
02. Java字节码技术:不积细流,无以成江河(2)
kimmking
4.5 查看方法信息
在 javap 命令中使用 -verbose 选项时, 还显示了其他的一些信息。例如, 关于 main 方法的更多信息被打印出来:
可以看到方法描述: ([Ljava/lang/String;)V:
其中小括号内是入参信息 / 形参信息,
左方括号表述数组,
L 表示对象,
后面的 java/lang/String 就是类名称
小括号后面的 V 则表示这个方法的返回值是 void
方法的访问标志也很容易理解 flags: ACC_PUBLIC, ACC_STATIC,表示 public 和 static
还可以看到执行该方法时需要的栈 (stack) 深度是多少,需要在局部变量表中保留多少个槽位, 还有方法的参数个数: stack=2, locals=2, args_size=1。把上面这些整合起来其实就是一个方法:
public static void main(java.lang.String[]);
注:实际上我们一般把一个方法的修饰符 + 名称 + 参数类型清单 + 返回值类型,合在一起叫“方法签名”,即这些信息可以完整的表示一个方法。
稍微往回一点点,看编译器自动生成的无参构造函数字节码:
你会发现一个奇怪的地方, 无参构造函数的参数个数居然不是 0: stack=1, locals=1, args_size=1。这是因为在 Java 中, 如果是静态方法则没有 this 引用。 对于非静态方法, this 将被分配到局部变量表的第 0 号槽位中, 关于局部变量表的细节, 下面再进行介绍。
有反射编程经验的同学可能比较容易理解: Method#invoke(Object obj, Object... args); 有 JavaScript 编程经验的同学也可以类比: fn.apply(obj, args) && fn.call(obj, arg1, arg2);
4.6 线程栈与字节码执行模型
想要深入了解字节码技术,我们需要先对字节码的执行模型有所了解。
JVM 是一台基于栈的计算机器。每个线程都有一个独属于自己的线程栈 (JVM stack),用于存储栈帧(Frame)。每一次方法调用,JVM 都会自动创建一个栈帧。栈帧 由 操作数栈, 局部变量数组 以及一个class引用组成。class引用 指向当前方法在运行时常量池中对应的 class)。
我们在前面反编译的代码中已经看到过这些内容。
