

03 | 字符串性能优化不容小觑,百M内存轻松存储几十G数据

该思维导图由 AI 生成,仅供参考
String 对象是如何实现的?
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

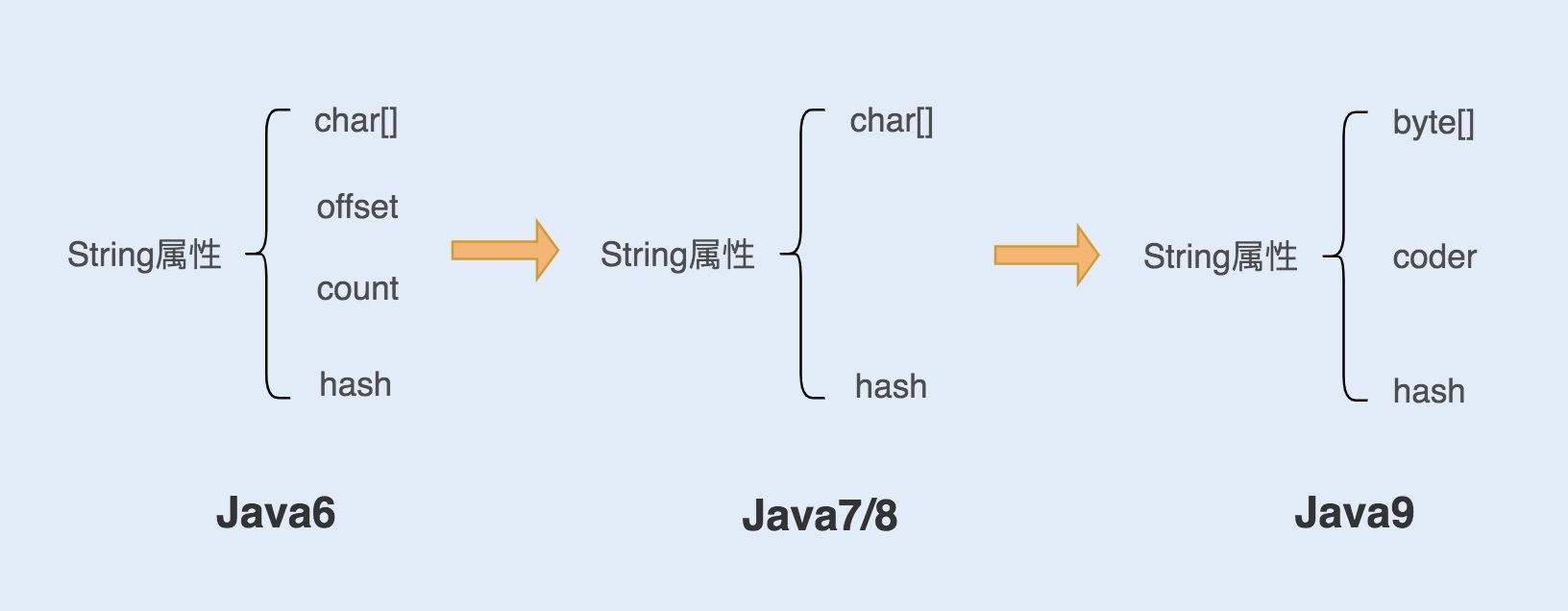
本文深入探讨了Java中String对象的实现、特性以及优化方法。首先介绍了String对象的实现方式,从Java6到Java9版本的优化过程,包括对char数组的封装、offset和count属性的变化,以及引入coder属性的原因。文章还强调了String对象的不可变性,解释了final关键字修饰的作用,以及不可变性带来的好处,如保证安全性、唯一性和实现字符串常量池。此外,文章还控诉了String对象的优化方法,特别是在构建超大字符串时,建议使用StringBuilder来提高系统性能。另外,文章还介绍了如何使用String.intern方法来节省内存空间,以及谨慎使用字符串的分割方法。总的来说,本文通过深入浅出的方式,为读者提供了关于Java中String对象优化的全面指南。
《Java 性能调优实战》,新⼈⾸单¥59

全部留言(132)
- 最新
- 精选
 KL3老师,能解释下, “String.substring 方法也不再共享 char[],从而解决了使用该方法可能导致的内存泄漏问题。” 共享char数组可能导致内存泄露问题?
