

08 | 键入网址再按下回车,后面究竟发生了什么?

该思维导图由 AI 生成,仅供参考
使用 IP 地址访问 Web 服务器
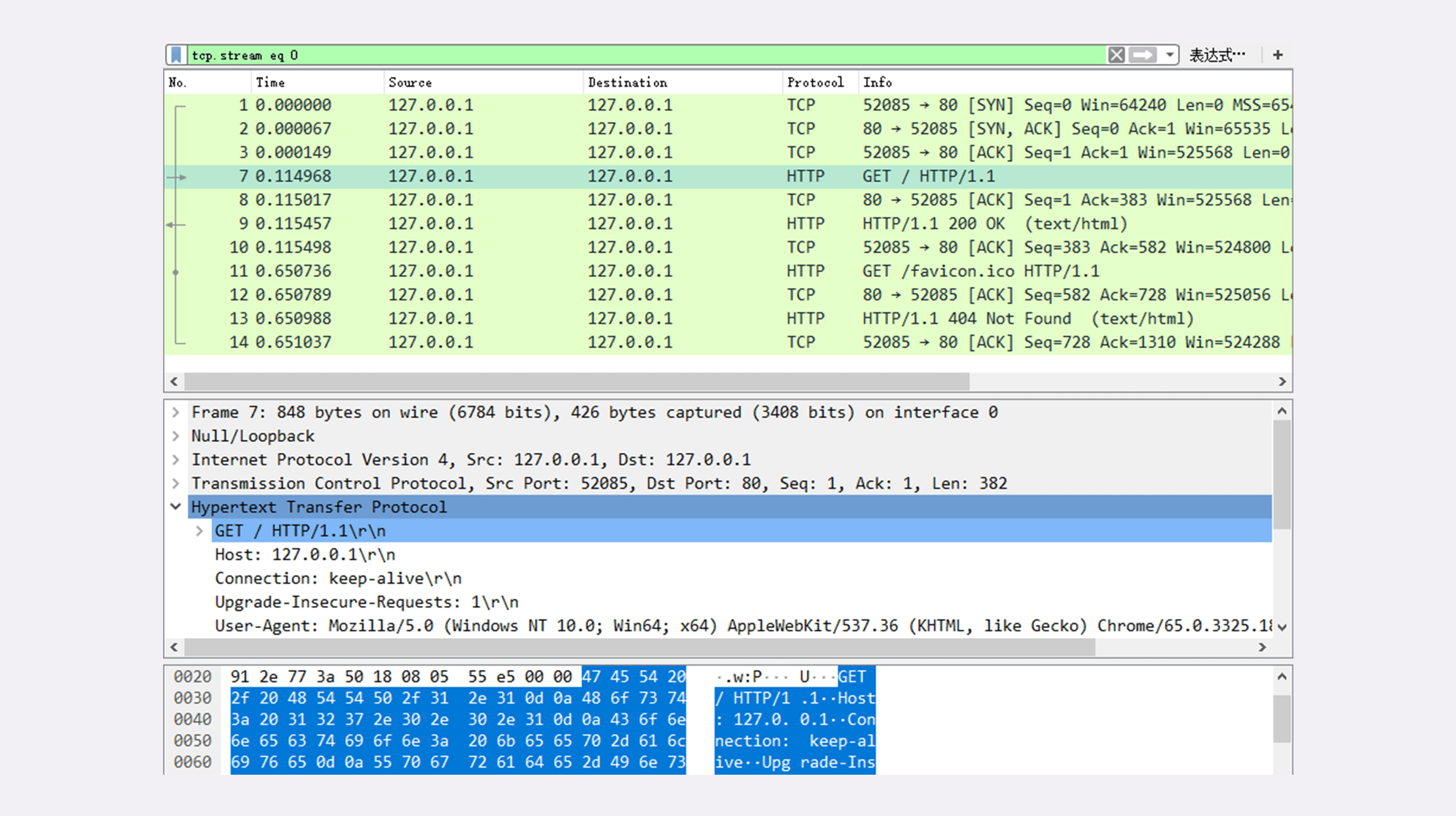
抓包分析
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文通过实际操作和Wireshark抓包分析,详细介绍了在浏览器中键入网址并按下回车后,HTTP协议的全过程。首先解释了使用IP地址访问Web服务器的过程,包括TCP连接的建立、HTTP请求报文的发送、服务器的响应以及页面渲染的过程。接着讲解了使用域名访问Web服务器的过程,重点介绍了域名解析的原理和浏览器如何通过DNS解析获取域名对应的IP地址。文章通过抓包分析和图示,生动地展现了HTTP协议在浏览器中的工作流程,帮助读者深入理解了网络通信的细节和原理。 文章通过实验和图示生动地展现了HTTP协议在浏览器中的工作流程,帮助读者深入理解了网络通信的细节和原理。从简单的两点模型到真实的互联网世界,文章详细介绍了HTTP协议请求-应答的全过程,包括TCP连接的建立、HTTP请求报文的发送、服务器的响应以及页面渲染的过程。此外,文章还涉及了DNS解析、CDN服务器、负载均衡设备等复杂网络环境下的工作原理,为读者呈现了更加全面的网络通信知识。 总之,本文通过实例和详细解释,使读者对HTTP协议的工作流程有了基本的认识,同时也引发了读者对于浏览器点击页面链接后的工作流程和对于不存在域名的处理流程的思考。
《透视 HTTP 协议》,新⼈⾸单¥59

全部留言(118)
- 最新
- 精选