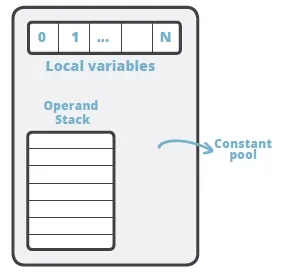
局部变量数组 也称为 局部变量表(LocalVariableTable), 其中包含了方法的参数,以及局部变量。 局部变量数组的大小在编译时就已经确定: 和局部变量 + 形参的个数有关,还要看每个变量 / 参数占用多少个字节。操作数栈是一个 LIFO 结构的栈, 用于压入和弹出值。 它的大小也在编译时确定。
有一些操作码 / 指令可以将值压入“操作数栈”; 还有一些操作码 / 指令则是从栈中获取操作数,并进行处理,再将结果压入栈。操作数栈还用于接收调用其他方法时返回的结果值。
4.7 方法体中的字节码解读
看过前面的示例,细心的同学可能会猜测,方法体中那些字节码指令前面的数字是什么意思,说是序号吧但又不太像,因为他们之间的间隔不相等。看看 main 方法体对应的字节码:
间隔不相等的原因是, 有一部分操作码会附带有操作数, 也会占用字节码数组中的空间。例如, new 就会占用三个槽位: 一个用于存放操作码指令自身,两个用于存放操作数。因此,下一条指令 dup 的索引从 3 开始。
如果将这个方法体变成可视化数组,那么看起来应该是这样的:

每个操作码 / 指令都有对应的十六进制 (HEX) 表示形式, 如果换成十六进制来表示,则方法体可表示为 HEX 字符串。例如上面的方法体百世成十六进制如下所示:

甚至我们还可以在支持十六进制的编辑器中打开 class 文件,可以在其中找到对应的字符串:
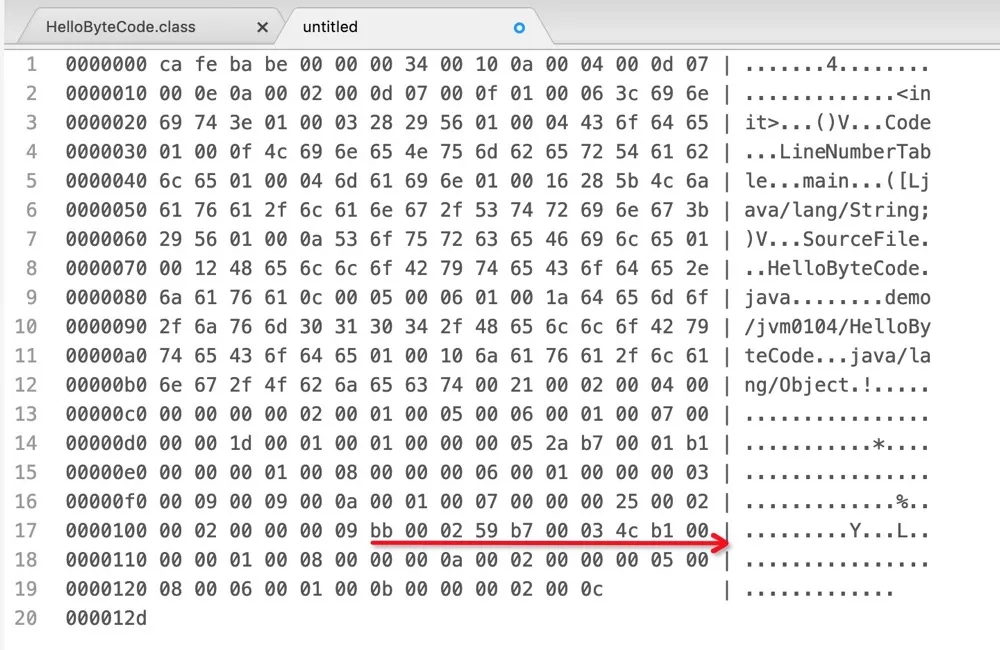
(此图由开源文本编辑软件 Atom 的 hex-view 插件生成)
粗暴一点,我们可以通过 HEX 编辑器直接修改字节码,尽管这样做会有风险, 但如果只修改一个数值的话应该会很有趣。
其实要使用编程的方式,方便和安全地实现字节码编辑和修改还有更好的办法,那就是使用 ASM 和 Javassist 之类的字节码操作工具,也可以在类加载器和 Agent 上面做文章,下一节课程会讨论 类加载器,其他主题则留待以后探讨。
4.8 对象初始化指令:new 指令, init 以及 clinit 简介
我们都知道 new是 Java 编程语言中的一个关键字, 但其实在字节码中,也有一个指令叫做 new。 当我们创建类的实例时, 编译器会生成类似下面这样的操作码:
当你同时看到 new, dup 和 invokespecial 指令在一起时,那么一定是在创建类的实例对象!
