 2019-04-30- 用户态/内核态切换执行如何串起来
2019-04-30- 用户态/内核态切换执行如何串起来
- 用户态函数栈; 通过 JMP + 参数 + 返回地址 调用函数
- 栈内存空间从高到低增长
- 32位栈结构: 栈帧包含 前一个帧的 EBP + 局部变量 + N个参数 + 返回地址
- ESP: 栈顶指针; EBP: 栈基址(栈帧最底部, 局部变量起始)
- 返回值保存在 EAX 中
- 64位栈结构: 结构类似
- rax 保存返回结果; rsp 栈顶指针; rbp 栈基指针
- 参数传递时, 前 6个放寄存器中(再由被调用函数 push 进自己的栈, 用以寻址), 参数超过 6个压入栈中
- 内核栈结构:
- Linux 为每个 task 分配了内核栈, 32位(8K), 64位(16K)
- 栈结构: [预留8字节 +] pt_regs + 内核栈 + 头部 thread_info
- thread_info 是 task_struct 的补充, 存储于体系结构有关的内容
- pt_regs 用以保存用户运行上下文, 通过 push 寄存器到栈中保存
- 通过 task_struct 找到内核栈
- 直接由 task_struct 内的 stack 直接得到指向 thread_info 的指针
- 通过内核栈找到 task_struct
- 32位 直接由 thread_info 中的指针得到
- 64位 每个 CPU 当前运行进程的 task_struct 的指针存放到 Per CPU 变量 current_task 中; 可调用 this_cpu_read_stable 进行读取展开 22 2019-04-29从网络协议课学到这里,满满的干货啊。特别是配图,太用心了,一看就是非常有心才能做出来的。谢谢刘老师!
2019-04-29从网络协议课学到这里,满满的干货啊。特别是配图,太用心了,一看就是非常有心才能做出来的。谢谢刘老师!作者回复: 谢谢鼓励
12- 2019-09-09为什么32位的处理器还需要单独压ss和esp呢? pt_regs结构体中不是已经含有这两个寄存器了么?谢谢老师 2
- 2019-09-06老师您好,在 64 位上,修改了这个问题,变成了定长的。这句话怎么理解呢?
具体在64位上是如何进行操作的呢? 2  2019-04-29看这篇内容时,查了几篇资料。
2019-04-29看这篇内容时,查了几篇资料。
在汇编代码中,函数调用的参数传递是通过把参数依次放在靠近调用者的栈的顶部来实现的。调用者获取参数时,只要相对于当前帧指针的向上偏移即可取到参数。即取调用者函数参数时执行movl 8(%ebp), %edx。作者回复: 赞,推荐这种查资料的方式,这样学到的东西就多多了
2 2019-04-290点自动发,应该是自动发布的吧
2019-04-290点自动发,应该是自动发布的吧作者回复: 是的,是的,是自动发的。
2- 2019-07-25老师,有个问题能否解答?
task_struct找内核栈过程理解了,但是反过来找,这句“而 thread_info 的位置就是内核栈的最高位置,减去 THREAD_SIZE,就到了 thread_info 的起始地址。”没懂,烦请解答一下
这里说的最高位置应该是栈顶,到了栈顶就是thread_info最低地址,那不就直接找到了吗作者回复: 不是的,对着图可以看的比较清楚
2 1 - 2019-04-29在12节里面提到“Linux的任务管理由统一的结构task_struct进行管理”。那么多核CPU的任务切换时,是不是就是将current_task切换到另一个task_struct呢?
THREAD_SIZE是固定的大小,32位系统中是8K(页大小左移一位),64位系统是16K(页大小左移二位)。TOP_OF_KERNEL_STACK_PADDING就是图“内核栈是一个非常特殊的结构”中的“预留8个字节”。
通过task_struct找内核栈的过程:
1. task_struct找内核栈是通过stack指针,直接找到内核线程栈,stack指针记录的是内核栈的首地址。
2. task_struck找内核寄存器是通过 内核栈的首地址(1中的stack指针) + (THREAD_SIZE - TOP_OF_KERNEL_STACK_PADDING)定位到pt_regs的最高位地址,再减一得到pt_regs的最低位地址(首地址)。展开作者回复: 不仅仅切换这个变量,要切换的还挺多的
1 1  2019-04-29老师,我求您了,能不能把您讲的专栏中涉及的书名加个豆瓣之类的链接😂😂,有些都重名,作者不同,😭😭不带这样玩的😭😭😭
2019-04-29老师,我求您了,能不能把您讲的专栏中涉及的书名加个豆瓣之类的链接😂😂,有些都重名,作者不同,😭😭不带这样玩的😭😭😭作者回复: 啊,好的,看来应该给英文名加作者的
1 2019-04-29文中说“接下来就是 B 的栈帧部分了,先保存的是 A 栈帧的栈底位置,也就是 EBP。因为在 B 函数里面获取 A 传进来的参数,就是通过这个指针获取的,”感觉主流编译器还是直接能通过当前 RBP 或者 RSP 来进行偏移定位到传进来的参数了吧?保存这个 A 栈底位置更多的是为了回复 A 的现场吧?
