

17|数据结构:软件系统核心部件哈希表,内存如何布局?

该思维导图由 AI 生成,仅供参考
Rust 的哈希表
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了 Rust 语言中的哈希表实现,包括哈希表的重要性和应用、冲突解决机制、数据结构和内存布局、以及基本使用方法。通过示例代码展示了 Rust 哈希表的动态增长和缩减过程。文章还介绍了在 Rust 中探索 HashMap 数据结构时,通过使用 std::mem::transmute 方法来打印数据结构,以及通过 rust-gdb / rust-lldb 来查看哈希表的内存布局。通过这些内容,读者可以深入了解 Rust 中哈希表的设计原理和实际应用,对于想深入了解 Rust 哈希表的开发者具有很高的参考价值。文章还介绍了哈希表重新分配与增长、删除值的过程,以及如何让自定义的数据结构成为 HashMap 的 key。此外,还简要介绍了与 HashMap 相关的其它几个数据结构,包括 HashSet、BTreeMap 和 BTreeSet。通过本文的总结,读者可以快速了解 Rust 中哈希表的实现原理、操作方法以及相关数据结构的特点,为他们在实际开发中应用这些知识提供了指导和参考。
《陈天 · Rust 编程第一课》,新⼈⾸单¥68

全部留言(18)
- 最新
- 精选
 Geek_5244fa说一下对 hashbrown 的理解。 一般的哈希表是对数组大小取模(hash % len)来定位位置的,但是 hashbrown 把 hash 分两部分使用: 1. 低几位(& bucket_size)定位在数组的位置 2. 高 7 位存到对应位置的 ctrl 块里,类似指纹的作用 一般哈希表获取时,取模定位到位置后,要完整对比 key 才能知道是找到(key相同)还是要探查(key 不同)。 而 hashbrown 可以利用 ctrl 里存起来的高 7 位快速发现冲突的情况(低几位相同但高7 位不同),直接进入下一步探查。
Geek_5244fa说一下对 hashbrown 的理解。 一般的哈希表是对数组大小取模(hash % len)来定位位置的,但是 hashbrown 把 hash 分两部分使用: 1. 低几位(& bucket_size)定位在数组的位置 2. 高 7 位存到对应位置的 ctrl 块里,类似指纹的作用 一般哈希表获取时,取模定位到位置后,要完整对比 key 才能知道是找到(key相同)还是要探查(key 不同)。 而 hashbrown 可以利用 ctrl 里存起来的高 7 位快速发现冲突的情况(低几位相同但高7 位不同),直接进入下一步探查。作者回复: 赞!
2021-10-05314- GeekCiaoaHash 已经可以做到DOS防护了:https://github.com/tkaitchuck/aHash/wiki/How-aHash-is-resists-DOS-attacks
作者回复: 👍
2021-10-019 
 qinsiSIMD lookup也只是在x86/64上用sse2而已,据说avx/neon效果不佳: https://github.com/rust-lang/hashbrown/blob/cedc3267e4/src/raw/mod.rs#L16 看了下其他平台也都还没稳定: https://doc.rust-lang.org/core/arch/index.html#modules
qinsiSIMD lookup也只是在x86/64上用sse2而已,据说avx/neon效果不佳: https://github.com/rust-lang/hashbrown/blob/cedc3267e4/src/raw/mod.rs#L16 看了下其他平台也都还没稳定: https://doc.rust-lang.org/core/arch/index.html#modules作者回复: 这是个和 CPU 指令集紧密相关的操作。x86/64 CPU 目前还是服务器的主流(虽然未来不一定)
2021-10-024 交流会老师您好,有个疑问不太懂请教一下: 您在文中说 ---- ...在我的 OS X 下,一开始哈希表为空,ctrl 地址看上去是一个 TEXT/RODATA 段的地址,... 想请问一下,通过看数据地址怎么能区分是在 段上还是堆栈上的? 谢谢~
交流会老师您好,有个疑问不太懂请教一下: 您在文中说 ---- ...在我的 OS X 下,一开始哈希表为空,ctrl 地址看上去是一个 TEXT/RODATA 段的地址,... 想请问一下,通过看数据地址怎么能区分是在 段上还是堆栈上的? 谢谢~作者回复: 你可以在不同的系统上打印 main 函数的地址和 main 下一个 u32,一个 vec 的堆地址,就可以大概看到不同地址的区别了。比如: ```rust fn main() { let a = 1; let arr = vec![1,2,3]; println!("main: {:p}, a: {:p}, s: {:p}", main as *const (), &a, &arr[0]); } ``` 在 playground 下的打印(https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=8003d4ccfbf6d63280b124811a219f4a): main: 0x55bcfa1f5100, a: 0x7ffcd8b6adec, s: 0x55bcfb6ca9d0 如果你想知道更详细的各个段的地址,可以使用 readelf 或者在 gdb 里面查看。
2021-12-052 徐洲更HashMap使用的一个问题:文章例子插入的元素是char和i32, 长度固定都是32字节,HashMap在插入数据时,从图上看,是直接将值记录在堆内存中数组对应的位置上。对于一个复杂的数据类型,比如说Key是String,Value是Vec<String>, 那么记录的是不是就是 大小为usize 的指针呢?
