

03|隐式传递:如何精准找出一次请求的全部日志?

 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

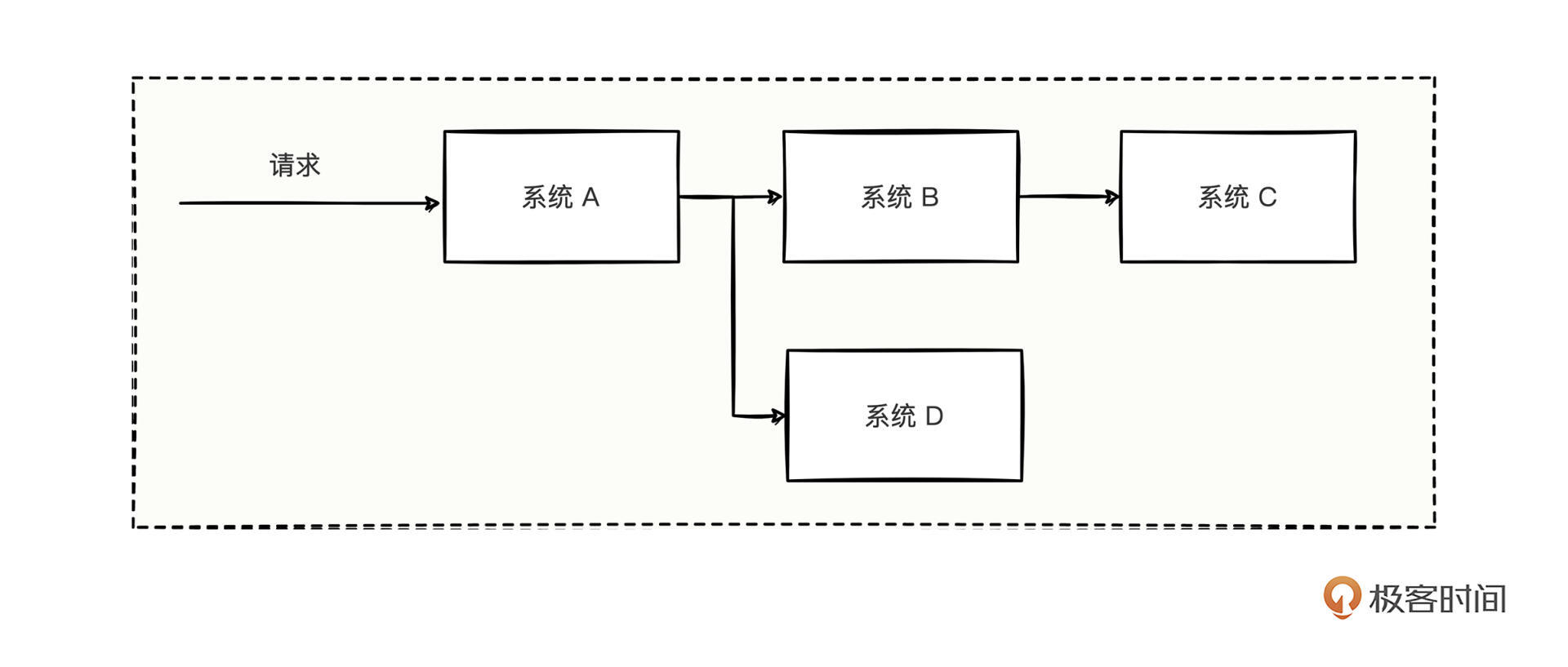
Dubbo框架的特色之一是隐式传递,通过本文详细介绍了如何在日志检索中精准找出一次请求的全部日志。作者首先提到了显式传递的方式,即在所有系统接收请求的对象中添加一个序列号字段,但这种方式需要大量的代码修改,且会影响代码的可读性和维护性。因此,作者提出了隐式传递的解决方案,即将技术属性和业务属性分开发送,通过设置RpcContext上下文中的信息来实现序列号的传递。通过自定义两个过滤器,将序列号在调用链路中完美衔接起来,从而实现了日志检索的能力支撑。隐式传递的应用场景主要有传递链路追踪号、传递用户信息、传递凭证信息。总结了自定义过滤器的四个步骤,并提出了思考题,引发读者对RpcContext的生命周期和隐式传递的进一步思考。整体而言,本文通过实际案例详细介绍了Dubbo框架中隐式传递的实现原理,以及如何在日志检索中精准找出一次请求的全部日志。
《Dubbo 源码剖析与实战》,新⼈⾸单¥59