2019-04-29文中说“接下来就是 B 的栈帧部分了,先保存的是 A 栈帧的栈底位置,也就是 EBP。因为在 B 函数里面获取 A 传进来的参数,就是通过这个指针获取的,”感觉主流编译器还是直接能通过当前 RBP 或者 RSP 来进行偏移定位到传进来的参数了吧?保存这个 A 栈底位置更多的是为了回复 A 的现场吧?作者回复: 能的。
2 1 2020-02-04看完了进程数据结构,了解到了很多。请教老师一个问题:每个进程都有自己独立的虚拟地址空间,空间布局包括代码段、数据段、BSS段、堆、栈。那么进程的数据具体是怎么存储的,具体存储在进程自己虚拟地址空间中那个段。望老师看到,并解惑。多谢。
2020-02-04看完了进程数据结构,了解到了很多。请教老师一个问题:每个进程都有自己独立的虚拟地址空间,空间布局包括代码段、数据段、BSS段、堆、栈。那么进程的数据具体是怎么存储的,具体存储在进程自己虚拟地址空间中那个段。望老师看到,并解惑。多谢。- 2020-01-27请问老师,task_struct是表示内存中进程的结构体,是不是这样将用户态和内核态串起来的:
1.用户态才会有task_struct
2.用户态可以通过task_struct的stack找到内核态的空间(比如寄存器pt_regs以及内存中的内核栈)
3.内核态可以通过内核态空间中的thread_info找到内存中进程的task_struct
4.在系统调用过程中,会填充上面的中介数据(stack和thread_info)
如果简单粗略的理解,就是用户态的内存中包含了内核态的地址(stack),内核态的内存空间中(寄存器和内存)包含了用户态的地址(thread_info)
上面的理解正确吗?展开 - 2019-11-26刘老师,请教一下,什么时候用内核栈找task_struct?什么时候又反过来找?
 2019-11-25摘抄:如果说 task_struct 的其他成员变量都是和进程管理有关的,内核栈是和进程运行有关系的。
2019-11-25摘抄:如果说 task_struct 的其他成员变量都是和进程管理有关的,内核栈是和进程运行有关系的。- 2019-11-19老师 64位架构函数调用栈 图中是不是有错鸭 第1-6个参数应该是由caller存入寄存器中 在callee中使用参数是通过mov指令来使用 没有用到push指令 所以rsp寄存器的值应该和rbp值一样才对 应该指向同一个地址
 2019-10-22内核栈这个图里边预留8个字节下边的pg_regs,应该是pt_regs吧?
2019-10-22内核栈这个图里边预留8个字节下边的pg_regs,应该是pt_regs吧? 2019-10-14而 thread_info 的位置就是内核栈的最高位置,减去...
2019-10-14而 thread_info 的位置就是内核栈的最高位置,减去...
极客时间版权所有: https://time.geekbang.org/column/article/93014
这句话怎么理解?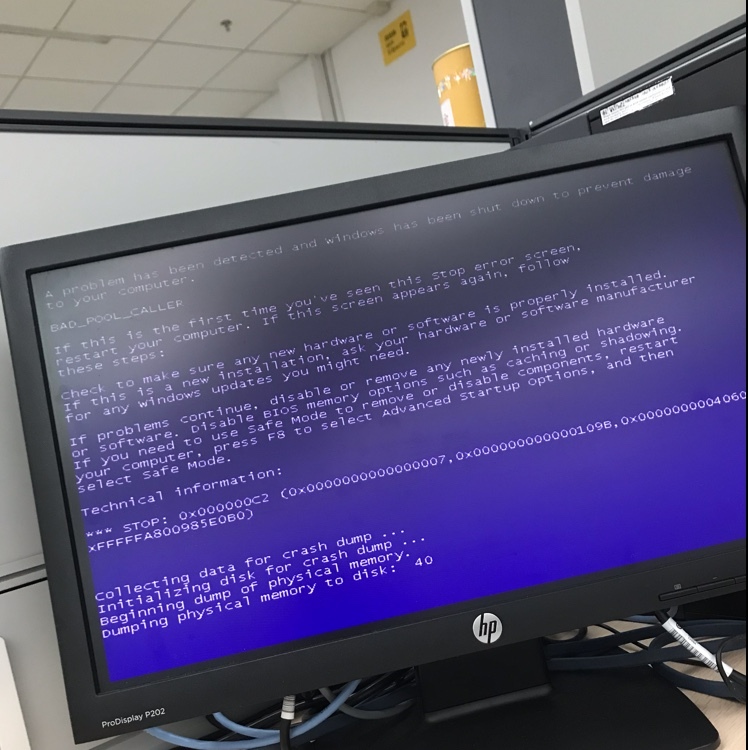 2019-09-24看懂这章,需要知道进程的内存分布图
2019-09-24看懂这章,需要知道进程的内存分布图- 2019-09-06老师你好,文中说涉及权限的改变,会压栈保存 SS、ESP 寄存器,我有个疑问是这个地方为什么只单独push这两个寄存器呢? cs、ip以及eflags寄存器呢?
 2019-08-14老师有个疑问 A调用B B应该是被调用者吧 是不是应该放在图上面部分
2019-08-14老师有个疑问 A调用B B应该是被调用者吧 是不是应该放在图上面部分作者回复: 上面是栈的底部