

11 | 拥塞:TCP是如何探测到拥塞的?

该思维导图由 AI 生成,仅供参考
案例
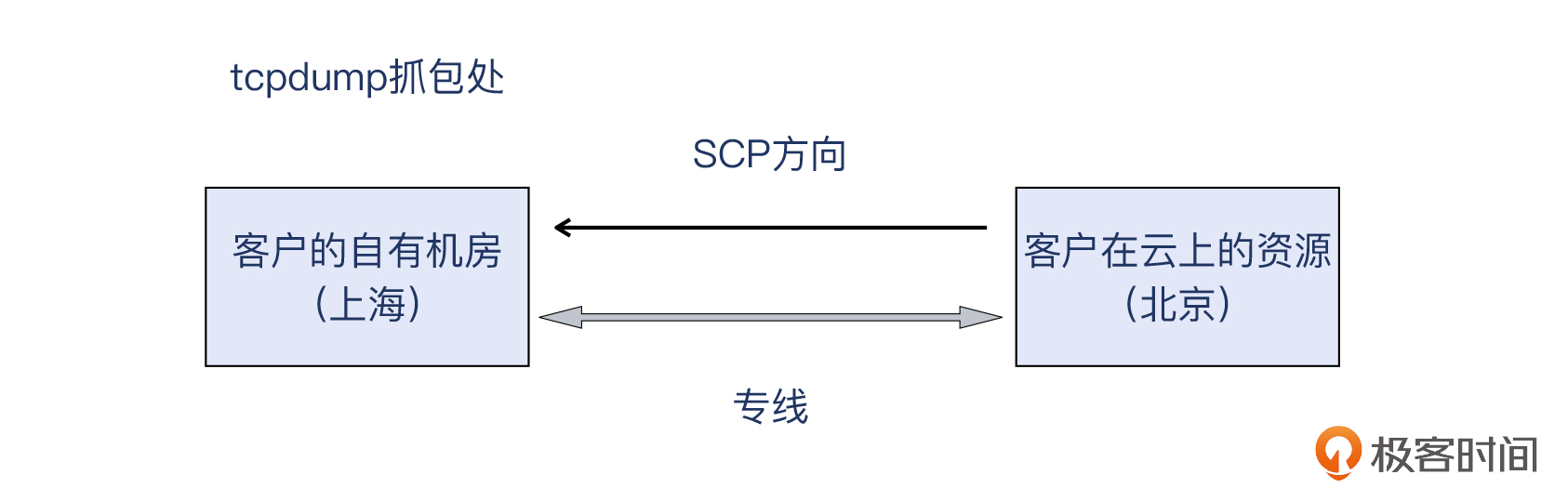
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

TCP拥塞控制是网络传输中至关重要的机制。本文通过案例分析和专业术语解释,深入介绍了TCP拥塞控制的关键阶段和概念。文章首先强调了拥塞控制的重要性,指出其是通信两端自行实现的功能。详细介绍了拥塞控制的四个重要阶段:慢启动、拥塞避免、快速重传和快速恢复,并对慢启动阈值、拥塞窗口等概念进行了详细解释。通过案例分析展示了利用Wireshark工具观察TCP传输过程中的行为,并强调了拥塞控制的实现是通信两端的责任。此外,还介绍了拥塞算法相关的知识点,如间隔确认、拥塞窗口、拥塞避免、快速重传和快速恢复等。文章还提到了实验中修改初始拥塞窗口和改变TCP拥塞控制算法的方法。总体而言,本文内容深入浅出,适合读者快速了解TCP拥塞控制的关键概念和实际应用。 文章通过案例分析和专业术语解释,深入介绍了TCP拥塞控制的关键阶段和概念。强调了拥塞控制的重要性,详细介绍了慢启动、拥塞避免、快速重传和快速恢复等阶段,以及相关概念和工具的使用方法。同时,还提到了实验中修改初始拥塞窗口和改变TCP拥塞控制算法的方法。整体而言,本文内容深入浅出,适合读者快速了解TCP拥塞控制的关键概念和实际应用。
《网络排查案例课》,新⼈⾸单¥59

全部留言(9)
- 最新
- 精选
 Chao慢启动阈值 (ssthresh)的初始值是如何确定的,当慢启动过程中没有进入重传状态,如何进入拥堵避免?