徐洲更HashMap使用的一个问题:文章例子插入的元素是char和i32, 长度固定都是32字节,HashMap在插入数据时,从图上看,是直接将值记录在堆内存中数组对应的位置上。对于一个复杂的数据类型,比如说Key是String,Value是Vec<String>, 那么记录的是不是就是 大小为usize 的指针呢?作者回复: 不是 usize 大小的指针。你可以自己想想 String 和 Vec<T> 的结构都是什么样子的。所以这里 key 是 24 个字节,value 也是 24 个字节,它们再通过结构里的指针指向额外的堆地址里的内容。
2021-10-2022- Ixa把 PartialOrd 和 PartialEq 实现即可解决报错。使用词典的cmp来进行对比 impl Ord for Name { fn cmp(&self, other: &Self) -> Ordering { (self.flags, &self.name).cmp(&(other.flags, &other.name)) } } impl PartialOrd for Name { fn partial_cmp(&self, other: &Self) -> Option<Ordering> { Some(self.cmp(other)) } } impl PartialEq for Name { fn eq(&self, other: &Self) -> bool { (self.flags, &self.name) == (other.flags, &other.name) } }
作者回复: 对!
2021-10-081  Marvichov第三题: ``` # 最初 root insert a - k x/24 0x100504080 0x100504080: 0x004044a0 0x00000001 0x00000061 0x00000062 0x100504090: 0x00000063 0x00000064 0x00000065 0x00000066 0x1005040a0: 0x00000067 0x00000068 0x00000069 0x0000006a 0x1005040b0: 0x0000006b 0x00000001 0x00000002 0x00000003 0x1005040c0: 0x00000004 0x00000005 0x00000006 0x00000007 0x1005040d0: 0x00000008 0x00000009 0x0000000a 0x0000000b # insert 第11个 出现新的root x 0x1004044a0 0x1004044a0: 00 00 00 00 00 00 00 00 67 00 00 00 00 00 00 00 ........g....... 0x1004044b0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ ## 继续 insert 到 z x 0x1004044a0 0x1004044a0: 00 00 00 00 00 00 00 00 67 00 00 00 6e 00 00 00 ........g...n... 0x1004044b0: 5 00 00 00 ff ff ff ff ff ff ff ff ff ff ff ff u...������������ ``` `LeafNode`的capacity是11, 装满了过后就变成6个, 留5个slot以备depth加深 ``` root <g n u> leaf <a-f> <h-m> <o-t> <v-z> ``` 疑问: 1. `LeafNode` 第一个field不是parent嘛? 为啥leaf 1的第一位是 `0x004044a0` 仅仅是32位? 我的机器是64位, 而且之后出现的parent的address是 `0x1004044a0`, 感觉这两个很接近? 不知道这是什么trick 2. 怎么从root node read leaf node的memory呢? root node的parent是null, 没找到怎么access leaf node. 我目前只能从最初的root node猜 (以为之后这个root变成了leaf) 3. 这个field能大概讲一讲big picture嘛? 目前读源码还是有难度... ``` struct InternalNode { data: LeafNode, edges: [MaybeUninit>; 2 * B],} ````
