

05 | 后端BaaS化(上):NoOps的微服务

 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

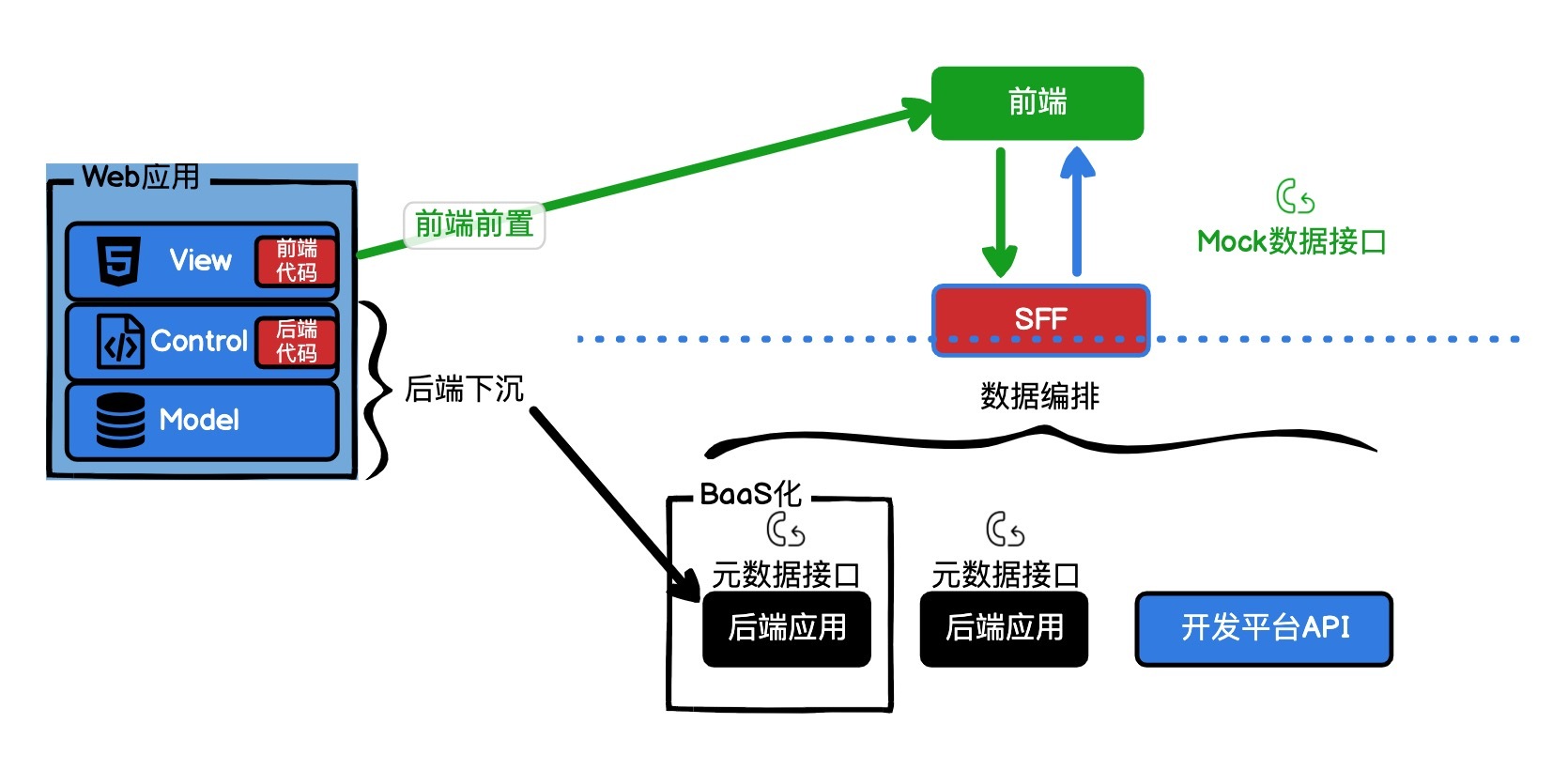
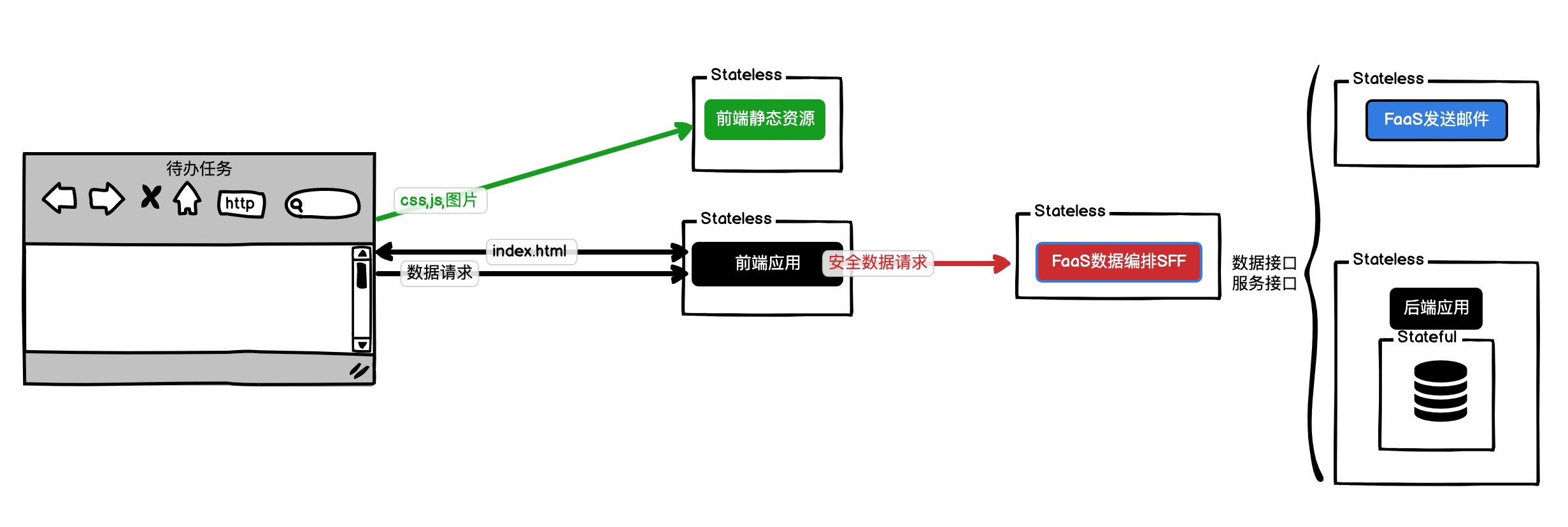
本文深入探讨了后端BaaS化及微服务的概念,强调了它们在实现快速迭代和跨应用复用方面的重要性。作者首先介绍了Stateless和Stateful节点的概念,指出后端应用BaaS化的核心是将后端应用转换成NoOps的数据接口。文章提到了传统数据库连接FaaS会增加额外开销,因此提出了将数据库操作转为RESTful API的思路。通过一个Web应用案例展示了后端应用BaaS化的架构优势,强调了微服务架构的重要性。微服务的概念被介绍为将复杂的大型应用拆解成小功能模块,通过API接口组合成原先的大型应用,从而实现快速迭代和跨应用复用。文章还提到微服务架构的设计和数据库解耦方式。总的来说,本文通过深入浅出的方式介绍了后端BaaS化及微服务的概念,为读者提供了对这一技术领域的快速了解。文章内容丰富,涉及微服务的10要素、解耦数据库等关键技术,为读者提供了全面的技术知识。文章还提到了使用表格存储模拟Kafka的方法,以及部署FaaS服务的具体步骤和配置要求。整体而言,本文为读者提供了深入的技术知识和实践指导,对于想要了解后端BaaS化及微服务的读者来说,是一篇具有价值的文章。
《Serverless 入门课》,新⼈⾸单¥29

全部留言(13)
- 最新
- 精选

 qinsi请问数据库解耦时副本数据库允许数据写入吗?如果允许写入的话会不会因为写入的数据冲突导致数据不一致呢?
