

13|组件监控:MySQL的关键指标及采集方法有哪些?

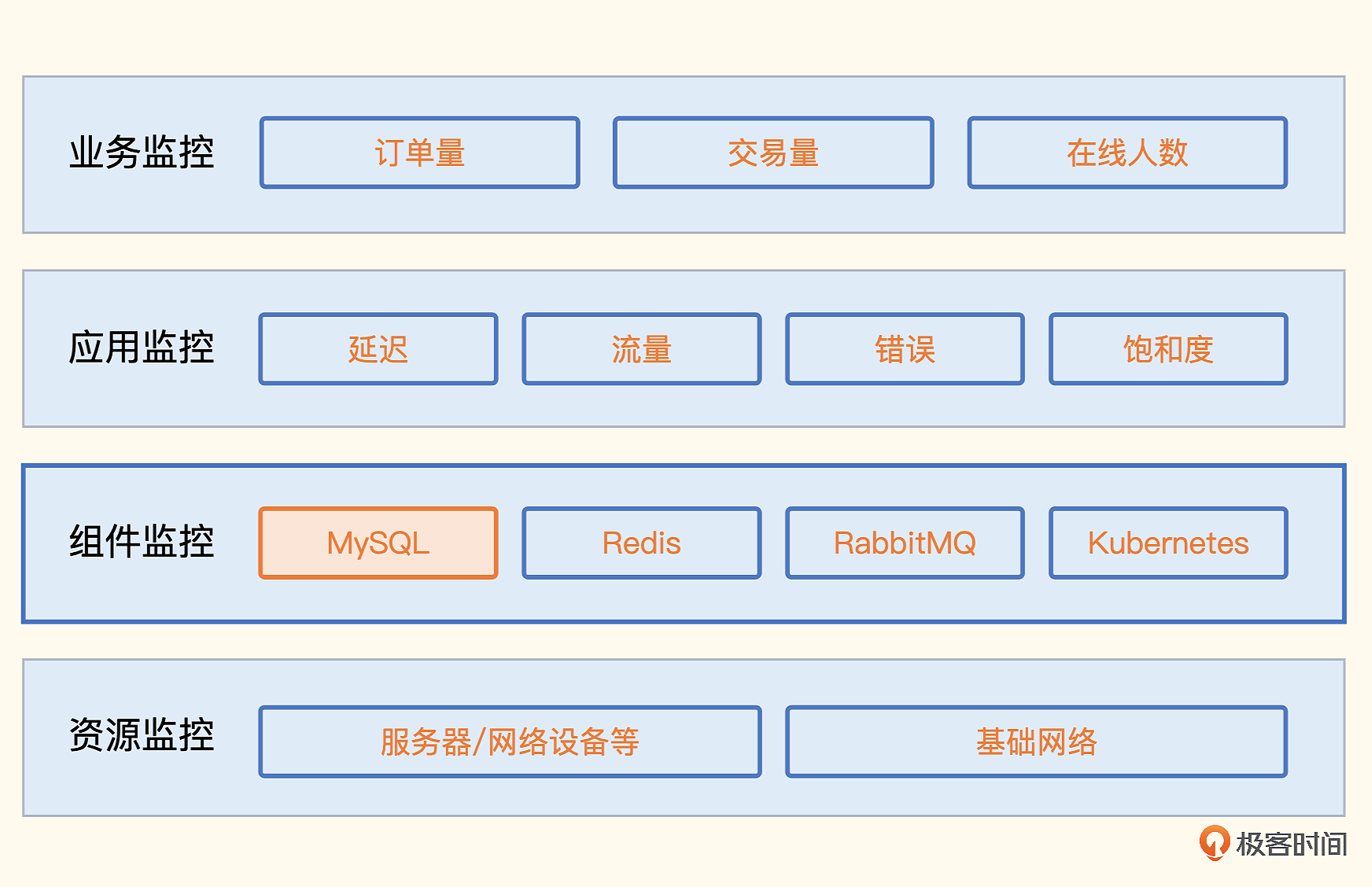
整体思路
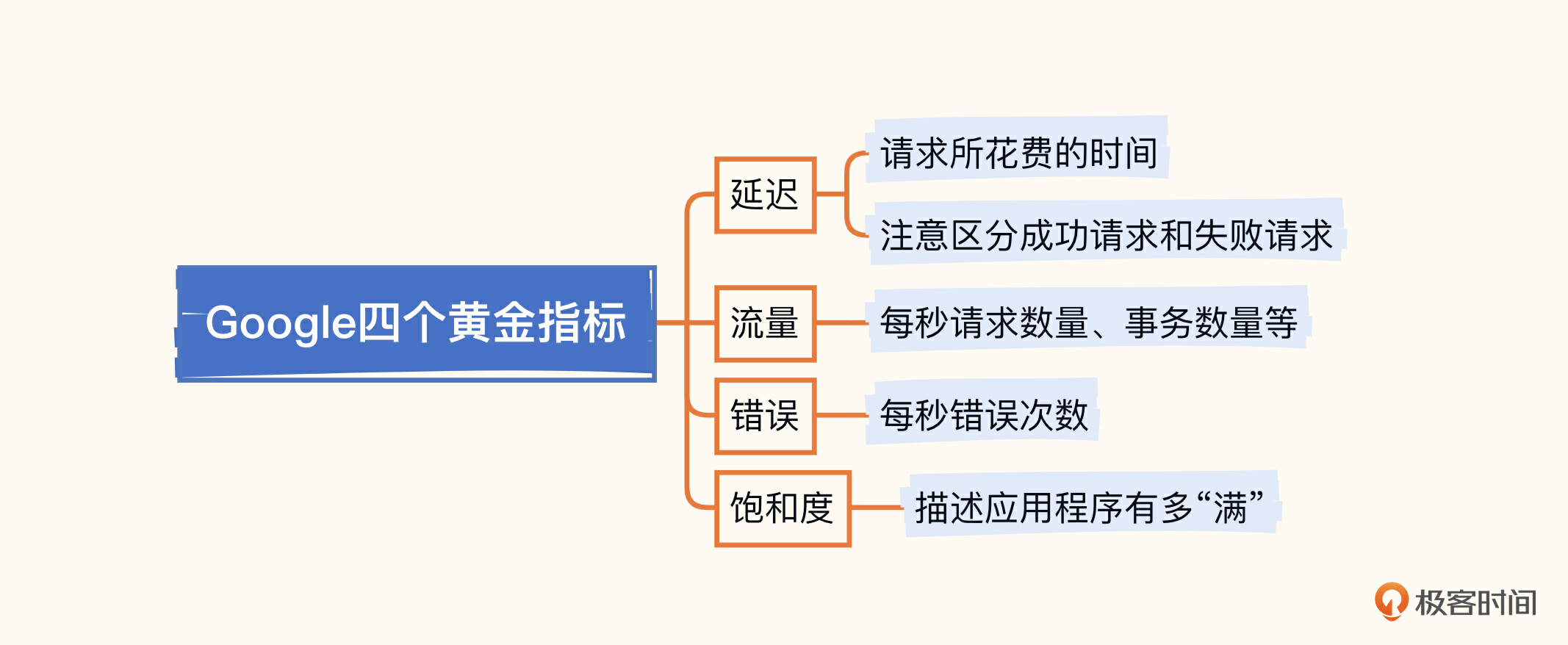
延迟
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文深入介绍了MySQL监控的关键指标及采集方法,包括监控思路、延迟、流量、错误量等方面的监控方法。针对延迟方面的监控,文章介绍了三种典型的采集方法,包括在客户端埋点、使用Slow queries和通过performance schema和sys schema拿到统计数据。对于流量方面的监控,文章提到了统计各类命令的执行次数,并给出了相应的示例。在错误量方面,文章介绍了两种典型的采集手段,包括在客户端采集、埋点和从MySQL中采集相关错误。此外,还介绍了调整最大连接数的方法以及通过events_statements_summary_by_digest表拿到错误数量的示例。文章还详细介绍了MySQL的饱和度指标和InnoDB Buffer pool相关的指标,以及Categraf针对MySQL的采集插件配置。最后,文章提到了业务指标的采集方法,包括自定义SQL的配置。整体而言,本文通过具体的指标和采集方法,为读者提供了实用的MySQL监控实战经验,对于需要深入了解MySQL监控的读者具有很高的参考价值。
《运维监控系统实战笔记》,新⼈⾸单¥59

全部留言(12)
- 最新
- 精选
 Camera秦老您好!想请教您两个问题: 1、项目要求需要做一套运维监控,想基于Prometheus来二开,请问作为产品(对运维没有相关经验),需要从哪方面下手来做产品设计呢? 2、运维系统的指标很多是需要通过配置文件配置,是否可将它可视化呢? 感谢老师指导一二!