Marvichov第三题: ``` # 最初 root insert a - k x/24 0x100504080 0x100504080: 0x004044a0 0x00000001 0x00000061 0x00000062 0x100504090: 0x00000063 0x00000064 0x00000065 0x00000066 0x1005040a0: 0x00000067 0x00000068 0x00000069 0x0000006a 0x1005040b0: 0x0000006b 0x00000001 0x00000002 0x00000003 0x1005040c0: 0x00000004 0x00000005 0x00000006 0x00000007 0x1005040d0: 0x00000008 0x00000009 0x0000000a 0x0000000b # insert 第11个 出现新的root x 0x1004044a0 0x1004044a0: 00 00 00 00 00 00 00 00 67 00 00 00 00 00 00 00 ........g....... 0x1004044b0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ ## 继续 insert 到 z x 0x1004044a0 0x1004044a0: 00 00 00 00 00 00 00 00 67 00 00 00 6e 00 00 00 ........g...n... 0x1004044b0: 5 00 00 00 ff ff ff ff ff ff ff ff ff ff ff ff u...������������ ``` `LeafNode`的capacity是11, 装满了过后就变成6个, 留5个slot以备depth加深 ``` root <g n u> leaf <a-f> <h-m> <o-t> <v-z> ``` 疑问: 1. `LeafNode` 第一个field不是parent嘛? 为啥leaf 1的第一位是 `0x004044a0` 仅仅是32位? 我的机器是64位, 而且之后出现的parent的address是 `0x1004044a0`, 感觉这两个很接近? 不知道这是什么trick 2. 怎么从root node read leaf node的memory呢? root node的parent是null, 没找到怎么access leaf node. 我目前只能从最初的root node猜 (以为之后这个root变成了leaf) 3. 这个field能大概讲一讲big picture嘛? 目前读源码还是有难度... ``` struct InternalNode { data: LeafNode, edges: [MaybeUninit>; 2 * B],} ````作者回复: 你可以参考:https://gankra.github.io/blah/rust-btree-case/ 来学习。虽然是比较旧的文章,但 Btreemap 的思想和大方向是一致的。 3. B=6,edges 是个数组,里面有 12 个元素,元素类型是可能未初始化(MaybeUninit)的BoxedNode<K, V>。这个代码开头处有伪代码表述想要达成的目的: // This is an attempt at an implementation following the ideal // // ``` // struct BTreeMap<K, V> { // height: usize, // root: Option<Box<Node<K, V, height>>> // } // // struct Node<K, V, height: usize> { // keys: [K; 2 * B - 1], // vals: [V; 2 * B - 1], // edges: [if height > 0 { Box<Node<K, V, height - 1>> } else { () }; 2 * B], // parent: Option<(NonNull<Node<K, V, height + 1>>, u16)>, // len: u16, // }
