

09 | 生产者消息分区机制原理剖析
该思维导图由 AI 生成,仅供参考
为什么分区?
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

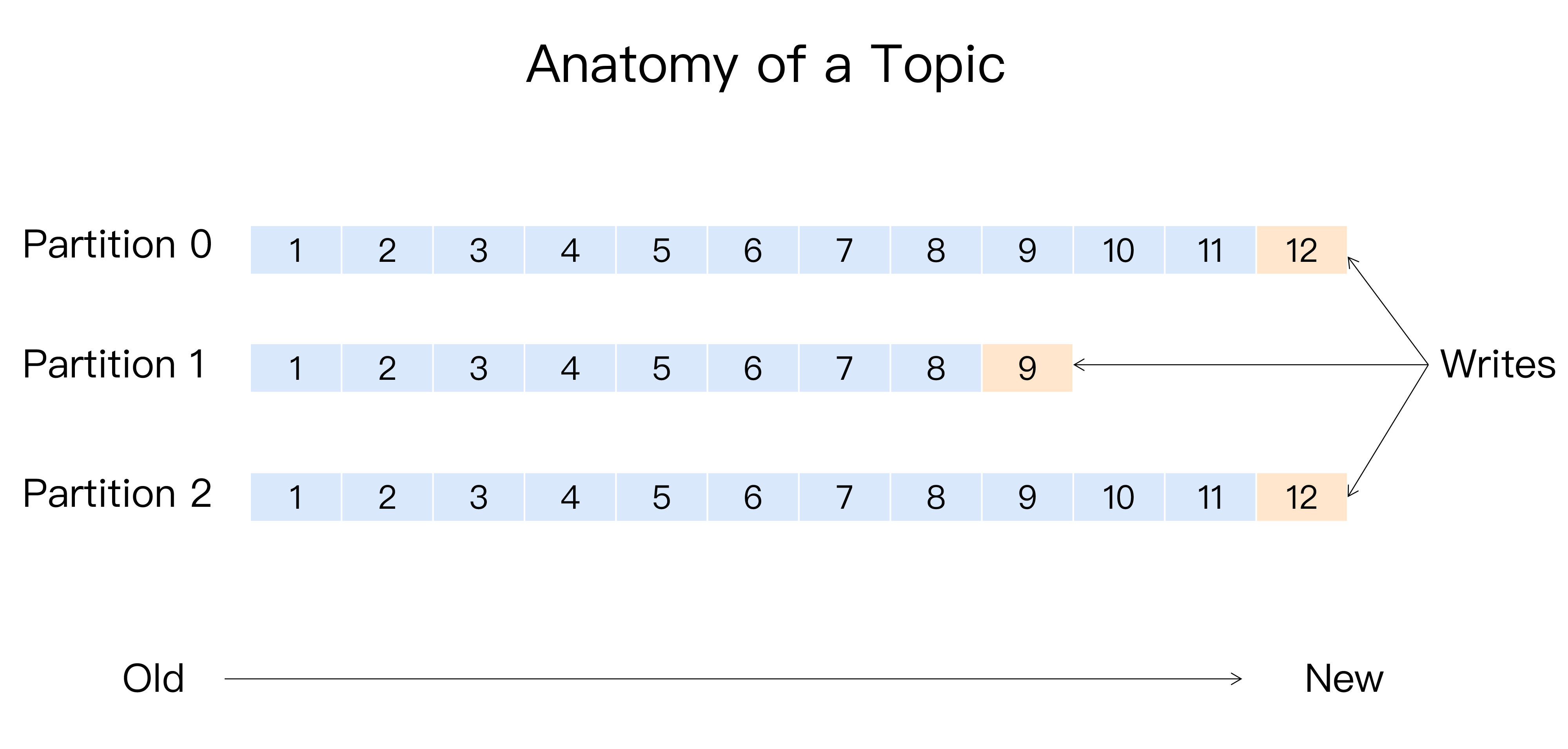
Kafka消息分区策略是实现负载均衡和高吞吐量的关键。本文深入探讨了Kafka如何实现数据均匀分配到所有服务器的需求。首先介绍了Kafka分区的概念和其在系统高伸缩性和负载均衡方面的重要作用。作者以Java API为例,分析了Kafka生产者如何实现数据均匀分配到各个Broker的过程。文章还提到了分区在不同分布式系统中的叫法以及分区在实现负载均衡以外的其他业务级需求方面的应用。常见的分区策略包括轮询策略、随机策略和按消息键保序策略。作者还分享了一个真实案例,强调了自定义分区策略对性能的提升。最后,文章提出了基于地理位置的分区策略,并强调了选择合适的分区策略避免消息数据的“倾斜”,从而避免性能瓶颈和下游数据消费的性能下降。整体而言,本文通过深入浅出的方式,帮助读者理解了Kafka如何利用分区实现数据均匀分配到所有服务器的关键技术特点。
《Kafka 核心技术与实战》,新⼈⾸单¥68

全部留言(149)
- 最新
- 精选
 QQ怪我们公司一直使用单个分区保持消息顺序性,看了老师分享的东西收益很多啊,准备回去好好分析改造下
QQ怪我们公司一直使用单个分区保持消息顺序性,看了老师分享的东西收益很多啊,准备回去好好分析改造下作者回复: 我们公司之前也有一个业务是单分区,要保证全局顺序。后来发现其实使用key+多分区也可以实现。反正保证同一批因果依赖的消息分到一个分区就可以
2019-06-22446 Adol老师好,在消息重试的时候,分区策略会重新再计算一次吗?比如一开始选择到5号分区,但是5号分区有问题导致重试,重试的时候可以重试发送到别的分区上吗?
Adol老师好,在消息重试的时候,分区策略会重新再计算一次吗?比如一开始选择到5号分区,但是5号分区有问题导致重试,重试的时候可以重试发送到别的分区上吗?作者回复: 不会的。消息重试只是简单地将消息重新发送到之前的分区
2019-06-23443 jc9090kkk感谢老师的分享,对于按消息键保序策略有一个疑问,假如我现在的业务数据定义了三个key,但是这三个key对应的消息生产速率不一致,按照老师上面的示意图展示的是,特定的key只会存储在特定的一个分区中,那岂不是牺牲了拓展性么,如果其中一个key的生产速率非常大,而另外2个key没那么大,却会一直占用分区,不会造成分区的空间浪费吗?还是我理解的有问题吗?希望老师解答一下,谢谢
