下载APP
登录
关闭
讲堂
算法训练营
Python 进阶训练营
企业服务
极客商城
客户端下载
兑换中心
渠道合作
推荐作者
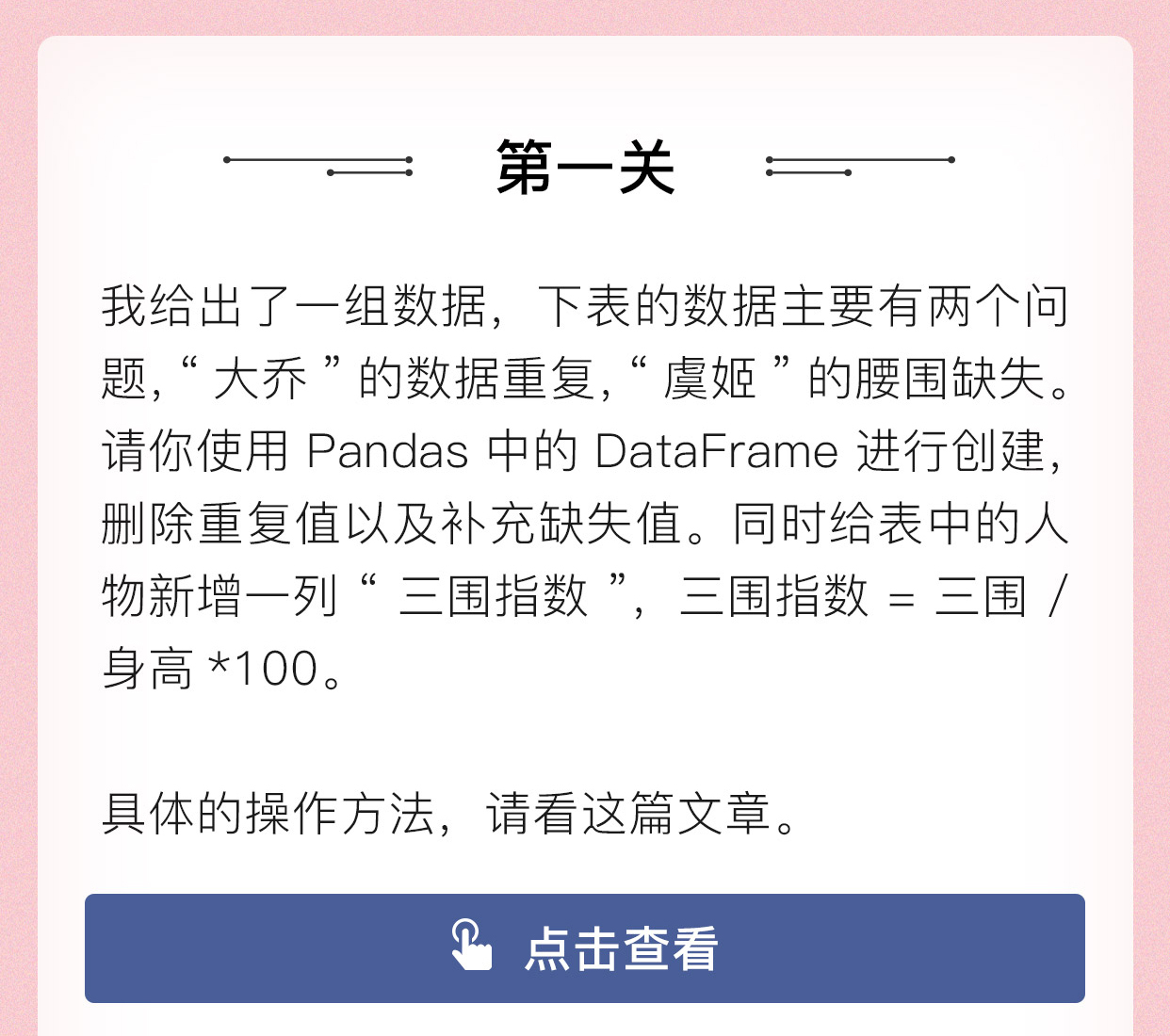
