,压力过大。
2020-05-043 Sports第一次听赵成老师的声音,还挺有磁性的,哈哈
Sports第一次听赵成老师的声音,还挺有磁性的,哈哈作者回复: 谢谢! 其实内容也很有料,是吗?^_^
2020-03-302 wholly看完老师的课程,很想从开发转岗到SRE,感觉很刺激😂
wholly看完老师的课程,很想从开发转岗到SRE,感觉很刺激😂作者回复: 不经历磨难,怎么见光明。不一定要转岗,但是开发过程中要多跟SRE交流学习,时间长了,你就是具备SRE意识和能力的开发。
2020-03-302- Helioson—call和监控,我感觉是鸡生蛋蛋生鸡的问题。首先oncall不能没有监控作为基础,要不然只能靠人工反馈了,单纯有监控没有oncall不能及时解决问题。 监控对事故复盘有很好的作用,能完善oncall的指标,oncall反过来也能促进监控的发展,又是相辅相成的关系。 但是如果这两个都没有的情况下,先建设哪一个。 这个时候业务量不大,可以先建设监控,然后根据客服用户反馈解决事故,通过事故复盘增加oncall机制。
作者回复: 非常好的分享,最终我们要学会两条腿走路,这才是最关键的。
2020-04-041

