当我们在分析程序性能时,获取程序所运行的时间是个基本的条件。
只有得到准确的运行时间,才能分析、定位哪里是程序的瓶颈,再针对瓶颈进行优化。如果这个数据获取错了,那么接下去的优化方向大概率也是错的。
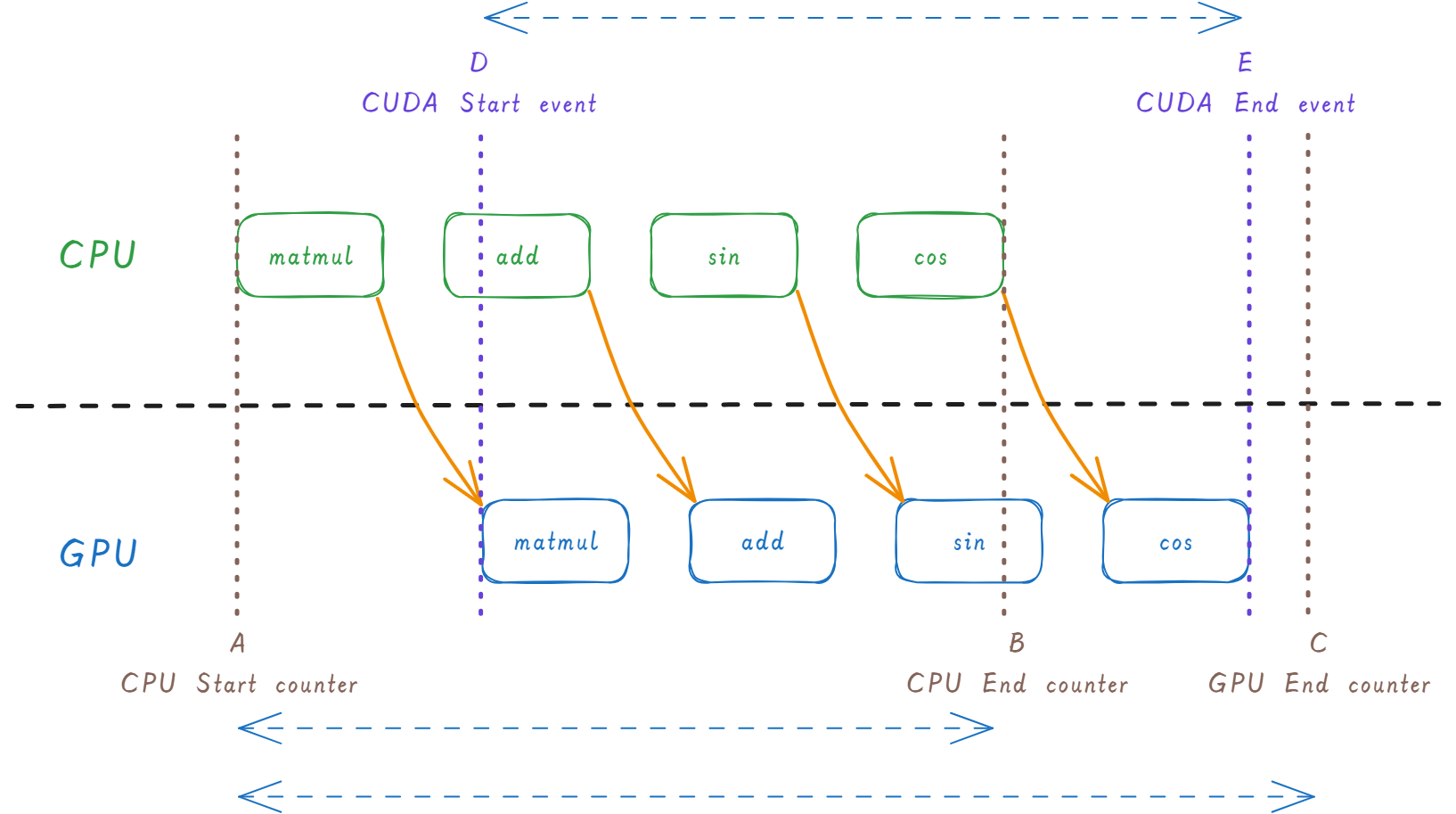
一图胜千言,先看一张图:
图里面,CPU 侧创建了四个算子,然后下发给 GPU 进行计算。
需要牢记的是,PyTorch 采用了异步的运行机制。CPU 把算子 (即 CUDA 的 Kernel 函数) 提交到 GPU 的任务队列 (即 CUDA Stream),然后 CPU 就不管了;GPU 自己从 stream 中取出算子、逐个执行。在这个过程中,CPU 并不会等待 GPU 执行完算子之后再返回。
如果 CPU 需要等待 GPU 执行完成,则需要调用:
torch.cuda.synchronize()
如果使用华为昇腾,对应的方法是:
torch.npu.synchronize()
在图中,A 点的 CPU Start Counter,对应的是 CPU 侧开始计时;
B 点的 CPU End Counter,对应的是 CPU 侧已经把所有的算子提交到 GPU。但至于算子是否执行完毕,它是不管的;
C 点的 GPU End Counter,对应的是 GPU 侧已经完成所有算子的计算,然后 synchronize。这个时间点,才是算子执行结束的位置;
D 点的 CUDA Start Event,是 GPU 真正开始执行算子的位置;
E 点的 CUDA End Event,则是 GPU 完成算子计算的位置。相比 C 点,E 点少了同步所消耗的时间。但同步一般都比较快,所以理论上,C 点和 E 点的差距不大。
所以,图中的 B - A,对应的是 CPU 完成算子下发的时间,不能用它来测量性能。
图中的 C - A,对应的是 CPU 算子下发 + GPU 执行算子的时间,可以用来测量性能,虽然略有偏差。
图中的 E - D,对应的是 GPU 执行算子的时间,可以用来精确的测量性能。
我们通过代码来验证、对比这三个时间差。
import torch
import time
def time_span_comparision():
dim = 512
repeat = 10
warmup = 5
shape = (dim, dim, dim)
a = torch.randn(shape, dtype=torch.float, device='cuda:0')
b = torch.randn(shape, dtype=torch.float, device='cuda:0')
for _ in range(warmup):
c = a * b
d = a + b
e = torch.sin(a)
f = torch.cos(b)
torch.cuda.synchronize()
start_counter = time.perf_counter()
start_event = torch.cuda.Event(enable_timing=True)