Chao慢启动阈值 (ssthresh)的初始值是如何确定的,当慢启动过程中没有进入重传状态,如何进入拥堵避免?作者回复: 好问题:) 我们可以参考比较新的RFC5681(写于2009年),它的建议(这里不是样的规定)是: The initial value of ssthresh SHOULD be set arbitrarily high (e.g., to the size of the largest possible advertised window), but ssthresh MUST be reduced in response to congestion. 意思是初始慢启动阈值可以大胆一点设置为一个很大的值。当遇到拥塞的时候(超时或者3个DupAck),慢启动阈值会减为当前这个拥塞点的拥塞窗口的一半,这个时候的慢启动阈值,就是适配了实际情况的值,而不是最初那个大胆设置出来的值。 所以,首次慢启动后一般不会主动进入拥塞避免,而是等出现拥塞才获取到第一个实际可用的慢启动阈值。 你可以理解为: 1. TCP传输开始后进入慢启动,因为初始值很高,一般不进入拥塞避免 2. 如果达到了对方的接收窗,就维持在这个速度,然后 2.1如果遇到3次DupAck,那么 2.1.1 如果是TCP Tahoe这种老算法,再次进入慢启动然后拥塞避免 2.1.2 如果是其他算法,进入快速恢复 2.2如果拥塞是超时,则进入慢启动然后拥塞避免
2022-02-1429 那时刻请问老师两个问题 1. 拥塞避免,直到探测到拥塞,然后拥塞窗口就要往下降。请问如何探测拥塞呢?依据接收方的接收窗口与in flight数据大小吗?是不是还有其它方法? 2. 快速恢复,如果遇到超时,也一样要回到慢启动阶段,重新开始。请问这个超时时间是多少呢?可改配置吗?
那时刻请问老师两个问题 1. 拥塞避免,直到探测到拥塞,然后拥塞窗口就要往下降。请问如何探测拥塞呢?依据接收方的接收窗口与in flight数据大小吗?是不是还有其它方法? 2. 快速恢复,如果遇到超时,也一样要回到慢启动阶段,重新开始。请问这个超时时间是多少呢?可改配置吗?作者回复: 您好: 1. 探测到拥塞,一般是两个条件,一是超时,一是收到3个DupAck。两者都表示传输出现了问题。你提到的“接收方的接收窗口与in flight数据大小”,如果在途数据等于对方的接收窗口,传输会是匀速进行了,也不属于拥塞,但无法继续增大拥塞窗口和发送窗口。你可以参考第9讲的案例。 2. 超时是动态计算的,因为每个场景下的RTT都不相同(而且同个连接的RTT本身也会动态变化),因此计算出来的RTO也不相同。不过RTO一般有个最小值,Linux的RTO最小值是200ms。
2022-02-1435
 好吃不贵请教老师一个问题哈,可以服务端,客户端用不同算法吗?比如server用BBR,client用CUBIC? 多谢哈
好吃不贵请教老师一个问题哈,可以服务端,客户端用不同算法吗?比如server用BBR,client用CUBIC? 多谢哈作者回复: 可以啊,本来就是双方各自用自己的拥塞控制算法的。你可以想象一下,一个服务端要跟那么多客户端通信,这些客户端也没有“说好了用同一种拥塞控制”,对不对:)
2022-03-2124 江山如画老师,有个小问题,在慢启动的时候,每收到一个 ack 报文,拥塞窗口就加 1 个mss,不太清楚为什么拥塞窗口这个阶段是翻倍增长。 图上看慢启动阶段,第一次发送了1个报文,第二次发送了2个报文,第三次发送了4个报文,是因为慢启动阶段,每次都发出上一轮的2倍的报文数目,达到翻倍增长的目的么?