jc9090kkk感谢老师的分享,对于按消息键保序策略有一个疑问,假如我现在的业务数据定义了三个key,但是这三个key对应的消息生产速率不一致,按照老师上面的示意图展示的是,特定的key只会存储在特定的一个分区中,那岂不是牺牲了拓展性么,如果其中一个key的生产速率非常大,而另外2个key没那么大,却会一直占用分区,不会造成分区的空间浪费吗?还是我理解的有问题吗?希望老师解答一下,谢谢作者回复: 嗯嗯,是有这样的问题。所以其实在生产环境中用key做逻辑区分并不太常见。如果不同key速率相差很大,可以考虑使用不同的topic
2019-09-20337 hgf老师您好,跨地区的kafka集群,创建的两个partition都在一个地方怎么办呢?创建topic时可以选择在哪些节点上创建partition吗?默认是随机选择节点创建partition吗?
hgf老师您好,跨地区的kafka集群,创建的两个partition都在一个地方怎么办呢?创建topic时可以选择在哪些节点上创建partition吗?默认是随机选择节点创建partition吗?作者回复: 可以选择。kafka-topics支持在创建topic时指定partition放在那些broker上
2019-07-1032 风轻扬老师,我见到有网友提问,说是消费者出现reblance的情况时。key-ordering策略可能会导致消费了“因“,reblance之后,无法消费 “果“。您给出的建议是,显示设置consumer端参数partition.assignment.strategy。这个设置。是不是只要使用了key保序策略,就一定要设置上呢?消费过程中出现reblance是很正常的啊
风轻扬老师,我见到有网友提问,说是消费者出现reblance的情况时。key-ordering策略可能会导致消费了“因“,reblance之后,无法消费 “果“。您给出的建议是,显示设置consumer端参数partition.assignment.strategy。这个设置。是不是只要使用了key保序策略,就一定要设置上呢?消费过程中出现reblance是很正常的啊作者回复: 嗯嗯,可能我没说清楚。如你说所rebalance是非常常见,如果再要求消费时消息有明确前后关系,这个就很复杂了。常见的做法是单分区来保证前后关系,但是这可能不符合很多使用场景。 我给出了另一个建议,就是设置partition.assignment.strategy=Sticky,这是因为Sticky算法会最大化保证消费分区方案的不变更。假设你的因果消息都有相同的key,那么结合Sticky算法有可能保证即使出现rebalance,要消费的分区依然有原来的consumer负责。
2019-07-28726 WL老师能不能有空能不能讲讲kafka和rocketMQ的对比, 我用下来感觉整体挺像的但是具体使用场景和性能优劣方面还是有点不知道该使用选择, 谢谢.
