05|实现多层神经网络
Sebastian Raschka

在前几节中,我们介绍了 PyTorch 的张量(tensor)和自动微分(autograd)组件。本节将聚焦于 PyTorch 作为一个用于实现深度神经网络的库(所具备的功能)。
为了给出一个具体示例,我们将重点介绍多层感知机——这是一种全连接神经网络,如图 1 所示。
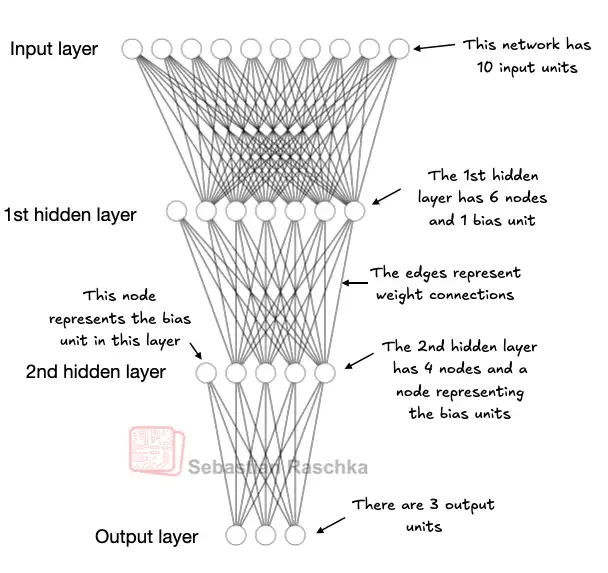
图 1:具有两个隐藏层的多层感知机(MLP)结构示意图。图中每个节点代表对应层中的计算单元,为清晰展示结构,各层仅包含极少量单元(实际网络规模远大于此)。
在 PyTorch 中实现神经网络时,我们通常通过继承 torch.nn.Module 类来自定义网络架构。这个 Module 基类提供了许多功能,使得构建和训练模型变得更加容易。例如,它允许我们封装层和操作,并跟踪模型的参数。
在这个子类中,我们在 __init__ 构造函数中定义网络层,并在 forward 方法中指定它们如何交互。forward 方法描述了输入数据如何通过网络并作为一个计算图汇集起来。
相比之下,反向传播方法通常不需要我们自己实现,在训练过程中用于计算损失函数相对于模型参数的梯度,正如我们在 07 讲“典型的训练循环”中所看到的。
以下代码实现了一个具有两个隐藏层的经典多层感知机,以说明 Module 类的典型用法:
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

1. PyTorch通过继承`torch.nn.Module`类来自定义网络架构,使用`Module`类提供的功能简化模型构建和训练过程。 2. 在实现多层感知机时,可以使用`Sequential`类封装层和操作,并在`forward`方法中指定输入数据如何通过网络并作为一个计算图汇集起来。 3. 通过实例化一个新的神经网络对象并调用`print`函数来查看模型的结构概览,以便了解模型的层次结构和参数数量。 4. 可训练参数包含在`torch.nn.Linear`层中,其中权重矩阵和偏置向量可以通过相应的属性访问。 5. 用小的随机数初始化模型权重是为了在训练过程中打破对称性,可以通过`manual_seed`为PyTorch的随机数生成器设置种子,使随机数初始化具有可重复性。 6. 前向传播是指从输入张量计算输出张量的过程,通过调用模型进行前向传播可以得到相应的输出张量。 7. 在使用模型进行推理而不是训练时,最佳实践是使用`torch.no_grad()`上下文管理器,告诉PyTorch无需跟踪梯度,从而节省内存和计算资源。 8. PyTorch中通常将模型设计为返回最后一层的输出(logits),而不将其传递给非线性激活函数,以提高数值计算的效率和稳定性。 9. 如果需要计算预测结果的类别概率,可以显式调用softmax函数来得到相应的概率值。 10. 常用的损失函数会将softmax操作与负对数似然损失结合在一个单独的类中,以提高数值计算的效率和稳定性。
该试读文章来自《1 小时入门 PyTorch:从张量到多 GPU 神经网络训练》,如需阅读全部文章,
请先领取课程
请先领取课程
免费领取
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论