 -W.LI-浏览器判断是不是ip地址,不是就进行域名解析,依次通过浏览器缓存,系统缓存,host文件,还是没找到的请求DNS服务器获取IP解析(解析失败的浏览器尝试换别的DNS服务器,最终失败的进入错误页面),有可能获取到CDN服务器IP地址,访问CDN时先看是否缓存了,缓存了响应用户,无法缓存,缓存失效或者无缓存,回源到服务器。经过防火墙外网网管路由到nginx接入层。ng缓存中存在的直接放回,不存在的负载到web服务器。web服务器接受到请后处理,路径不存在404。存在的返回结果(服务器中也会有redis,ehcache(堆内外缓存),disk等缓存策略)。原路返回,CDN加入缓存响应用户。
-W.LI-浏览器判断是不是ip地址,不是就进行域名解析,依次通过浏览器缓存,系统缓存,host文件,还是没找到的请求DNS服务器获取IP解析(解析失败的浏览器尝试换别的DNS服务器,最终失败的进入错误页面),有可能获取到CDN服务器IP地址,访问CDN时先看是否缓存了,缓存了响应用户,无法缓存,缓存失效或者无缓存,回源到服务器。经过防火墙外网网管路由到nginx接入层。ng缓存中存在的直接放回,不存在的负载到web服务器。web服务器接受到请后处理,路径不存在404。存在的返回结果(服务器中也会有redis,ehcache(堆内外缓存),disk等缓存策略)。原路返回,CDN加入缓存响应用户。作者回复: 说的非常详细。
2019-06-14294 晴天老师,我有一个问题请教。 DNS域名解析不需要发请求,建立连接吗?本地缓存的dns除外。 比如我第一次访问一个域名abc.com,那这第一次不是需要从dns服务器上拿真正的IP吗,去拿IP的这个过程不是应该也是一个请求吗?这个请求又是什么请求呢?