KL3老师,能解释下, “String.substring 方法也不再共享 char[],从而解决了使用该方法可能导致的内存泄漏问题。” 共享char数组可能导致内存泄露问题?作者回复: 你好 KL3,在Java6中substring方法会调用new string构造函数,此时会复用原来的char数组,而如果我们仅仅是用substring获取一小段字符,而原本string字符串非常大的情况下,substring的对象如果一直被引用,由于substring的里面的char数组仍然指向原字符串,此时string字符串也无法回收,从而导致内存泄露。 试想下,如果有大量这种通过substring获取超大字符串中一小段字符串的操作,会因为内存泄露而导致内存溢出。
2019-05-253137 扫地僧答案是false,false,true。背后的原理是: 1、String str1 = "abc";通过字面量的方式创建,abc存储于字符串常量池中; 2、String str2 = new String("abc");通过new对象的方式创建字符串对象,引用地址存放在堆内存中,abc则存放在字符串常量池中;所以str1 == str2?显然是false 3、String str3 = str2.intern();由于str2调用了intern()方法,会返回常量池中的数据,地址直接指向常量池,所以str1 == str3;而str2和str3地址值不等所以也是false(str2指向堆空间,str3直接指向字符串常量池)。不知道这样理解有木有问题
扫地僧答案是false,false,true。背后的原理是: 1、String str1 = "abc";通过字面量的方式创建,abc存储于字符串常量池中; 2、String str2 = new String("abc");通过new对象的方式创建字符串对象,引用地址存放在堆内存中,abc则存放在字符串常量池中;所以str1 == str2?显然是false 3、String str3 = str2.intern();由于str2调用了intern()方法,会返回常量池中的数据,地址直接指向常量池,所以str1 == str3;而str2和str3地址值不等所以也是false(str2指向堆空间,str3直接指向字符串常量池)。不知道这样理解有木有问题作者回复: 答案非常正确,理解了这个题目基本理解了string的特性了。
2019-05-2512106 快乐的五五开自学一年居然不知道有String.intern这个方法😓😓 不过从Java8开始(大概) String.split() 传入长度为1字符串的时候并不会使用正则,这种情况还是可以用
快乐的五五开自学一年居然不知道有String.intern这个方法😓😓 不过从Java8开始(大概) String.split() 传入长度为1字符串的时候并不会使用正则,这种情况还是可以用作者回复: 非常感谢Geek的补充,我在这里也再补充一个小点,split有两种情况不会使用正则表达式: 第一种为传入的参数长度为1,且不包含“.$|()[{^?*+\\”regex元字符的情况下,不会使用正则表达式; 第二种为传入的参数长度为2,第一个字符是反斜杠,并且第二个字符不是ASCII数字或ASCII字母的情况下,不会使用正则表达式。
2019-05-25375 风轻扬老师好,诚心请教一个问题 string s1 = new string(“1”)+new string(“1”); s1.intern; string s2=“11”; s1==s2为什么是true呢,我理解s1指向的对象,s2指向的常量池地址才对啊? 然后 string s1 = new string(“1”); s1.intern; string s2=“11”; s1==s2又是false了,区别在哪? 老师,周董提的这个问题,我都琢磨一晚上了。您的回答看了好多遍,确实是看不懂,您能再解释一下吗?目前的回答,咋看也看不懂。。。。。。
风轻扬老师好,诚心请教一个问题 string s1 = new string(“1”)+new string(“1”); s1.intern; string s2=“11”; s1==s2为什么是true呢,我理解s1指向的对象,s2指向的常量池地址才对啊? 然后 string s1 = new string(“1”); s1.intern; string s2=“11”; s1==s2又是false了,区别在哪? 老师,周董提的这个问题,我都琢磨一晚上了。您的回答看了好多遍,确实是看不懂,您能再解释一下吗?目前的回答,咋看也看不懂。。。。。。作者回复: 如果看不太懂,建议先熟悉下JVM这块的知识点。我们知道,JVM从逻辑分区可以分为堆、JVM栈、本地方法栈、方法区、程序计数器,方法区中,在JDK1.8之后,包含了元空间、静态常量池、运行时常量池。 对于字符串常量,在类加载时,会将字符串放入方法区中的静态常量池,包括字符串的字面量和字符引用。而在初始化或运行时,会将字符引用转为直接引用,存放在运行时常量池。 