end_event = torch.cuda.Event(enable_timing=True)
start_event.record()
for _ in range(repeat):
c = a * b
d = a + b
e = torch.sin(a)
f = torch.cos(b)
end_event.record()
cpu_end_counter = time.perf_counter()
torch.cuda.synchronize()
gpu_end_counter = time.perf_counter()
cpu_average = (cpu_end_counter - start_counter)/repeat*1000
gpu_average = (gpu_end_counter - start_counter)/repeat*1000
event_average = start_event.elapsed_time(end_event)/repeat
print(f'Average CPU time span: {cpu_average:.6f} ms')
print(f'Average GPU time span: {gpu_average:.6f} ms')
print(f'Average CUDA event span: {event_average:.6f} ms')
if __name__ == '__main__':
time_span_comparision()
执行这个文件,可以得到如下输出:
Average CPU time span: 0.051276 ms
Average GPU time span: 9.741018 ms
Average CUDA event span: 9.733418 ms
可以看到:
CPU 下发算子所用的时间 0.051276(图中的 B - A),和 CPU 算子下发 + GPU 完成计算所用的时间 9.741018,有巨大的差异 (图中的 C - A);
CPU 算子下发 + GPU 完成计算所用的时间 9.741018(图中的 C - A),和 GPU 执行算子的时间 9.733418(图中的 E - D) 相差不大。如果重复执行算子的次数越大,那么差距还会继续缩小。
所以,在测量运行时间的时候,我们只能采用 C - A,或者 E - D;绝不可以使用 B - A。
另外,代码里面还有个 warmup 的对比,如果把 warmup 改成 0,不进行热身,会得到下面的结果:
Average CPU time span: 4.782449 ms
Average GPU time span: 13.679880 ms
Average CUDA event span: 13.671930 ms
可以看到,在测量之前是否先进行热身运动,对于性能数据有很大影响。
为了得到稳定的性能数据,建议先 warmup、再测量。这涉及到设备初始化、指令缓存、数据缓存、算子编译等诸多因素,先不展开了。