





你将获得
- 10+ 篇必读经典论文精讲
- 大数据系统底层知识学习路径
- 10 年大数据老兵的实战心法
- 工业级数据系统迭代方案
课程介绍
大数据领域,可以说是过去 20 年计算机工程界发展最迅速、产生影响最大的一个领域。很多看起来和“大数据”没有什么关系的开源系统,都是从“大数据”这个领域里培育出来的,比如说 Kubernetes。
那么,今天我们去研读“大数据”领域的经典论文,可以说是一件投入产出比很高的事情。通过学习大数据相关的论文,我们会对计算机工程的各个领域都有更加深刻的认知,这不仅仅是对于“大数据工程师”这样的职位有用,对于做各类后端开发和系统开发的工程师来说,都会有很大的帮助。
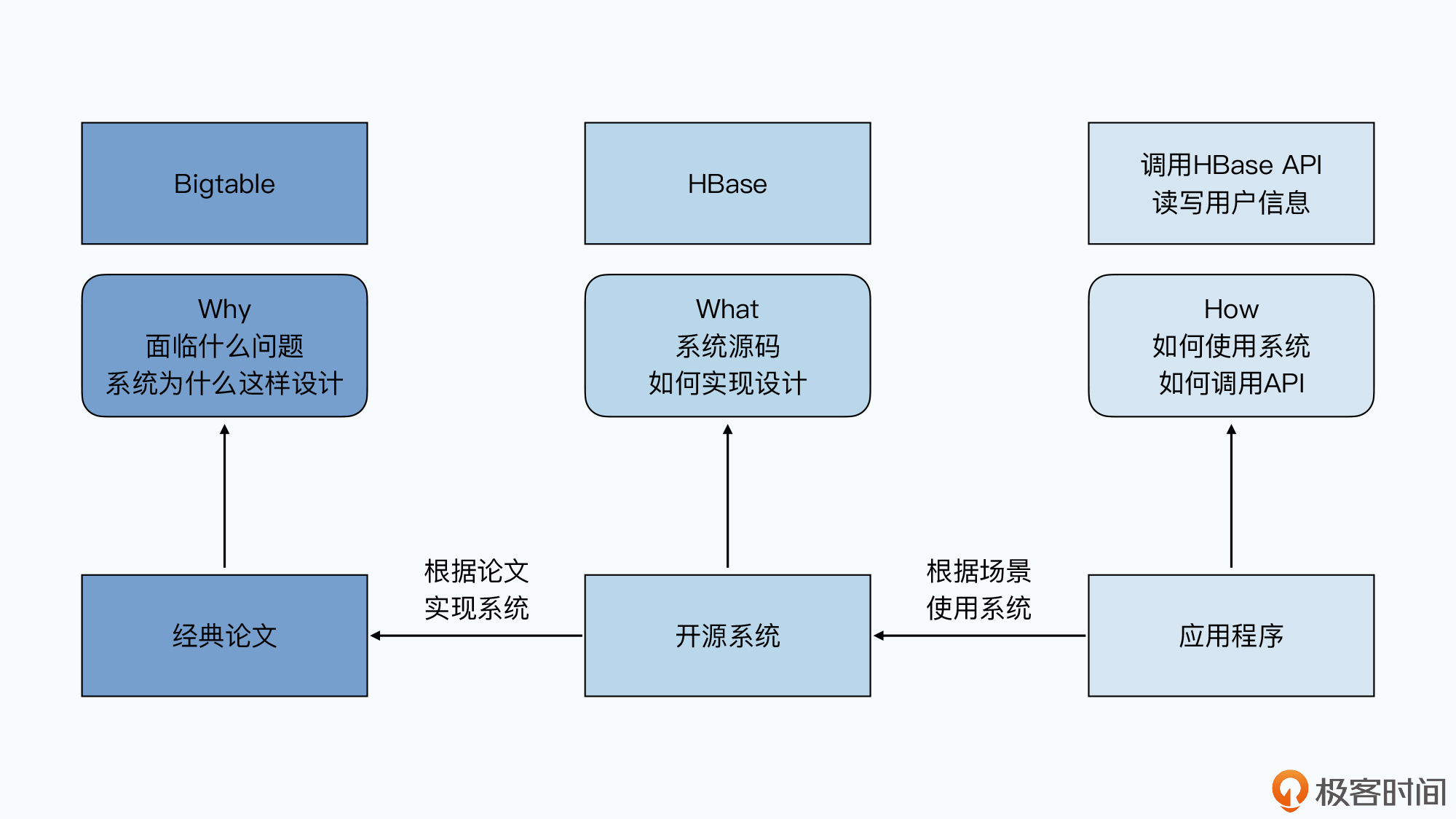
但是我们应该怎么学呢?在网上随便一搜,虽然也能找到不少论文被人翻译成了中文,但是往往也只能告诉你“是什么”,却没有办法让你理解“为什么”。这些翻译或者文章,常常给出的是“Bigtable 系统是一个稀疏的、分布式的排序好的 Map”,却让你没有办法让你理解为什么 Bigtable 是这样设计的。
所以这次,我们邀请了极客时间《深入浅出计算机组成原理》课程的作者徐文浩老师,通过他十多年研读论文、使用各种开源框架解决大数据问题的经验,带你梳理整个大数据系统的发展脉络,为你分析在整个领域的系统不断往前迭代的过程中,所遇到的具体场景下的问题,还会深入解读其中重要的设计决策背后,能够联系到的计算机底层原理。
这样一来,通过课程内容知识的讲解,你就能够把论文和论文之间联系起来,把论文和具体技术场景联系起来,把论文和计算机原理的底层知识点联系起来。更进一步,你会真正理解 Why,而不是只知道 What。
课程模块设计
课程主体划分为以下 5 大模块。