如果是运行时动态生成的字符串对象调用intern方法,如果字符串的引用在运行时常量池不存在,则会在常量池中创建一个引用。 所以第一个通过加动态生成的“11”字符串由于在运行时常量中没有该字符串的引用,所以会在调用s1.intern时,在运行时常量池中生成一个s1的引用,当s2再次引用该字符串时,发现运行时常量池中存在相同值的字符串的引用,就直接返回s1的引用。所以s1==s2是返回的true。这也仅限于JDK1.7之后的版本。 而第二种,用于"11"在类加载时,已经存在静态常量池中,在new string(“11”)时,会在运行时常量池中创建一个“11”字符串的直接引用。而s1指向的并不是该引用,而是new string这个对象的引用。当s2=“11”时,返回的是运行时常量池中的引用。所以s1==s2返回false。
2019-08-011642 周董老师,还有一个问题网上众说纷纭,jdk1.8版本,字符串常量池和运行时常量池分别在内存哪个区?您文中的常量池是什么常量池?调用intern后字符串是在哪个常量池生成引用或者对象?麻烦老师抽空解答下,这个困扰很久了。
周董老师,还有一个问题网上众说纷纭,jdk1.8版本,字符串常量池和运行时常量池分别在内存哪个区?您文中的常量池是什么常量池?调用intern后字符串是在哪个常量池生成引用或者对象?麻烦老师抽空解答下,这个困扰很久了。作者回复: 严格来说,是静态常量池和运行时常量池,静态常量池是存放字符串字面量、符号引用以及类和方法的信息,而运行时常量池存放的是运行时一些直接引用。 运行时常量池是在类加载完成之后,将静态常量池中的符号引用值转存到运行时常量池中,类在解析之后,将符号引用替换成直接引用。 这两个常量池在JDK1.7版本之后,就移到堆内存中了,这里指的是物理空间,而逻辑上还是属于方法区(方法区是逻辑分区)。 我文中说的是两个常量池,没有具体区分,在初次加载时,是字面量是加载到了静态常量池中,解析之后会将引用加载到运行时常量池。 intern方法生成的引用或对象是在运行时常量池中。
2019-08-01231- Teanmy老师好,有一点始终想不明白,请老师解惑,非常感谢! 老师先帮忙看看关于这两行代码,我的分析是否正确: str1 = "abc"; str2 = new String("abc") str1 = "abc"; 1.str1,首先是在字符串常量池中寻找"abc",找到则取其地址,找不到则创建并返回其地址 2.将该地址赋值给栈中的str1 str2 = new String("abc") 1.在堆中创建String对象,我查阅了String构造方法源码,实际值取的是"abc"的(此时"abc"已经存在字符串常量池中)引用,也就是说,str2还是指向常量池,并没有创建新的"abc"。 public String(String original) { this.value = original.value; this.hash = original.hash; } 2.堆中创建完String对象,将该对象的地址赋值给栈变量str2 疑问: 既然不管是以上哪种方式,最终实际引用的还是常量池中的"abc",str2 = new String("abc")只是增加了一个堆中String的“空壳”对象而已(因为实际上char[]指向的还是常量池中的"abc"),这个空壳对象并不会占用过多内存。而.intern的实质只是减少了这个中间的String空壳对象,那何来twitter通过.intern减少大量内存?
作者回复: 你好 teanmy。运行时创建的字符串对象只会在堆中创建一个对象。在这个前提下,如果有相同值的对象创建,使用intern可以减少重复字符串的创建。例如,有广东省/深圳市/南山区,如果有千万个人发布消息,创建了地址对象,这样导致千万个“广东省”对象在堆内存中创建,如果长时间引用,这些对象都没法释放,使用intern将“广东省”放到常量池中,其他对象引用常量池中的同一个“广东省”字符串,而堆中的千万个对象将被回收。 如果有疑问,请继续留言。
2019-06-02423  失火的夏天开头题目答案是false false true str1是建立在常量池中的“abc”,str2是new出来,在堆内存里的,所以str1!=str2, str3是通过str2..intern()出来的,str1在常量池中已经建立了"abc",这个时候str3是从常量池里取出来的,和str1指向的是同一个对象,自然也就有了st1==str3,str3!=str2了
失火的夏天开头题目答案是false false true str1是建立在常量池中的“abc”,str2是new出来,在堆内存里的,所以str1!=str2, str3是通过str2..intern()出来的,str1在常量池中已经建立了"abc",这个时候str3是从常量池里取出来的,和str1指向的是同一个对象,自然也就有了st1==str3,str3!=str2了作者回复: 这里我纠正下,str3是intern返回的引用,intern而不是创建出来的。 你的答案是正确的!