qinsi请问数据库解耦时副本数据库允许数据写入吗?如果允许写入的话会不会因为写入的数据冲突导致数据不一致呢?作者回复: 数据副本只是为了区分的叫法,当然允许写入了。Binary log有一定的容错性,要考虑事务逻辑。但如果是银行或者支付的场景,要解决强一致性。可以直接写消息队列,再去消费数据。
2020-04-284 电光火石老师好,在后台服务baas化的过程中,关于数据库跟以前微服务的方式有些不一样,微服务的各个节点是共享数据库的,但是baas化中,每个节点有自己的数据库,而且数据库的内容是一样的。这样是否带来2个问题: 1. 在数据量很大的情况下,每个节点都有一样的数据库,是否会使得数据存储量会翻几倍,成本会很高 2. 在扩容的情况下,如果数据量很大,新节点需要复制的数据也很多,启动时间会非常的长 3. 有多少个应用,就有多少个数据库实例。一般情况下,我们应用的数量会远高于数据库机器的数量。高并发场景下,会不会导致网络占用很高,性能整体上升 还是说这种方案本身就不适合大并发或者数据量很高的场景,谢谢了!
电光火石老师好,在后台服务baas化的过程中,关于数据库跟以前微服务的方式有些不一样,微服务的各个节点是共享数据库的,但是baas化中,每个节点有自己的数据库,而且数据库的内容是一样的。这样是否带来2个问题: 1. 在数据量很大的情况下,每个节点都有一样的数据库,是否会使得数据存储量会翻几倍,成本会很高 2. 在扩容的情况下,如果数据量很大,新节点需要复制的数据也很多,启动时间会非常的长 3. 有多少个应用,就有多少个数据库实例。一般情况下,我们应用的数量会远高于数据库机器的数量。高并发场景下,会不会导致网络占用很高,性能整体上升 还是说这种方案本身就不适合大并发或者数据量很高的场景,谢谢了!作者回复: 微服务标准的做法是一个微服务实例独享一个数据库实例的。当然你业务量不大,可以多个微服务实例共享一个数据库实例。 微服务架构在docker流行后才火,就是因为docker可以让计算资源进一步碎片化,所以成本并不会很高。 数据实例的启动时,通常是先从现有数据库副本创建,再根据消息队列同步后续数据。启动实例过程是秒级的。 微服务架构,本身就是通过拆解将复杂的业务问题变成一个个小的职责单一的小服务。运维的复杂度会上升,但是整体性能并不会下降多少。 你可以想想,现在的京东,淘宝这样的网站,背后都是微服务架构的。如果你用单体应用开发这么庞大的一个应用,这么多团队和人员参与,怎么去运维和开发。
2020-04-2744 我来也哈哈,原来老师也觉得云厂商提供的kafka云服务贵。 我对这个深有体会! 我看领导买的一个阿里云kafka云服务,要4K+/月,配置也就一般吧,可能监控做的比较好吧。 再想想我买的竞价付费实例,约64元/月,4cpu8g配置,还不是突发性能的。当开发环境的k8s节点,也不怕丢数据,哈哈。 想一想,还是有钱真好。
我来也哈哈,原来老师也觉得云厂商提供的kafka云服务贵。 我对这个深有体会! 我看领导买的一个阿里云kafka云服务,要4K+/月,配置也就一般吧,可能监控做的比较好吧。 再想想我买的竞价付费实例,约64元/月,4cpu8g配置,还不是突发性能的。当开发环境的k8s节点,也不怕丢数据,哈哈。 想一想,还是有钱真好。作者回复: 用CaaS服务,自己搭建一套Kafka还便宜一些。现在程序员可以调度的机器资源还是很充沛的。
2020-04-2734 此方彼方Francis微服务标准的做法是一个微服务实例独享一个数据库实例的。 这个说法有些夸张了吧?老师有生产上的实践案例吗?