江山如画老师,有个小问题,在慢启动的时候,每收到一个 ack 报文,拥塞窗口就加 1 个mss,不太清楚为什么拥塞窗口这个阶段是翻倍增长。 图上看慢启动阶段,第一次发送了1个报文,第二次发送了2个报文,第三次发送了4个报文,是因为慢启动阶段,每次都发出上一轮的2倍的报文数目,达到翻倍增长的目的么?作者回复: 这确实是一个应该关注的知识点。慢启动阶段的“拥塞窗口翻倍”是一种表现,但不是规定。规定是“每收到一个ack,拥塞窗口就增加一个MSS”。比如: 初始拥塞窗口为10MSS;假如每次都有足量的数据要发送,那么: 第一次往返:发出10个MSS, 收到10个Ack,此时拥塞窗口增长为10+10也就是20个MSS 第二次往返:发出20个MSS,收到20个Ack,此时拥塞窗口增长为20+20也就是40个MSS 上面这种就是“翻倍”,但注意,RFC不是说一定要在一个RTT里面翻倍,而是因为一个RTT里经常收到跟发送量同等数量的Ack,所以效果上是翻倍的。
2022-02-14114 webmin流量图上观察到“平顶山”就一个最明显的流量达限的情况,一但出口流量达到上限就容易引发相互踩踏的情况,传不出去,使用的人就更着急,就会点击更多次,或者多窗多设备重试,引发更多的拥塞。
webmin流量图上观察到“平顶山”就一个最明显的流量达限的情况,一但出口流量达到上限就容易引发相互踩踏的情况,传不出去,使用的人就更着急,就会点击更多次,或者多窗多设备重试,引发更多的拥塞。作者回复: 嗯所以TCP就设计了拥塞避免这种机制,为了让网络使用尽可能的公平。生活中也是,不排队随便挤的话反而慢,排队来反而快。TCP拥塞控制也是类似,有了规矩,不随意争抢,大家的机会就会比较均等:)
2022-02-142 蜉蝣老师,对于 io graphs 而言,我还是不明白什么时候需要选择 SAM period 的值,选择多少更合适
蜉蝣老师,对于 io graphs 而言,我还是不明白什么时候需要选择 SAM period 的值,选择多少更合适作者回复: 您好,这个问题倒不复杂,SMA period选项也没几个,你可以都试一下,看看出来的图是否比较“细腻”。一般来说,SMA period数值越小,出来的图的粒度越细腻;数值越大,粒度越粗,越会损失一些细节。 相对来说,建议选择小一些的SMA period值。
2022-08-29归属地:上海1 李二木TCP 拥塞控制主要有四个重要阶段: - 慢启动 慢启动是指 TCP 传输的开始阶段是从一个相对低的速度开始的。在这个阶段,每次 TCP 收到一个确认了数据的 ACK,拥塞窗口就增加一个 MSS。如果到达慢启动阈值塞窗口的增长速度立刻就放缓了,变成了每过一个 RTT,拥塞窗口就只增长一个 MS - 拥塞避免 传输过了慢启动阈值(ssthresh)之后,进入拥塞避免阶段。这个阶段的特征是“和性增长乘性降低”( Addictive increase/mutiplicative decrease),简单理解就是增长很慢。 每一个 RTT里,拥塞窗口只增长一个 MSS,这个阶段的拥塞窗口的增长是线性的。如果探测到拥塞,拥塞窗口就要往下降。这个下降是直接减半的,所以叫乘性降低 - 快速重传 TCP 每发送一个报文,就启动一个超时计时器。如果在限定时间内没收到这个报文的确认,那么发送方就会认为,这个报文已经在网络上丢失了,于是需要重传这个报文,这种形式叫做超时重传,而快速重传是一旦发送方收到 3 次重复确认(加上第一次确认就一共是 4 次),就不用等超时计时器了,直接重传这个报文 - 快速恢复 跟之前的“慢启动 -> 拥塞避免 -> 慢启动 -> 拥塞避免”这种做法不同,在遇到拥塞点之后,通过快速重传,就不再进入慢启动,而是从这个减半的拥塞窗口开始,保持跟拥塞避免一样的线性增长,直到遇到下一个拥塞点。
