06|设置高效的数据加载器
Sebastian Raschka

在前一节中,我们定义了一个自定义神经网络模型。在训练这个模型之前,我们必须简要讨论如何在 PyTorch 中创建高效的数据加载器,这些数据加载器将在训练模型时进行迭代。PyTorch 中数据加载的整体思路如图 1 所示。
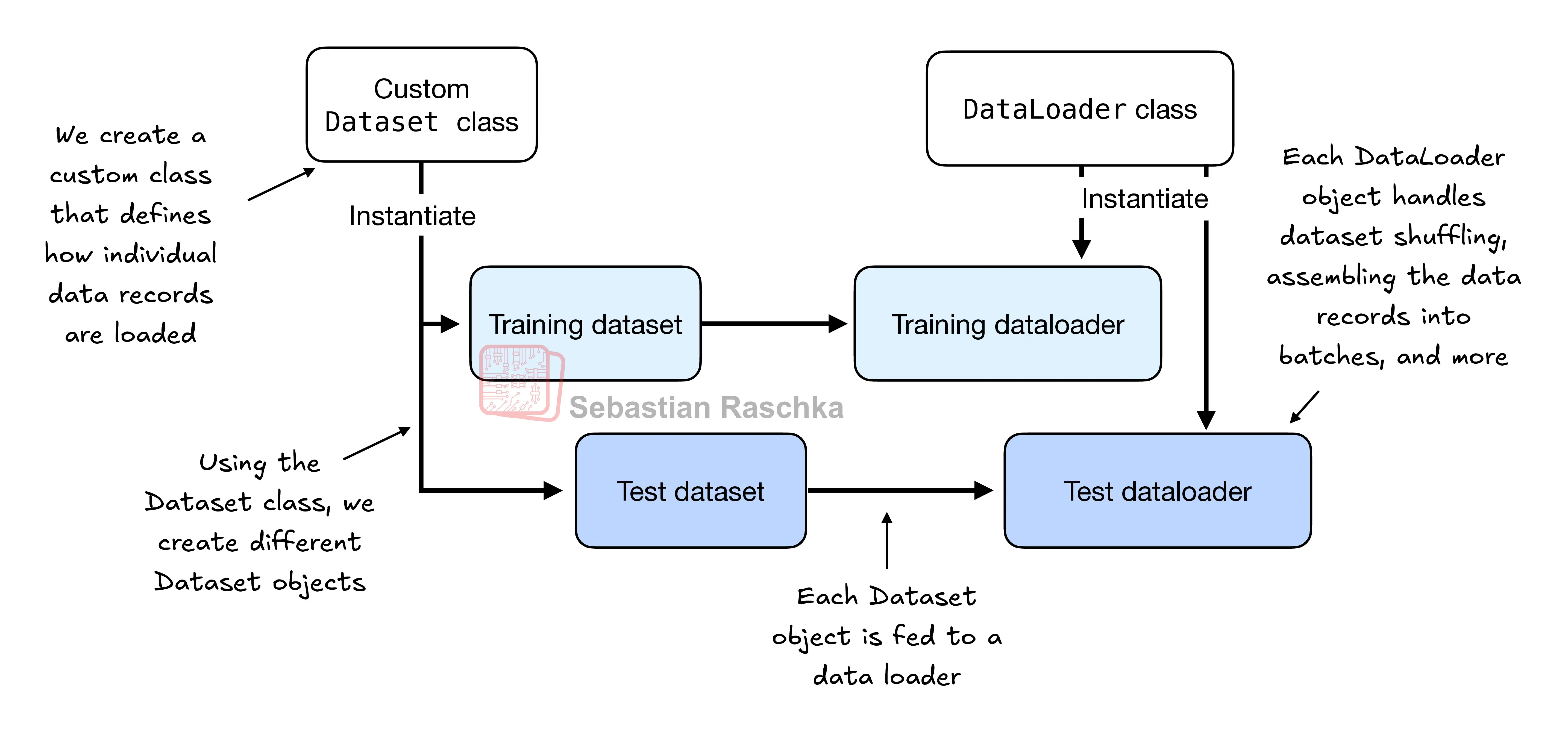
图 1 展示了 PyTorch 实现的 Dataset 和 DataLoader 类。其中,Dataset 类用于实例化定义如何加载每条数据记录的对象,而 DataLoader 则负责处理数据的打乱和批量组装方式。
根据图 1 中的说明,在本节中,我们将实现一个自定义的 Dataset 类,我们将使用该类创建训练集和测试集,然后使用这些数据集创建数据加载器。
下面我们通过创建一个简单的玩具数据集来开始,这个数据集包含 5 个训练样本,每个样本有两个特征。与训练样本相对应,我们还会创建一个包含对应类别标签的张量:其中三个样本属于类别 0,两个样本属于类别 1。此外,我们还会创建一个由两个样本组成的测试集。创建这个数据集的代码如下:
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

1. PyTorch中数据加载的整体思路是通过`Dataset`和`DataLoader`类实现数据加载和批量组装方式。 2. 自定义`Dataset`类的三个主要组件是`__init__`构造函数、`__getitem__`方法和`__len__`方法,用于实例化定义如何加载每条数据记录的对象。 3. 在`__init__`方法中,设置属性以访问后续的`__getitem__`和`__len__`方法,对于内存中的张量数据集,只需将X和y赋值给这些属性。 4. 在`__getitem__`方法中,通过索引从数据集中精确返回单个项目的指令,返回与单个训练样本或测试实例对应的特征和类别标签。 5. `__len__`方法包含获取数据集长度的指令,使用张量的`.shape`属性来返回特征数组中的行数。 6. 使用`DataLoader`类从自定义的`Dataset`类中采样数据,可以设置批次大小和是否打乱数据。 7. 遍历训练数据加载器,每个训练样本恰好被访问一次,可以设置`drop_last=True`来丢弃每个周期的最后一个批次。 8. 在`DataLoader`中的`num_workers`参数对于并行化数据加载和预处理至关重要,设置合适的值能显著提升效率,但需根据具体数据集规模和计算环境进行调整以达到最佳效果。 9. 在实际应用中,理解`num_workers`参数的权衡并审慎设置至关重要,最佳设置取决于硬件以及用于加载`Dataset`类中定义的训练示例的代码。 10. 设置`num_workers=4`通常会在许多真实数据集上带来最佳性能,但需根据具体情况进行调整。
该试读文章来自《1 小时入门 PyTorch:从张量到多 GPU 神经网络训练》,如需阅读全部文章,
请先领取课程
请先领取课程
免费领取
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论