2021-10-051- Marvichov对文中的例子有些疑问: 我的理解是, ctrl section, byte的postion, 对应着bucket的position `a` 在第一个bucket, 为啥ctrl section的第一个byte不是`0x72` 呢? 和示意图 (`ctrl 表` 那一节) 对不上. ``` (gdb) c Continuing. # 插入第四个元素后,哈希表扩容,堆地址起始位置变为 0x5555555a7b50 - 8*8(0x40) added 4: bucket_mask 0x7, ctrl 0x5555555a7b50, growth_left: 3, items: 4 Breakpoint 1, hashmap2::explain (name=..., map=...) at src/hashmap2.rs:32 32 unsafe { std::mem::transmute(arr) } (gdb) x /20x 0x5555555a7b10 0x5555555a7b10: 0x00000061 0x00000001 0x00000000 0x00000000 0x5555555a7b20: 0x00000064 0x00000004 0x00000063 0x00000003 0x5555555a7b30: 0x00000000 0x00000000 0x00000062 0x00000002 0x5555555a7b40: 0x00000000 0x00000000 0x00000000 0x00000000 0x5555555a7b50: 0xff72ffff 0x0aff6502 0xffffffff 0xffffffff ``` ctrl的start addr是0x5555555a7b50, 第一个byte不应该对应bucket 1吗? 然而`0a` 对应的是第5个bucket?
作者回复: 注意看图,这句话之后的图,你看看图中前后对比。 > 在移动的过程中,会涉及哈希的重分配。从下图可以看到,‘a’ / ‘c’ 的相对位置和它们的 ctrl byte 没有变化,但重新做 hash 后,‘b’ 的 ctrl byte 和位置都发生了变化。 现在 ctrl bits 的位置是:5 6 7 8 1 2 3 4。所以 0a 对应第一项。
2021-10-0431  阿海这一章看的比之前吃力很多,尤其是中间观察内存布局的内容。后面有机会再来仔细琢磨下。 尝试回答下问题吧: 1. Name需要实现 Debug, PartialEq, Eq, PartialOrd, Ord 这几个trait ``` #[derive(Debug, PartialEq, Eq, PartialOrd, Ord)] struct Name { pub name: String, pub flags: u32, } ``` 2. 粗略算了下,(15 + 200) * 1200000 / (1024 * 1024)大约需要246M内存。内存利用率不知道要怎么算了。 3. 等有时间再琢磨下
阿海这一章看的比之前吃力很多,尤其是中间观察内存布局的内容。后面有机会再来仔细琢磨下。 尝试回答下问题吧: 1. Name需要实现 Debug, PartialEq, Eq, PartialOrd, Ord 这几个trait ``` #[derive(Debug, PartialEq, Eq, PartialOrd, Ord)] struct Name { pub name: String, pub flags: u32, } ``` 2. 粗略算了下,(15 + 200) * 1200000 / (1024 * 1024)大约需要246M内存。内存利用率不知道要怎么算了。 3. 等有时间再琢磨下作者回复: 1. 正确! 2. 需要内存 (200+15+1) * 2M = 432M,实际占用 (200+15) * 114M = 246M,利用率 57%。注意 HashMap bucket 数量是指数增长的。
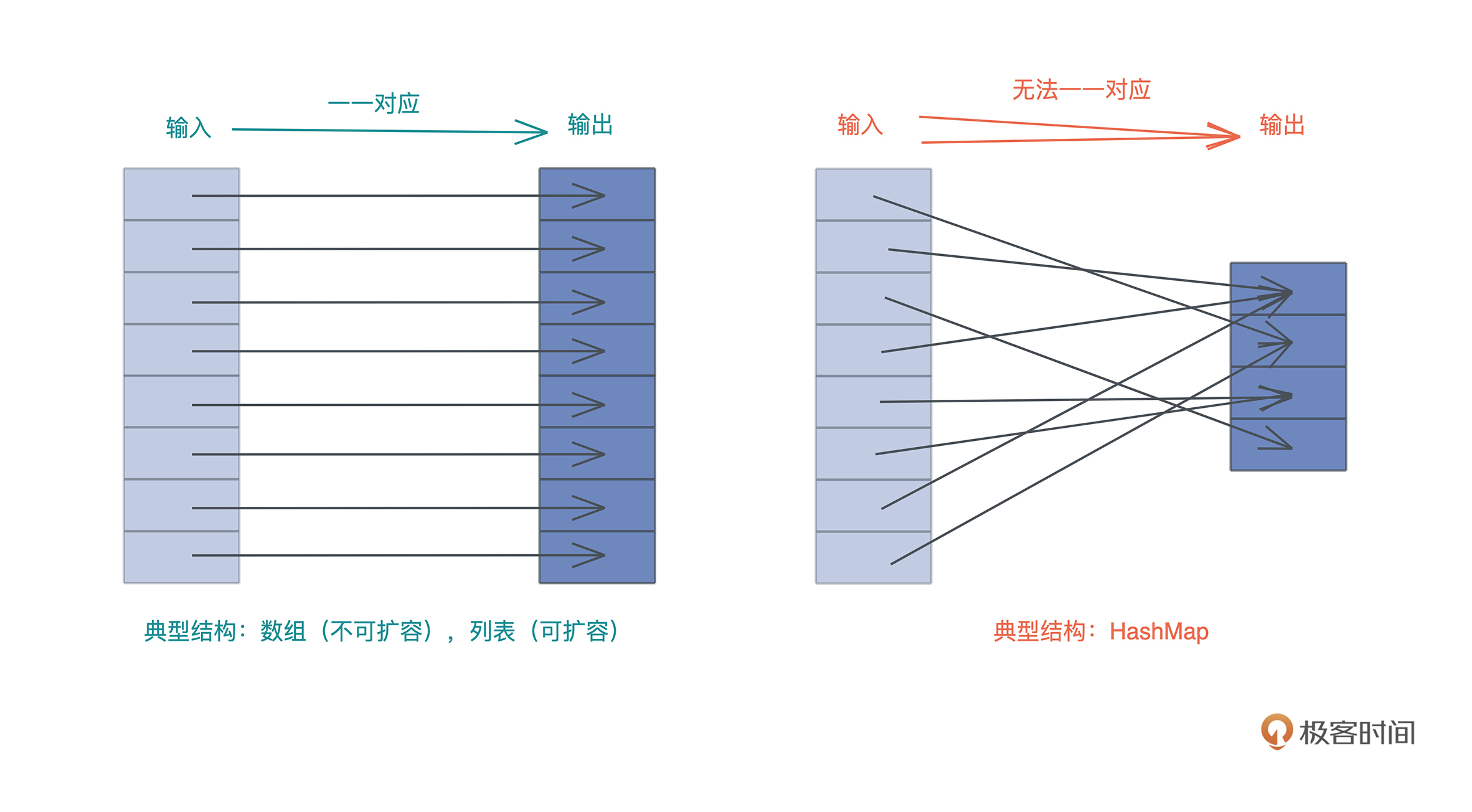
2021-10-0371- Geek_5244fa> 如果数据结构的输入和输出能一一对应,那么可以使用列表,如果无法一一对应,那么就需要使用哈希表。 这里说的一一对应,结合图来看,似乎说的是位置的映射。 HashMap 有两个映射关系,一个是 key 到位置的映射,一个到 value 的映射。不同 key 可能映射到相同的位置(冲突),也可以映射到相同的值。
作者回复: 对!
2021-10-05