晴天老师,我有一个问题请教。 DNS域名解析不需要发请求,建立连接吗?本地缓存的dns除外。 比如我第一次访问一个域名abc.com,那这第一次不是需要从dns服务器上拿真正的IP吗,去拿IP的这个过程不是应该也是一个请求吗?这个请求又是什么请求呢?作者回复: dns请求是专门的dns协议,使用udp发送,因为是udp所以不需要建立连接。
2019-08-0651 郭凯强作业: 1. 浏览器判断这个链接是要在当前页面打开还是新开标签页,然后走一遍本文中的访问过程:拿到ip地址和端口号,建立tcp/ip链接,发送请求报文,接收服务器返回并渲染。 2. 先查浏览器缓存,然后是系统缓存->hosts文件->局域网域名服务器->广域网域名服务器->顶级域名服务器->根域名服务器。这个时间通常要很久,最终找不到以后,返回一个报错页面,chrome是ERR_CONNECTION_ABORTED
郭凯强作业: 1. 浏览器判断这个链接是要在当前页面打开还是新开标签页,然后走一遍本文中的访问过程:拿到ip地址和端口号,建立tcp/ip链接,发送请求报文,接收服务器返回并渲染。 2. 先查浏览器缓存,然后是系统缓存->hosts文件->局域网域名服务器->广域网域名服务器->顶级域名服务器->根域名服务器。这个时间通常要很久,最终找不到以后,返回一个报错页面,chrome是ERR_CONNECTION_ABORTED作者回复: 回答的比较全面。 这里面还有个长连接的问题,后面会讲,如果连接还是本站就不会有建连过程,直接用已有的连接发请求。
2019-06-14426 极客时间老师 我有个疑问,第四个包到第六个包,为什么又进行了一次tcp连接呢,而且这个端口号是52086,这个是浏览器的特性吗,仔细比对文章发现这个问题啊
极客时间老师 我有个疑问,第四个包到第六个包,为什么又进行了一次tcp连接呢,而且这个端口号是52086,这个是浏览器的特性吗,仔细比对文章发现这个问题啊作者回复: 因为http/1连接传输效率低,所以浏览器一般会对同一个域名发起多个连接提高效率,这个52086就是开的第二个连接,但在抓包中只是打开了,还没有传输。 到后面讲长连接的时候你就会明白了。
2019-06-14424 肥low1、如果域名不是ip,需要走域名解析成ip的逻辑,优先级顺序为: 1 浏览器缓存 > 2 本地hosts > 3 系统缓存 > 4 根域名 > 5 顶级dns服务器(如 com) > 6 二级dns服务器(baidu.com) > 7 三级dns服务器(www.baidu.com),如果客户端指向的dns服务器为非官方的如 8.8.8.8,那在第4步之前可能还有一层cache,当然最后解析的ip有可能是cdn的,如果cdn失效了就直接穿透到源ip,当然这个服务器这一部分可能做了四层负载均衡的设置,所以有可能每次获取的服务器ip都不一祥,也有可能到了服务器ngx层做了七层转发,所以虽然获得的ip一样,但是内部可能转发给了很多内网服务器 2、通过中间各种路由器的转发,找到了最终服务器,进行tcp三次握手,数据请求,请求分两种一种是uri请求,一种是浏览器咸吃萝卜淡操心的请求网站图标ico的资源请求,然后服务端收到请求后进行请求分析,最终返回http报文,再通过tcp这个连接隧道返回给用户端,用户端收到后再告诉服务端已经收到结果的信号(ack),然后客户端有一套解析规则,如果是html,可能还有额外的外部连接请求,是跟刚才的请求流程是同理的(假设是http1.1),只不过没有了tcp三次握手的过程,最终用户看到了百度的搜索页面。当然如果dns没解析成功,浏览器直接就报错了,不会继续请求接下来的资源
肥low1、如果域名不是ip,需要走域名解析成ip的逻辑,优先级顺序为: 1 浏览器缓存 > 2 本地hosts > 3 系统缓存 > 4 根域名 > 5 顶级dns服务器(如 com) > 6 二级dns服务器(baidu.com) > 7 三级dns服务器(www.baidu.com),如果客户端指向的dns服务器为非官方的如 8.8.8.8,那在第4步之前可能还有一层cache,当然最后解析的ip有可能是cdn的,如果cdn失效了就直接穿透到源ip,当然这个服务器这一部分可能做了四层负载均衡的设置,所以有可能每次获取的服务器ip都不一祥,也有可能到了服务器ngx层做了七层转发,所以虽然获得的ip一样,但是内部可能转发给了很多内网服务器 2、通过中间各种路由器的转发,找到了最终服务器,进行tcp三次握手,数据请求,请求分两种一种是uri请求,一种是浏览器咸吃萝卜淡操心的请求网站图标ico的资源请求,然后服务端收到请求后进行请求分析,最终返回http报文,再通过tcp这个连接隧道返回给用户端,用户端收到后再告诉服务端已经收到结果的信号(ack),然后客户端有一套解析规则,如果是html,可能还有额外的外部连接请求,是跟刚才的请求流程是同理的(假设是http1.1),只不过没有了tcp三次握手的过程,最终用户看到了百度的搜索页面。当然如果dns没解析成功,浏览器直接就报错了,不会继续请求接下来的资源作者回复: 非常详细,赞!!