WL老师能不能有空能不能讲讲kafka和rocketMQ的对比, 我用下来感觉整体挺像的但是具体使用场景和性能优劣方面还是有点不知道该使用选择, 谢谢.作者回复: 之前也曾经回答过,不一定客观,姑且听之。在我看来RocketMQ与Kafka的主要区别 :1. Kafka吞吐量大,多是面向大数据场景。RocketMQ吞吐量也很强, 不过它号称是金融业务级的消息中间件,也就是说可以用于实际的业务系统;2. RocketMQ毕竟是阿里出品,在国内技术支持力度要比Kafka强;3. Kafka现在主要发力Streaming,RocketMQ在流处理这块表现如何我不太清楚,至少streaming不是它现阶段的主要卖点。 其他方面这两者确实都差不多~~
2019-06-22219 嘉嘉☕老师好, 关于生产消息, 我有个问题请教一下老师. 生产者生产消息, 采用轮询策略, 假如轮询到分区A了, 分区A的leader所在的broker有些异常(比如不能及时给出响应), 此时, kafka的重试机制是怎样的 ? 谢谢
嘉嘉☕老师好, 关于生产消息, 我有个问题请教一下老师. 生产者生产消息, 采用轮询策略, 假如轮询到分区A了, 分区A的leader所在的broker有些异常(比如不能及时给出响应), 此时, kafka的重试机制是怎样的 ? 谢谢作者回复: 只会重试发送到相同的分区
2019-11-2817- 海贼王感觉这篇文章没有回答怎么保证分区里数据和生产者消息顺序是一致这个问题。 这里有两个例子:1是,一个生产者,发两次消息,但是网络原因,消息到达的顺序和消息发送的顺序不一致,2是两个生产者,这时候消息如何确定消息的顺序呢。 场景1在做CDC,同步数据库数据到异构数据系统很常见 场景2对某些业务很重要 对于第一种,我的一个思路是保证只有一个生产者,且设置生产者的ack为all级别 对于场景2就不知道kafka能怎么做了。 希望老师能解惑
作者回复: 1. 防止乱序可以通过设置max.in.flight.requests.per.connection=1来保证 2. 两个生产者生产的消息无法保证顺序,因为它们本身就没有前后之分,它们是并发的关系。
2019-07-07714  我已经设置了昵称广州机房怎么消费广州partition的数据,consumer如何指定消费的partition。这个能讲下吗
我已经设置了昵称广州机房怎么消费广州partition的数据,consumer如何指定消费的partition。这个能讲下吗作者回复: 使用这个方法:consumer.assign()直接消息指定分区
2019-06-2214- Geek_b809ff老师,想请教几个问题: 1、key是不是必须得完全一样,才能保证会发送到同一个分区? 2、如果kafka搭了集群,有三个broker,分别是broker1、broker2、broker3。这时候我对名称为test的topic发送消息,key设置为A,消息会随机发送到三个broker上去吗?那这样的话顺序不就乱了吗?如果我想保证所有的消息都顺序,是不是需要指定发送到其中一个broker?
作者回复: 1. 根据默认分区策略,同一个key的消息肯定会发送到同一个分区 2. 首先,你的消息会被发送到某个分区的leader副本上。这个分区的leader副本只能存在于3个broker中的一个,但是如果test的副本数是3,那么一条消息也会被备份到其他两个broker上。只是只有leader副本对外提供服务,因此没有顺序乱的情况出现。 3. 如果想保证顺序,指定消息key即可,这样能保证分送到同一个分区上。是否发到同一个broker上无关紧要
2019-08-29212