李二木TCP 拥塞控制主要有四个重要阶段: - 慢启动 慢启动是指 TCP 传输的开始阶段是从一个相对低的速度开始的。在这个阶段,每次 TCP 收到一个确认了数据的 ACK,拥塞窗口就增加一个 MSS。如果到达慢启动阈值塞窗口的增长速度立刻就放缓了,变成了每过一个 RTT,拥塞窗口就只增长一个 MS - 拥塞避免 传输过了慢启动阈值(ssthresh)之后,进入拥塞避免阶段。这个阶段的特征是“和性增长乘性降低”( Addictive increase/mutiplicative decrease),简单理解就是增长很慢。 每一个 RTT里,拥塞窗口只增长一个 MSS,这个阶段的拥塞窗口的增长是线性的。如果探测到拥塞,拥塞窗口就要往下降。这个下降是直接减半的,所以叫乘性降低 - 快速重传 TCP 每发送一个报文,就启动一个超时计时器。如果在限定时间内没收到这个报文的确认,那么发送方就会认为,这个报文已经在网络上丢失了,于是需要重传这个报文,这种形式叫做超时重传,而快速重传是一旦发送方收到 3 次重复确认(加上第一次确认就一共是 4 次),就不用等超时计时器了,直接重传这个报文 - 快速恢复 跟之前的“慢启动 -> 拥塞避免 -> 慢启动 -> 拥塞避免”这种做法不同,在遇到拥塞点之后,通过快速重传,就不再进入慢启动,而是从这个减半的拥塞窗口开始,保持跟拥塞避免一样的线性增长,直到遇到下一个拥塞点。作者回复: 很好的笔记和打卡,加油:)
2022-02-181 上杉夏香三刷笔记: * 为什么TCP要有拥塞机制? 是让每条TCP连接拥有敬畏之心。展开来说,每条TCP连接都需要拥塞控制,如果每条TCP连接都放飞自我、敞开了的发送数据,网络带宽肯定经受不住,最后的结局就是谁都无法发送数据。 那好,我们约定好,TCP建立一套探测网络线路是否快要达到上限的机制。若探测到,那我们就自动减缓速度。如此一来,不仅让网络整体可用,也能确保自己的传输速度和稳定性。这就是TCP的拥塞控制。 * 拥塞机制是什么样的? 每条TCP连接设立发送数据速度的红线,探测到红线,就立马减缓速度。 探测到红线的标志是发生丢包。 * 是什么让拥塞机制变得复杂的呢? 一句话回答:网络是动态变化的。 之前达到红线的发送速度此时已经不怎么丢包之类的,所以拥塞机制中的红线是不断变化的,而每条TCP连接都是需要不断探测的。 * 一脉相承之更好的利用现代网络 什么叫做更好的利用现代网络呢?其实没什么可玄乎的,就是现代的网络传播速度比以前好太多了。所以TCP也进化了,具体表现在哪里? 我们可以这么来理解和记忆,决定发送端发送速度的因素有两个:1、对方的接收窗口;2、自己的拥塞窗口 1、接受窗口 TCP协议本身有一个2字节的Window字段,表示能够接收的数据大小,最大为2^32-1=65535字节。为了更好的利用现代网络,有了TCP Option的Window Scale,得了,一下子就把接受窗口的上限拉高了太多 2、拥塞窗口 一般来说,发送阶段分为慢启动、拥塞避免、快速重传、快速恢复等阶段。其中慢启动阶段,由Linux最初的版本决定,初始拥塞窗口2-4MSS。那么为了更好的利用现代网络,初始拥塞窗口一下子调整为10MSS。 发送能力的提高一目了然,也就有了更快的慢启动! * 什么是拥塞点,或者说什么叫做碰到了拥塞点? 其实就是丢包。丢包就代表碰到了拥塞点! * 什么是快速重传? 