2019-06-17613- 极客时间我有几个小疑问没搞明白,万望老师解答, 在进行DNS解析的时候,操作系统和本地DNS是如何处理的呢? 我的理解是本地系统有可能有缓存,DNS解析前先查看本地有没有缓存,如果没有缓存,再进行本地DNS解析,本地DNS解析就是查找系统里面的hosts文件的对应关系。不知道这里理解的对不对。 还有一个疑问。 什么是权威DNS呢,我一般是在万网购买域名,然后用A记录解析到我的服务器,这个A记录提交到哪里保存了呢,这里的万网扮演的是什么角色呢?它和权威DNS有关系吗? 上次我提到了一个问题,就是域名和ip的对应关系,没接触这个课程以前,我的理解是一个域名只能解析到一个ip地址,但是一个ip地址可以绑定多个域名,就像一个人只有一个身份证号码,但是可以有多个名字,但是我在用ping命令 ping‘ baidu.com’ 时,发现 可以返回不同的ip,结合本课程前面的文章,我理解是百度自己的服务器本质是一台DNS服务器,用DNS做了负载均衡,当我访问baidu.com时,域名解析过程中,有一个环节是到达了百度的DNS服务器,然后DNS服务器根据负载均衡操作,再将我的请求转发给目标服务器。不知道理解的对不对,或者哪里有偏差。
作者回复: 本地dns你的理解是正确的。 万网是个域名注册的代理机构,最终域名还是要由dns系统来解析。 百度的理解基本正确,在真正服务器前面是dns负载均衡。
2019-06-14412  四月的紫色花1.你能试着解释一下在浏览器里点击页面链接后发生了哪些事情吗? 浏览器点击页面请求后,正常网络中都是域名,那么浏览器会先用DNS解析一下,拿到服务器的ip和端口,去请求服务器前会先找一下缓存,浏览器自己的缓存-操作系统缓存-本地缓存(Hosts),都没有的话就会到根域名服务器-顶级-权威,当然中间可能有类似CDN这样的代理,那它就可以取CDN中的服务器地址,总的来说,其实就是个“走近道”的过程,就近原则,在DNS不错的情况下,先从离自己近的查起,再一级一级往下。 2.这一节课里讲的都是正常的请求处理流程,如果是一个不存在的域名,那么浏览器的工作流程会是怎么样的呢? 如果是一个不存在的域名,那浏览器还是会从DNS那解析一下,发现,自己,操作系统,本地的缓存都没有,CDN里也没有,根域名,顶级域名,权威域名,非权威域名里 都没有,那它就放弃了,不会建立链接,返回错误码,可能是4××类的客户端请求错误。
四月的紫色花1.你能试着解释一下在浏览器里点击页面链接后发生了哪些事情吗? 浏览器点击页面请求后,正常网络中都是域名,那么浏览器会先用DNS解析一下,拿到服务器的ip和端口,去请求服务器前会先找一下缓存,浏览器自己的缓存-操作系统缓存-本地缓存(Hosts),都没有的话就会到根域名服务器-顶级-权威,当然中间可能有类似CDN这样的代理,那它就可以取CDN中的服务器地址,总的来说,其实就是个“走近道”的过程,就近原则,在DNS不错的情况下,先从离自己近的查起,再一级一级往下。 2.这一节课里讲的都是正常的请求处理流程,如果是一个不存在的域名,那么浏览器的工作流程会是怎么样的呢? 如果是一个不存在的域名,那浏览器还是会从DNS那解析一下,发现,自己,操作系统,本地的缓存都没有,CDN里也没有,根域名,顶级域名,权威域名,非权威域名里 都没有,那它就放弃了,不会建立链接,返回错误码,可能是4××类的客户端请求错误。作者回复: 回答的很认真,鼓励一下。 第二个问题后面有误,因为dns解析失败,根本没有进入http处理流程,所以不会有4xx之类的错误,而是dns解析错误信息。
2019-07-30210 keep it simple老师,学习这一章萌生出几个问题: 1.如果在TCP连接保持的情况下某一方突然断电了,没有机会进行TCP 四次挥手,会出现什么情况呢? 2.如果不主动关浏览器,TCP连接好像一直存在着,会有超时时间吗?中间是否会保活? 3.若server端负载较高,当它收到client的SYN包时,是否要过一段时间才会回应SYN,ACK?
