
10|纵向扩展(下):怎样通过架构优化提高单机性能?
谢友鹏

你好,我是谢友鹏。
在前两节课中,我们分别从应用层代码和网络模型、协议的角度探讨了如何提升单机性能,今天我们将进入单机性能优化的第三个层面,讨论如何简化处理路径或用硬件为 CPU 分担压力,来进一步提升性能。
瓶颈来源
我们先看一下应用程序通过 Linux 内核发送和接收一个网络包的主要流程。
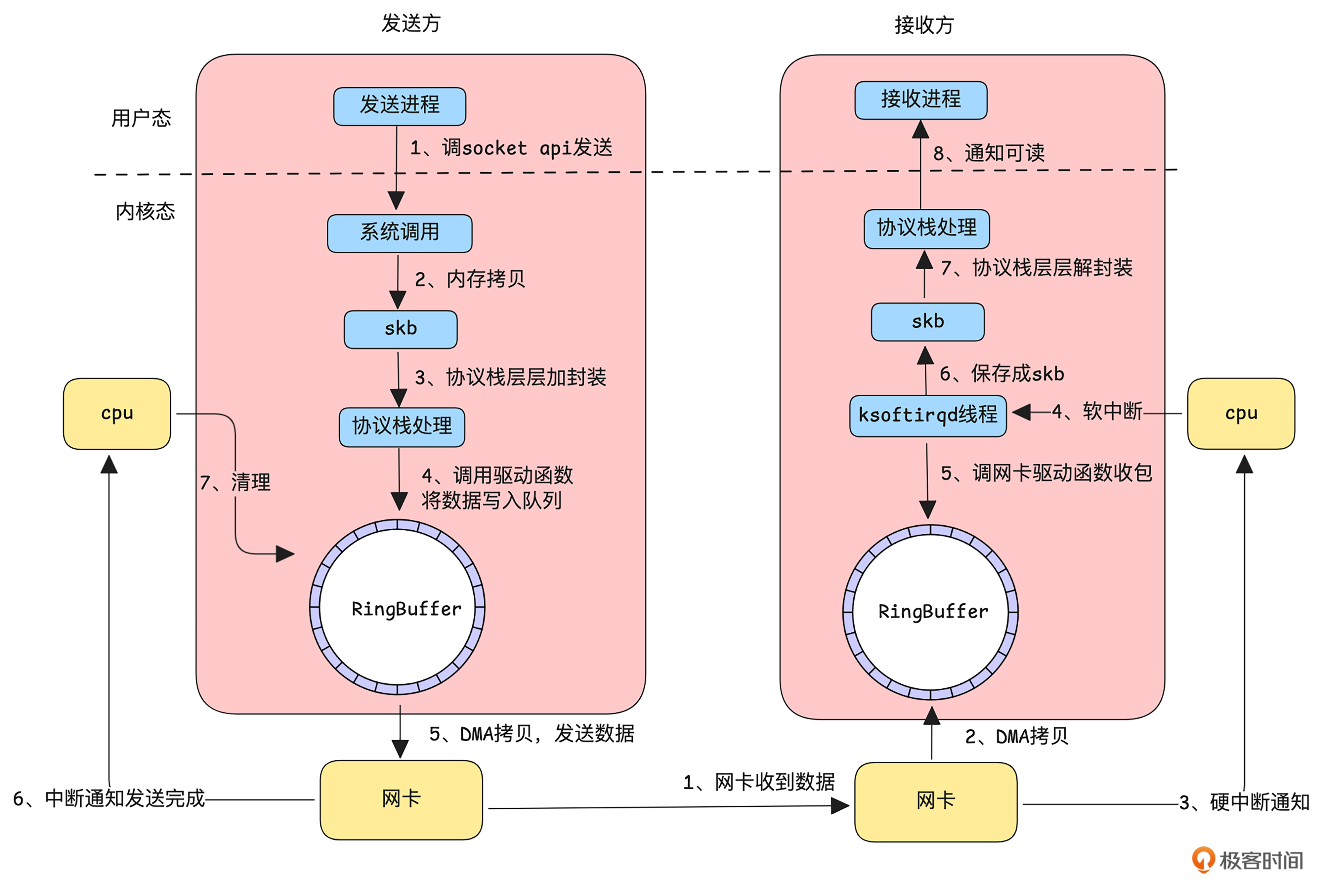
如上图所示,发送方一个数据包要经过以下流程。
发送方的应用程序通过调用 socket API 告知内核有数据要发送,随后进入系统调用,完成从用户态到内核态的切换。
内核态接收到数据后,将其拷贝到 skb(socket buffer)结构中,供协议栈处理。
协议栈对数据进行分片、封装等处理。
经过协议栈处理的数据通过驱动程序将数据到 RingBuffer。
调用网卡发送函数,此时网卡利用 DMA 将数据从 RingBuffer 拷贝到网卡缓存并开始发送。
发送成功后(TCP 需等待接收到 ACK),网卡通过中断通知 CPU,
CPU 再清理 RingBuffer 中的数据。
接收方收到一个数据包到通知应用进程数据可读,要经过以下流程:
网卡接收到数据。
网卡通过 DMA 将数据直接拷贝到 RingBuffer。
网卡通过硬中断通知 CPU 有新数据到达。
简单处理后,触发软中断通知专用线程进行处理。
软中断处理线程调用网卡驱动从 RingBuffer 中读取数据包
数据被保存成 skb 结构。
数据进入协议栈,经过解封装等处理。
处理完成后,内核通知应用程序有数据可读。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

1. DPDK(Data Plane Development Kit)通过绕过内核协议栈,在用户态直接处理网络数据,提高数据处理性能。 2. DPDK提供高效的库和驱动,允许应用程序直接访问网卡硬件,绕过传统的Linux内核协议栈,降低上下文切换和数据拷贝的开销。 3. eBPF(Extended Berkeley Packet Filter)技术在内核层面提供了Verfier和JIT功能,使得用户态应用能够在内核运行自定义的沙箱程序,扩展内核功能。 4. 通过软硬件结合,将一部分网络处理工作卸载到其他硬件,或将转发面进一步拆分成“快平面”和“慢平面”两部分,以提升性能。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《网络架构实战课》,新⼈⾸单¥59
《网络架构实战课》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论