Camera秦老您好!想请教您两个问题: 1、项目要求需要做一套运维监控,想基于Prometheus来二开,请问作为产品(对运维没有相关经验),需要从哪方面下手来做产品设计呢? 2、运维系统的指标很多是需要通过配置文件配置,是否可将它可视化呢? 感谢老师指导一二!作者回复: 1,从需求出发,先去访谈你的需求方 2,可以试试 github.com/ccfos/nightingale 这个项目,把告警规则、记录规则都可视化管理了
2023-02-06归属地:广东2 peter请教老师几个问题: Q1:怎么用 increase 函数计算慢查询的数量 Q2:MySQL最大连接数在生产环境中一般设置为多大? Q3:Innodb_buffer_pool_reads 是从缓存读吗? “reads 这个指标除以 read_requests 就得到了穿透比例”,从这句话看,此指标不是从缓存中读,而是从库里直接读(即从硬盘读)。但从名字看,似乎Innodb_buffer_pool_reads 应该是从缓存读。 Q4:中心化探测,categraf是只探测本身机器上的MySQL吗? 还是说既探测本机上的MySQL也探测其他机器上的MySQL? Q5:生产环境中MySQL不用docker或k8s吗? 这一句“因为生产环境里 MySQL 一般很少放到容器里跑”,从这句看,似乎生产环境中MySQL是手动部署,不用docker 或k8s,是吗? Q6:本专栏有学习微信群吗?
peter请教老师几个问题: Q1:怎么用 increase 函数计算慢查询的数量 Q2:MySQL最大连接数在生产环境中一般设置为多大? Q3:Innodb_buffer_pool_reads 是从缓存读吗? “reads 这个指标除以 read_requests 就得到了穿透比例”,从这句话看,此指标不是从缓存中读,而是从库里直接读(即从硬盘读)。但从名字看,似乎Innodb_buffer_pool_reads 应该是从缓存读。 Q4:中心化探测,categraf是只探测本身机器上的MySQL吗? 还是说既探测本机上的MySQL也探测其他机器上的MySQL? Q5:生产环境中MySQL不用docker或k8s吗? 这一句“因为生产环境里 MySQL 一般很少放到容器里跑”,从这句看,似乎生产环境中MySQL是手动部署,不用docker 或k8s,是吗? Q6:本专栏有学习微信群吗?作者回复: 前两个问题和另一个同学的重复了,你翻一下吧。 3,这个指标表示从硬盘读 4,中心化探测就是找一个机器部署categraf,用这个categraf探测你们公司的所有mysql实例 5,我看到的实践是很少放容器里,也有放的 6,专栏介绍页面,有高亮文字提示
2023-02-06归属地:北京2 乔纳森老师您好,怎么根据黄金指标计算组件的SLI呢?以MySQL为例
乔纳森老师您好,怎么根据黄金指标计算组件的SLI呢?以MySQL为例作者回复: 这是个好问题。网上没看到讨论。普通web服务的SLI通常制定为可用性、延迟、成功率。 对于mysql而言,可用性显然也是一个重要的SLI。 延迟,取决于sql复杂度,mysql自身倒是难以控制,没法作为一个SLI,不具有mysql建设指导意义。 成功率,典型的是客户端发的sql本身有问题所以报错(非mysql问题),连接数过多所以报错,最大连接数如果设置不合理是mysql的锅,如果设置合理了,还是连接数过多,就是上层业务的锅了。这个指标可以作为SLI,但具体故障定责的时候,还得case by case 的看。 另外,mysql是存储数据的,自身还要保证数据可靠性。可靠性应该要定指标。 综上,对mysql而言,最靠谱的SLI我感觉是可用性和可靠性。
2023-02-06归属地:广东21- Geek_81d2ba现在很多都开始使用云数据库,不再自己本机部署mysql了,这种情况下是不是业务方主要还是要主动探测数据库状态,另外我理解云上的数据库很多应该也是用容器化方式去部署的吧,一般这种云上的数据库监控采集难道是采用sidecar的方式吗
作者回复: 云上的rds的话,云监控会提供相关指标。如果云监控提供的指标不够,可以考虑自己做一些采集作为补充
2023-12-05归属地:江苏 - y和mysqld_exporter对比,Categraf有啥优势的地方呢?