全部留言(7)
- 最新
- 精选
 张三丰感觉文中获取traceid的地方有问题,不应该在提供者处生成,应该在消费端生成是traceid,再把traceid传给提供者,如果提供者拿到了traceid就打印出来,如果拿不到再生成traceid返回给消费者
张三丰感觉文中获取traceid的地方有问题,不应该在提供者处生成,应该在消费端生成是traceid,再把traceid传给提供者,如果提供者拿到了traceid就打印出来,如果拿不到再生成traceid返回给消费者作者回复: 你好,张三丰:你站在的角度是消费者应用一定是请求的源头,所以你会这么理解。若消费方是前端呢?难道需要前端来生成traceId么? 只是站在看问题的角度不同罢了,不过也挺好的,说明至少是认真在思考这个traceId传递衔接的问题,挺棒的。 我这里引用我之前回答过的内容,如下: 说消费方还有点不太准确,精准点说,应该是从接收请求的那个源头就可以考虑生成traceId。 比如接收前端请求,Web容器比如Tomcat的Filter是最能第一时间感知请求的存在,可以在这里进行拦截直接生成TraceId,至于Tomcat在Filter之后的一些处理环节,就可以直接拿到TraceId了。再进入Controller调用下游Dubbo接口的话,消费方发现上下文没有 traceId 的也是可以考虑生成,也是一种兼容考虑方法,挺好的。 比如 A ->B -> C,抛开Web容器来看待的话,A 的消费方过滤器其实拿到的 traceId 是 null 值,但是 B 所能很好衔接 traceId 的话,那么 B 在发起调用 C 的时候,B 的消费方过滤器是能正常拿到 traceId 的。
2023-01-03归属地:广东42- 小白老师,还有一个问题,为什么不直接用RpcContext进行get 和 set 传递呢?为什么还要涉及到invocation,这块不是很理解。
作者回复: 你好,小白:org.apache.dubbo.rpc.RpcContext#get()、org.apache.dubbo.rpc.RpcContext#set、org.apache.dubbo.rpc.RpcContext#remove、org.apache.dubbo.rpc.RpcContext#get(java.lang.String) 等等 API 已经在 RpcContext 中被标注 @Deprecated 注解,说明在新版本是不再建议使用了。 而是使用更加明确的获取方式(invocation.getObjectAttachments()、RpcContext.getClientAttachment()),从 invocation 中获取数据是明确表示该数据一定是从接收的参数中获取的,这是一种见名知意的写代码表述方式而已。 但是这里你还要结合 ContextFilter、ConsumerContextFilter 来看,你要把数据放对就行了。
2022-12-27归属地:广东2  Lum请问一下 CompleteableFuture那些并行计算的意义是什么呢?项目中比如从多个系统中取数据,一般我都用了5,6个CompletableFuture,然后直接每个都get了。。。 没怎么用到上面的那些api
Lum请问一下 CompleteableFuture那些并行计算的意义是什么呢?项目中比如从多个系统中取数据,一般我都用了5,6个CompletableFuture,然后直接每个都get了。。。 没怎么用到上面的那些api作者回复: 你好,Lum:你刚刚所描述的场景,其实就是【任务一】虚线框中的场景,这种是比较单一的,对于单一的场景,大可以拿着一堆的 Future 列表挨个调用 get 方法,但是如果 Future 与 Future 之间如果有先后顺序、结果聚合、逻辑计算等等,那一直使用 get 操作就玩不转了~
2023-02-26归属地:北京1
 王巍多线程的情况下,线程也能获取到正确的 traceId 吗?
王巍多线程的情况下,线程也能获取到正确的 traceId 吗?作者回复: 你好,王巍:你问得这个细节非常 nice,进程中多线程的 traceId 传递,是另外一个话题。 这里我给个大概思路,你可以单独将这些多线程之间如何传递 traceId 做成一个插件,比如可以横切Spring的AsyncTaskExecutor的方法,比如统一指定公司规范使用某几种 Runnable/Callable 来操作线程,比如 MQ/Job 在触发时刻的源头直接自动横切一刀赋上traceId,等等等等,总之旨在将方法执行前与方法执行后的traceId衔接起来。
2022-12-23归属地:广东1 高级按摩师 👁 ^ 👁⃢*RPCConext是怎么传递的,服务之间调用,上下文怎么传递的呢
高级按摩师 👁 ^ 👁⃢*RPCConext是怎么传递的,服务之间调用,上下文怎么传递的呢作者回复: 你好,高级按摩师:了解下 ThreadLocal 这个东西,就是靠它来进行衔接的。
2023-09-11归属地:广东 乌凌先森老师你好,@DubboService + @Component 这种使用方式有啥好处?
乌凌先森老师你好,@DubboService + @Component 这种使用方式有啥好处?作者回复: 你好,乌凌先森:这俩注解各自解决的问题不一样: 1.@DubboService 解决的是在编码层面时接口实现类可以处理Dubbo的接收请求。 2.@Component 解决的是在 Spring 框架中该接口实现类变成单实例对象以便后续可以被 @Autowired、@Resource 进行注入使用。
2023-01-19归属地:广西2 Geek_10086老师您好,traceId是不是应该在消费者端(ReqNoConsumerFilter)生成,通过隐式传递到服务提供端(ReqNoProviderFilter),文中代码在ReqNoConsumerFilter中从上下文获取应该是null吧
Geek_10086老师您好,traceId是不是应该在消费者端(ReqNoConsumerFilter)生成,通过隐式传递到服务提供端(ReqNoProviderFilter),文中代码在ReqNoConsumerFilter中从上下文获取应该是null吧作者回复: 你好,Geek_10086:说消费方还有点不太准确,精准点说,应该是从接收请求的那个源头就可以考虑生成traceId。 比如接收前端请求,Web容器比如Tomcat的Filter是最能第一时间感知请求的存在,可以在这里进行拦截直接生成TraceId,至于Tomcat在Filter之后的一些处理环节,就可以直接拿到TraceId了。再进入Controller调用下游Dubbo接口的话,消费方发现上下文没有 traceId 的也是可以考虑生成,也是一种兼容考虑方法,挺好的。 至于你说的消费方过滤器默认为 null 的情况,一半对一半不对,比如 A ->B -> C,抛开Web容器来看待的话,A 的消费方过滤器其实拿到的 traceId 是 null 值,但是 B 所能很好衔接 traceId 的话,那么 B 在发起调用 C 的时候,B 的消费方过滤器是能正常拿到 traceId 的。
2022-12-24归属地:广东