此方彼方Francis微服务标准的做法是一个微服务实例独享一个数据库实例的。 这个说法有些夸张了吧?老师有生产上的实践案例吗?作者回复: 我这里提的微服务实例独享一个数据库实例是标准做法,这样做可以让微服务实例+数据库形成的整体,变成stateless。这个叫做:数据库的可弃性。 实际场景比较灵活,你可以一个微服务多个实例,使用一个数据库。不过你需要额外关注:这个数据库不会成为你的瓶颈。
2020-05-0332 liubin确实,有点扯了,每个应用副本一个db,谁来负责业务数据同步,不是kafka能解决的吧。而且事物也没法搞。这工作量比单db要大100倍
liubin确实,有点扯了,每个应用副本一个db,谁来负责业务数据同步,不是kafka能解决的吧。而且事物也没法搞。这工作量比单db要大100倍作者回复: 首先kafka有专门的各种db同步解决方案,你可以了解一下,这门课不展开了。其次单个db对于并发量高的应用来说通常的解决方案就是分库分表,看你如何去组织而已。如果你的场景db不是瓶颈,你100个应用用一个db实例都可以。跟事务也没关系事务是数据库本身就应该保证的,同步数据库用的是数据库日志。
2022-05-16 Wisdom一个微服务,n个实例,一个实例对应一个数据库,这种方案,有点太浪费,而且数据的一致性方面还可能会有问题,不赞同这样,京乐、淘宝也没有这样搞,感觉这里有点误导
Wisdom一个微服务,n个实例,一个实例对应一个数据库,这种方案,有点太浪费,而且数据的一致性方面还可能会有问题,不赞同这样,京乐、淘宝也没有这样搞,感觉这里有点误导作者回复: 一个微服务N个实例,只用一个数据库也可以,甚至几个微服务共享一个数据库也可以。我这里举例子是在数据库是瓶颈的时候,将数据库解耦。
2022-02-14 youngwang1228我记得是微服务说的是: 每个服务有自己单独的数据库。 假如一个服务有5个实例,每个实例独享一个数据库的话,会不会有点奢侈。 例如,一个数据库的数据量是10G,那5个库就要50G,存储成本直线上升。 而且,新加实例的话,复制一个10G数据量的库实例,时间不短吧。
youngwang1228我记得是微服务说的是: 每个服务有自己单独的数据库。 假如一个服务有5个实例,每个实例独享一个数据库的话,会不会有点奢侈。 例如,一个数据库的数据量是10G,那5个库就要50G,存储成本直线上升。 而且,新加实例的话,复制一个10G数据量的库实例,时间不短吧。作者回复: 微服务,推荐一个实例对应一个DB。是因为通常DB是瓶颈,如果微服务实例是瓶颈也可以1:n,不过有些协调成本。 数据库通常并不是那么弹性的,需要随时从0创建。通常微服务的数据库还也是需要定期精心维护的。 微服务的拆解是为了解耦数据库,当数据库积累到一定量后也要看看能否进一步拆解。 如果你的核心业务可以做到这么庞大,公司体量也会很庞大,那就需要更加高级的架构解决的问题了。
2020-09-14 PP-CIPDS-GRCBaaS 化只能基于 HTTP(RESTful)进行吗?可不可以基于 TCP,比如走 RPC 的方式?
PP-CIPDS-GRCBaaS 化只能基于 HTTP(RESTful)进行吗?可不可以基于 TCP,比如走 RPC 的方式?作者回复: BaaS可以基于RPC的。 不过http目前各种service mesh支持度比较广泛,可以做无侵入式网络接管。
2020-09-06 方勇(gopher)请问Rocketmq 10个9是怎么得出来的,是mttf 还是mttr 是一年周期么
方勇(gopher)请问Rocketmq 10个9是怎么得出来的,是mttf 还是mttr 是一年周期么作者回复: 阿里云官方提供的数据:服务可用性 99.95%,Region 化、多可用区、分布式集群化部署,确保服务高可用,即便整个机房不可用仍可正常提供消息服务;数据可靠性 99.99999999%,同步双写、超三副本数据冗余与快速切换技术确保数据可靠; 数据可靠性,是数据不会丢失。实际使用的服务可用性是99.95%,尤其因为网络等等问题无法获取数据。
2020-07-22- Geek_a5c054TypeError: Cannot read property '0' of undefined at Response.<anonymous> (/home/zyq/Downloads/todolist-backend-lesson08/index.js:182:44) 这个是为什么呀
作者回复: 读取数据库失败了,data.row.attributes[0].columnValue。请看一下08课的答复里面内容。
2020-07-063