为了优化超时重传机制中每次都得等特定时间才能确定某个包丢失。快速重传的本质是接收方告知发送方,某个包应该是丢失了,你不用等倒计时了,直接发给我吧~ * 快速恢复 一句话总结: 普通的拥塞策略:慢启动->拥塞避免->碰到拥塞点->慢启动->拥塞避免->碰到拥塞点,碰到拥塞点之后,从头开始。 如果拥塞点之后,是通过快速重传发送丢失的包,那就不必重新从慢启动开始。而是直接将拥塞窗口设置为拥塞点的一半,直接进入拥塞避免阶段。2022-11-14归属地:北京5
上杉夏香三刷笔记: * 为什么TCP要有拥塞机制? 是让每条TCP连接拥有敬畏之心。展开来说,每条TCP连接都需要拥塞控制,如果每条TCP连接都放飞自我、敞开了的发送数据,网络带宽肯定经受不住,最后的结局就是谁都无法发送数据。 那好,我们约定好,TCP建立一套探测网络线路是否快要达到上限的机制。若探测到,那我们就自动减缓速度。如此一来,不仅让网络整体可用,也能确保自己的传输速度和稳定性。这就是TCP的拥塞控制。 * 拥塞机制是什么样的? 每条TCP连接设立发送数据速度的红线,探测到红线,就立马减缓速度。 探测到红线的标志是发生丢包。 * 是什么让拥塞机制变得复杂的呢? 一句话回答:网络是动态变化的。 之前达到红线的发送速度此时已经不怎么丢包之类的,所以拥塞机制中的红线是不断变化的,而每条TCP连接都是需要不断探测的。 * 一脉相承之更好的利用现代网络 什么叫做更好的利用现代网络呢?其实没什么可玄乎的,就是现代的网络传播速度比以前好太多了。所以TCP也进化了,具体表现在哪里? 我们可以这么来理解和记忆,决定发送端发送速度的因素有两个:1、对方的接收窗口;2、自己的拥塞窗口 1、接受窗口 TCP协议本身有一个2字节的Window字段,表示能够接收的数据大小,最大为2^32-1=65535字节。为了更好的利用现代网络,有了TCP Option的Window Scale,得了,一下子就把接受窗口的上限拉高了太多 2、拥塞窗口 一般来说,发送阶段分为慢启动、拥塞避免、快速重传、快速恢复等阶段。其中慢启动阶段,由Linux最初的版本决定,初始拥塞窗口2-4MSS。那么为了更好的利用现代网络,初始拥塞窗口一下子调整为10MSS。 发送能力的提高一目了然,也就有了更快的慢启动! * 什么是拥塞点,或者说什么叫做碰到了拥塞点? 其实就是丢包。丢包就代表碰到了拥塞点! * 什么是快速重传? 为了优化超时重传机制中每次都得等特定时间才能确定某个包丢失。快速重传的本质是接收方告知发送方,某个包应该是丢失了,你不用等倒计时了,直接发给我吧~ * 快速恢复 一句话总结: 普通的拥塞策略:慢启动->拥塞避免->碰到拥塞点->慢启动->拥塞避免->碰到拥塞点,碰到拥塞点之后,从头开始。 如果拥塞点之后,是通过快速重传发送丢失的包,那就不必重新从慢启动开始。而是直接将拥塞窗口设置为拥塞点的一半,直接进入拥塞避免阶段。2022-11-14归属地:北京5 原则老师,有几个问题: 1. 这里到了慢启动阈值应该不是增长一个 MSS 吧,而是当前 MSS +1,和慢启动过程有点混淆了。 2. 间隔确认不是 RFC 中定义的吧 3. 快速恢复怎么感觉不太快,如果使用慢启动的方式翻倍增长是不是更快。2023-06-05归属地:广东
原则老师,有几个问题: 1. 这里到了慢启动阈值应该不是增长一个 MSS 吧,而是当前 MSS +1,和慢启动过程有点混淆了。 2. 间隔确认不是 RFC 中定义的吧 3. 快速恢复怎么感觉不太快,如果使用慢启动的方式翻倍增长是不是更快。2023-06-05归属地:广东

