
编译器前端原理入门
宫文学
北京物演科技CEO
立即订阅
0 人已学习
课程目录
已完结 7 讲
01 | 理解代码:编译器的前端技术
02 | 正则文法和有限自动机:纯手工打造词法分析器
03 | 语法分析(一):纯手工打造公式计算器
04 | 语法分析(二):解决二元表达式中的难点
05 | 语法分析(三):实现一门简单的脚本语言
06 | 编译器前端工具(一):用Antlr生成词法、语法分析器
07 | 编译器前端工具(二):用Antlr重构脚本语言
编译器前端原理入门
登录|注册
02 | 正则文法和有限自动机:纯手工打造词法分析器
宫文学 2019-12-11

上一讲,我提到词法分析的工作是将一个长长的字符串识别出一个个的单词,这一个个单词就是 Token。而且词法分析的工作是一边读取一边识别字符串的,不是把字符串都读到内存再识别。你在听一位朋友讲话的时候,其实也是同样的过程,一边听,一边提取信息。
那么问题来了,字符串是一连串的字符形成的,怎么把它断开成一个个的 Token 呢?分割的依据是什么呢?本节课,我会通过讲解正则表达式(Regular Expression)和有限自动机的知识带你解决这个问题。
其实,我们手工打造词法分析器的过程,就是写出正则表达式,画出有限自动机的图形,然后根据图形直观地写出解析代码的过程。而我今天带你写的词法分析器,能够分析以下 3 个程序语句:
age >= 45
int age = 40
2+3*5
它们分别是关系表达式、变量声明和初始化语句,以及算术表达式。
接下来,我们先来解析一下“age >= 45”这个关系表达式,这样你就能理解有限自动机的概念,知道它是做词法解析的核心机制了。
解析 age >= 45
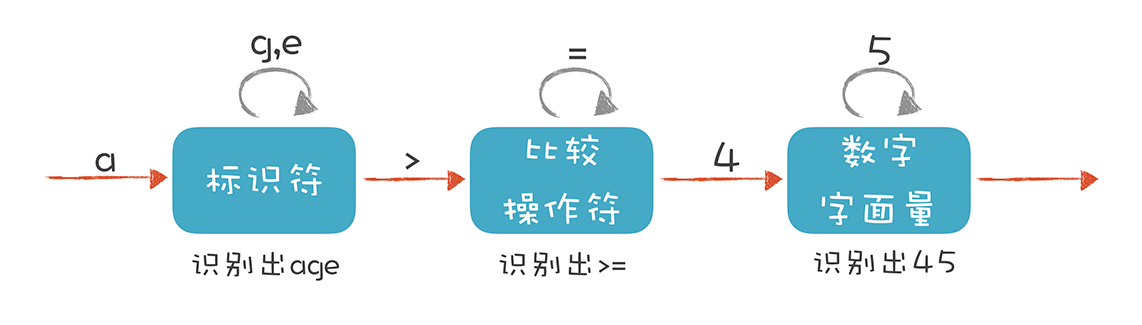
我们来描述一下标识符、比较操作符和数字字面量这三种 Token 的词法规则。
取消
完成
0/1000字
划线
笔记
复制
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。
该试读文章来自付费专栏《编译器前端原理入门》,如需阅读全部文章,
请订阅文章所属专栏。
请订阅文章所属专栏。
立即订阅

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论