作者回复: 单就某一个具体的中间件或者数据库的监控而言,其实区别不大,categraf 相当于把很多个 exporter 整合到一起了的感觉
2023-10-21归属地:广东  Roy Liang现在云时代了,最大连接数、innodb buffer pool大小等该调优的参数云产品都替我们做了,这种情况下我们需要重点关注哪些指标呢?
Roy Liang现在云时代了,最大连接数、innodb buffer pool大小等该调优的参数云产品都替我们做了,这种情况下我们需要重点关注哪些指标呢?作者回复: 文章中还提到了一些其他的项,比如slow_query、吞吐量之类的,监控大盘里配置的那些项也需要挨个梳理一下
2023-02-15归属地:广东 123请教老师一个问题,如果一个数据库服务里面有多个实例,在自定义业务指标时如何去制定对应的实例,并书写sql
123请教老师一个问题,如果一个数据库服务里面有多个实例,在自定义业务指标时如何去制定对应的实例,并书写sql作者回复: mysql是单实例的,多个实例是啥意思?通常要做区分度,都是通过附加标签的方式哈。比如 select 'n9e' as service, xxx from xx 这里就会在结果列里出现service列,value是n9e,此时就可以把service列设置为标签列
2023-02-14归属地:浙江 大叮当老师您好,请教两个问题: Q1:怎么用 increase 函数计算慢查询的数量? Q2:MySQL最大连接数在生产环境中一般设置为多大?
大叮当老师您好,请教两个问题: Q1:怎么用 increase 函数计算慢查询的数量? Q2:MySQL最大连接数在生产环境中一般设置为多大?作者回复: 1,前面介绍过promql的使用,慢查询的指标外层包一个increase函数,指定一个时间段,比如1m,就可以计算1m内的慢查询增量 2,http://www.mysqlcalculator.com/ 可以用这个工具来测算,连接越多,占用的内存越大。或者就简单点,直接把max_connections设置的巨大,然后观察其他指标,比如cpu、内存之类的在达到最大连接数之前肯定就先有问题了
2023-02-06归属地:中国香港 橙汁这段话 “表里的时间度量指标都是以皮秒为单位。”是毫秒吧,另外学到不少知识 相当于拿四个指标以mysql为案例讲了下监控思路,最后还给出实际解决方案夜莺监控 可直接用,思路清晰 牛逼。 以前:监控就那些玩意 基础层有云 都是云 不用做什么 现在:思考的更多 业务层也大有可为
橙汁这段话 “表里的时间度量指标都是以皮秒为单位。”是毫秒吧,另外学到不少知识 相当于拿四个指标以mysql为案例讲了下监控思路,最后还给出实际解决方案夜莺监控 可直接用,思路清晰 牛逼。 以前:监控就那些玩意 基础层有云 都是云 不用做什么 现在:思考的更多 业务层也大有可为作者回复: 是皮秒哈,没错的
2023-02-06归属地:北京2- Geek_be4f4d老师您好,脑图中的performance_schema 中的schema单词是否拼写错误了?2023-06-07归属地:北京