2019-05-2521 Only now看了本篇几乎全部留言, 感觉包括老师在内, 对于 "字符串常量池" 和 "常量池", 这俩概念用的很混。 对于jdk7 以及之前的jvm版本不再去深究了, 它的字符串常量池存在于方法区, 但是jdk8以后, 它存在于Java堆中, 唯一, 且由java.lang.String类维护, 它和类文件常量池, 运行时常量池没有半毛钱的关系。 最后我有个疑问问老师, 字符串常量池中的对象, 在失去了所有外部引用之后, 会被gc掉吗?
Only now看了本篇几乎全部留言, 感觉包括老师在内, 对于 "字符串常量池" 和 "常量池", 这俩概念用的很混。 对于jdk7 以及之前的jvm版本不再去深究了, 它的字符串常量池存在于方法区, 但是jdk8以后, 它存在于Java堆中, 唯一, 且由java.lang.String类维护, 它和类文件常量池, 运行时常量池没有半毛钱的关系。 最后我有个疑问问老师, 字符串常量池中的对象, 在失去了所有外部引用之后, 会被gc掉吗?作者回复: 非常感谢only now的总结,这一讲中没有详细去区分常量池,而是在强调字符串的使用,后面我们在JVM中可以再一起研究下常量池。 JVM文献中提到方法区是存在垃圾回收。我们可以通过intern方法来验证这个gc问题,通过大量请求请求某个接口,传入参数创建字符串对象,之后通过intern方法在常量池中生成字符串对象,之后失去引用,观察gc情况。
2019-05-2919 Zend“在字符串变量中,对象是会创建在堆内存中,同时也会在常量池中创建一个字符串对象,复制到堆内存对象中,并返回堆内存对象引用。” 比如: 是从常量池中复制到堆内存,这时常量池中字符串与堆内存字符串是完全独立的,内部也不存在引用关系?
Zend“在字符串变量中,对象是会创建在堆内存中,同时也会在常量池中创建一个字符串对象,复制到堆内存对象中,并返回堆内存对象引用。” 比如: 是从常量池中复制到堆内存,这时常量池中字符串与堆内存字符串是完全独立的,内部也不存在引用关系?作者回复: 你好 Zend,具体的复制过程是先将常量池中的字符串压入栈中,在使用string的构造方法时,会拿到栈中的字符串作为构造方法的参数。这里我纠正一点,今天我查看了下这个构造函数,String的构造函数是一个char数组赋值过程,不是new char[]重新创建,所以是引用了常量池中的字符串对象,存在引用关系。
2019-05-2614 风翱使用 intern 方法需要注意的一点是,一定要结合实际场景。因为常量池的实现是类似于一个 HashTable 的实现方式,HashTable 存储的数据越大,遍历的时间复杂度就会增加。如果数据过大,会增加整个字符串常量池的负担。 像国家地区是有边界的。像其他情况,怎么把握这个度呢?
风翱使用 intern 方法需要注意的一点是,一定要结合实际场景。因为常量池的实现是类似于一个 HashTable 的实现方式,HashTable 存储的数据越大,遍历的时间复杂度就会增加。如果数据过大,会增加整个字符串常量池的负担。 像国家地区是有边界的。像其他情况,怎么把握这个度呢?作者回复: 如果对空间要求高于时间要求,且存在大量重复字符串时,可以考虑使用常量池存储。 如果对查询速度要求很高,且存储字符串数量很大,重复率很低的情况下,不建议存储在常量池中。 具体可以通过模拟测试自己的场景,对比两种存储方式的性能,通过数据来给自己答案。
2019-05-25313