- 基础知识篇:从最经典的 Google 三驾马车 GFS、MapReduce 和 Bigtable 这三篇论文开始,帮你理解大数据系统面对的主要挑战,以及应对这些挑战的架构设计方法。进一步地,会带你一起来看大数据系统依赖的分布式锁 Chubby、序列化和 RPC 方案 Thrift,让你能够将架构设计和计算机结合到一起,掌握好计算机科学的底层原理。
- 数据库篇:一方面来研读 Hive、Dremel 和 Spark 的相关论文,了解工程师们是怎么迭代改进 MapReduce,从而满足海量数据下的高性能分析需求。另一方面,你还会了解 Megastore 和 Spanner,从而明白如何在 Bigtable 的基础架构上,逐步添加 Schema、跨行事务,直至完成了一个跨数据中心的分布式数据库。
- 实时处理篇:结合 Storm、Kafka 以及 Dataflow,你会了解到现代大数据的实时处理系统是怎么逐步迭代,做到流批一体,达成批量和实时数据处理的统一的。
- 资源调度篇:通过解读 Raft、Borg 和 Kubernetes 的论文,你能够厘清如何尽可能在一个数据中心里,合理地压榨资源、调度系统。
- 实战应用篇:学以致用,通过剖析 Facebook 数据仓库的逐步演进变化,以及 Twitter 如何使用大数据进行机器学习,你就能理解如何通过分析问题、理解架构,将所学到的大数据知识串联起来。这样你在未来面对新的问题时,也能够找到精巧的解决方案。
另外,在解读每篇论文的过程中,编辑还会带你一起来回顾课程内容,进一步巩固知识要点,帮助扩展大数据领域技术知识面,同时也会分享一些阅读论文的小技巧,让你不仅有所学、有所思,更让你有所用。
课程目录

查看更多
免费试读
特别放送
免费领取福利

讲师

徐文浩
bothub 创始人
编辑推荐

讲师的其他课程



看过的人还看了