为什么是三条指令而不是一条呢?这是因为:
new 指令只是创建对象,但没有调用构造函数。
invokespecial 指令用来调用某些特殊方法的, 当然这里调用的是构造函数。
dup 指令用于复制栈顶的值。
由于构造函数调用不会返回值,所以如果没有 dup 指令, 在对象上调用方法并初始化之后,操作数栈就会是空的,在初始化之后就会出问题, 接下来的代码就无法对其进行处理。
这就是为什么要事先复制引用的原因,为的是在构造函数返回之后,可以将对象实例赋值给局部变量或某个字段。因此,接下来的那条指令一般是以下几种:
astore {N} or astore_{N} – 赋值给局部变量,其中 {N} 是局部变量表中的位置。
putfield – 将值赋给实例字段
putstatic – 将值赋给静态字段
在调用构造函数的时候,其实还会执行另一个类似的方法 <init></init> ,甚至在执行构造函数之前就执行了。还有一个可能执行的方法是该类的静态初始化方法 <clinit></clinit>, 但 <clinit></clinit> 并不能被直接调用,而是由这些指令触发的: new, getstatic, putstatic or invokestatic。
也就是说,如果创建某个类的新实例, 访问静态字段或者调用静态方法,就会触发该类的静态初始化方法【如果尚未初始化】。
4.9 栈内存操作指令
有很多指令可以操作方法栈。 前面也提到过一些基本的栈操作指令: 他们将值压入栈,或者从栈中获取值。 除了这些基础操作之外也还有一些指令可以操作栈内存; 比如 swap 指令用来交换栈顶两个元素的值。下面是一些示例:
最基础的是 dup 和 pop 指令。
dup 指令, 复制栈顶的值, 并将复制的值压入栈。
pop 指令则从栈中删除最顶部的值。
还有复杂一点的指令:比如,swap, dup_x1 和 dup2_x1。
顾名思义,swap 指令可交换栈顶两个元素的值,例如 A 和 B 交换位置 (图中示例 4);
dup_x1 指令, 复制栈顶的值, 并将复制的值插入到最上面 2 个值的下方。(图中示例 5);
dup2_x1 指令, 复制栈顶 1 个 64 位 / 或 2 个 32 位的值, 并将复制的值按照原始顺序,插入原始值下面一个 32 位值的下方 (图中示例 6)。
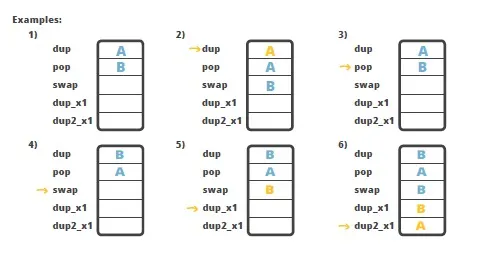
dup_x1 和 dup2_x1 指令看起来稍微有点复杂。而且为什么要设置这种指令呢? 在栈中复制最顶部的值?
请看一个实际案例:怎样交换 2 个 double 类型的值?
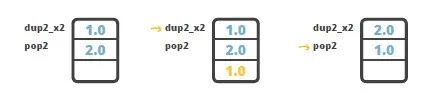
需要注意的是, 一个 double 值占两个槽位,也就是说如果栈中有两个 double 值,它们将占用 4 个槽位。
要执行交换,你可能想到了 swap 指令,但问题是 swap 只适用于单字 (one-word, 单字一般指 32 位 4 个字节, 64 位则是双字),所以不能处理 double 类型, 但 Java 中又没有 swap2 指令。
怎么办呢? 解决方法就是使用 dup2_x2指令, 将操作数栈顶部的 double 值, 复制到栈底 double 值的下方, 然后再使用 pop2 指令弹出栈顶的 double 值。结果就是交换了两个 double 值。示意图如下图所示:
dup, dup_x1, dup2_x1 指令补充说明
dup 指令
官方说明是: 复制栈顶的值, 并将复制的值压入栈.
操作数栈的值变化情况 (方括号标识新插入的值):
dup_x1 指令
官方说明是: 复制栈顶的值, 并将复制的值插入到最上面 2 个值的下方。
操作数栈的值变化情况 (方括号标识新插入的值):
dup2_x1 指令
官方说明是: 复制栈顶 1 个 64 位 / 或 2 个 32 位的值, 并将复制的值按照原始顺序,插入原始值下面一个 32 位值的下方。
操作数栈的值变化情况 (方括号标识新插入的值):
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《JVM 核心技术 100 讲 (尊享版)》
《JVM 核心技术 100 讲 (尊享版)》
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论