keep it simple老师,学习这一章萌生出几个问题: 1.如果在TCP连接保持的情况下某一方突然断电了,没有机会进行TCP 四次挥手,会出现什么情况呢? 2.如果不主动关浏览器,TCP连接好像一直存在着,会有超时时间吗?中间是否会保活? 3.若server端负载较高,当它收到client的SYN包时,是否要过一段时间才会回应SYN,ACK?作者回复: 1.tcp收发数据有超时机制,超时没有响应就会断开连接,当然这个就不是正常的结束连接。 2.tcp收发有超时,连接本身没有超时机制,http使用keepalive在tcp上实现了连接保活。 3.tcp建连是在操作系统内核里实现的,有一个处理队列,如果并发的请求太多,就会排队等待。 4.这些问题涉及的都是tcp比较底层的细节,我也不能很好的解释清楚,建议再去参考其他的资料,sorry。
2019-11-277- 陈1016第一个问题的回答:浏览器缓存、系统缓存、hosts文件、野生DNS服务器(本地DNS服务器)、根DNS、顶级DNS、权威DNS、本地(附近)CDN、源站。
作者回复: √
2019-06-2727  Maske1.如果链接地址是域名开头的,浏览器会开始DNS解析动作。解析优先级依次为:浏览器缓存 > 操作系统缓存 > 本机hosts文件 > “野生DNS服务器” >核心DNS服务器( 根级DNS > 顶级DNS > 权威DNS) ;将域名解析为正确的ip地址之后,通过三次握手与服务器建立tcp/ip连接;浏览器发送请求报文,服务器接收并处理请求,返回响应报文,浏览器开始解析html文档,在这过程中又会发起一些http请求,进行图片、css、js等静态资源的获取,以及ajax请求获取json数据。同时,浏览器相关引擎开始绘制dom视图,执行js脚本,完成页面的初始化直到所有代码执行完毕。 2.如1中所说DNS解析顺序,当请求DNS服务器进行域名解析时,发现没有找到对应的ip,会导致解析失败,无法建立tcp/ip链接,导致浏览器建立连接时间过长,最终建立连接失败,浏览器停止建立连接动作。
Maske1.如果链接地址是域名开头的,浏览器会开始DNS解析动作。解析优先级依次为:浏览器缓存 > 操作系统缓存 > 本机hosts文件 > “野生DNS服务器” >核心DNS服务器( 根级DNS > 顶级DNS > 权威DNS) ;将域名解析为正确的ip地址之后,通过三次握手与服务器建立tcp/ip连接;浏览器发送请求报文,服务器接收并处理请求,返回响应报文,浏览器开始解析html文档,在这过程中又会发起一些http请求,进行图片、css、js等静态资源的获取,以及ajax请求获取json数据。同时,浏览器相关引擎开始绘制dom视图,执行js脚本,完成页面的初始化直到所有代码执行完毕。 2.如1中所说DNS解析顺序,当请求DNS服务器进行域名解析时,发现没有找到对应的ip,会导致解析失败,无法建立tcp/ip链接,导致浏览器建立连接时间过长,最终建立连接失败,浏览器停止建立连接动作。作者回复: 说的非常好!
2020-06-085