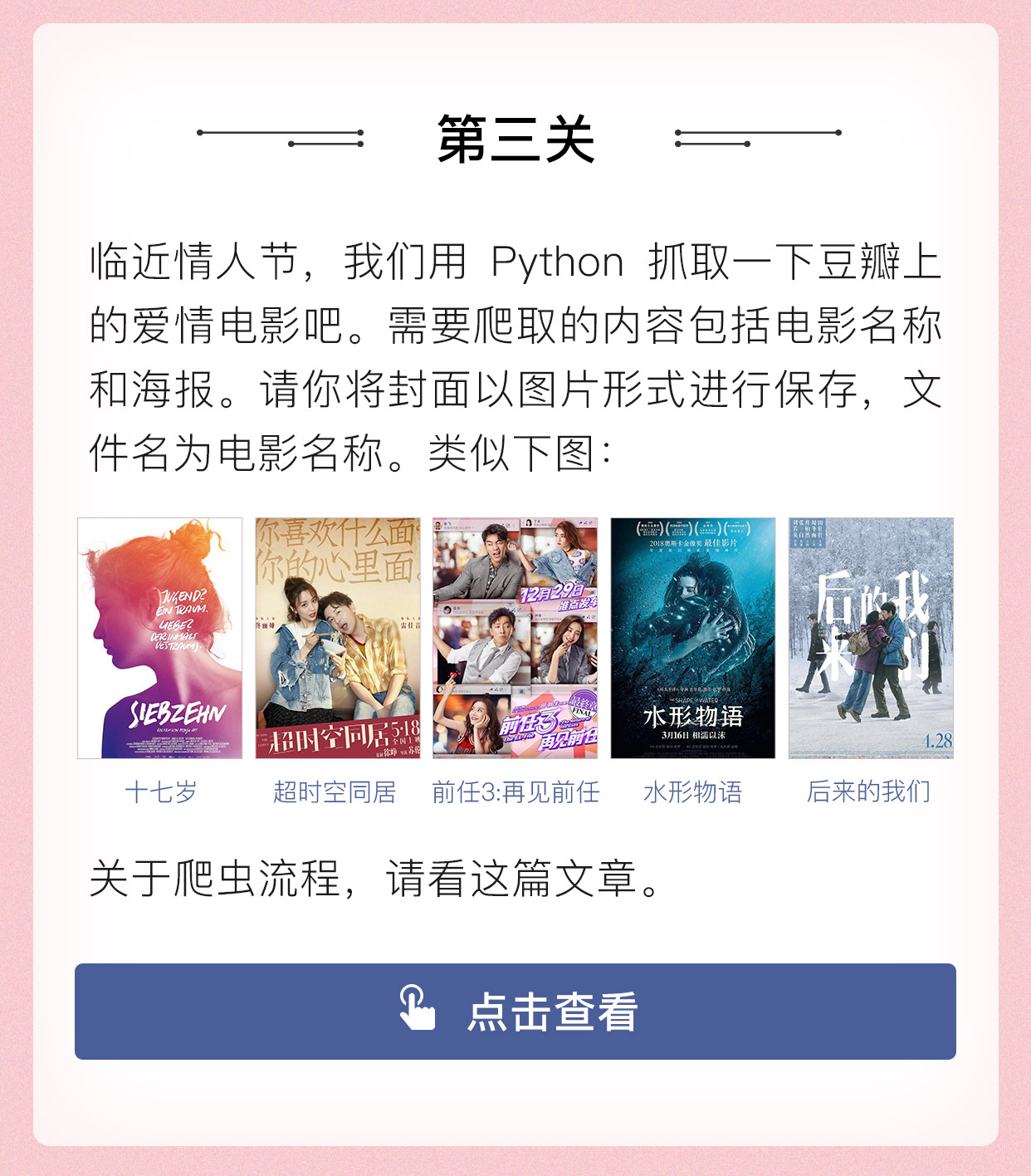
情人节教你用数据分析「花式撩妹」
2019-02-20 极客时间




写留言
精选留言(37)
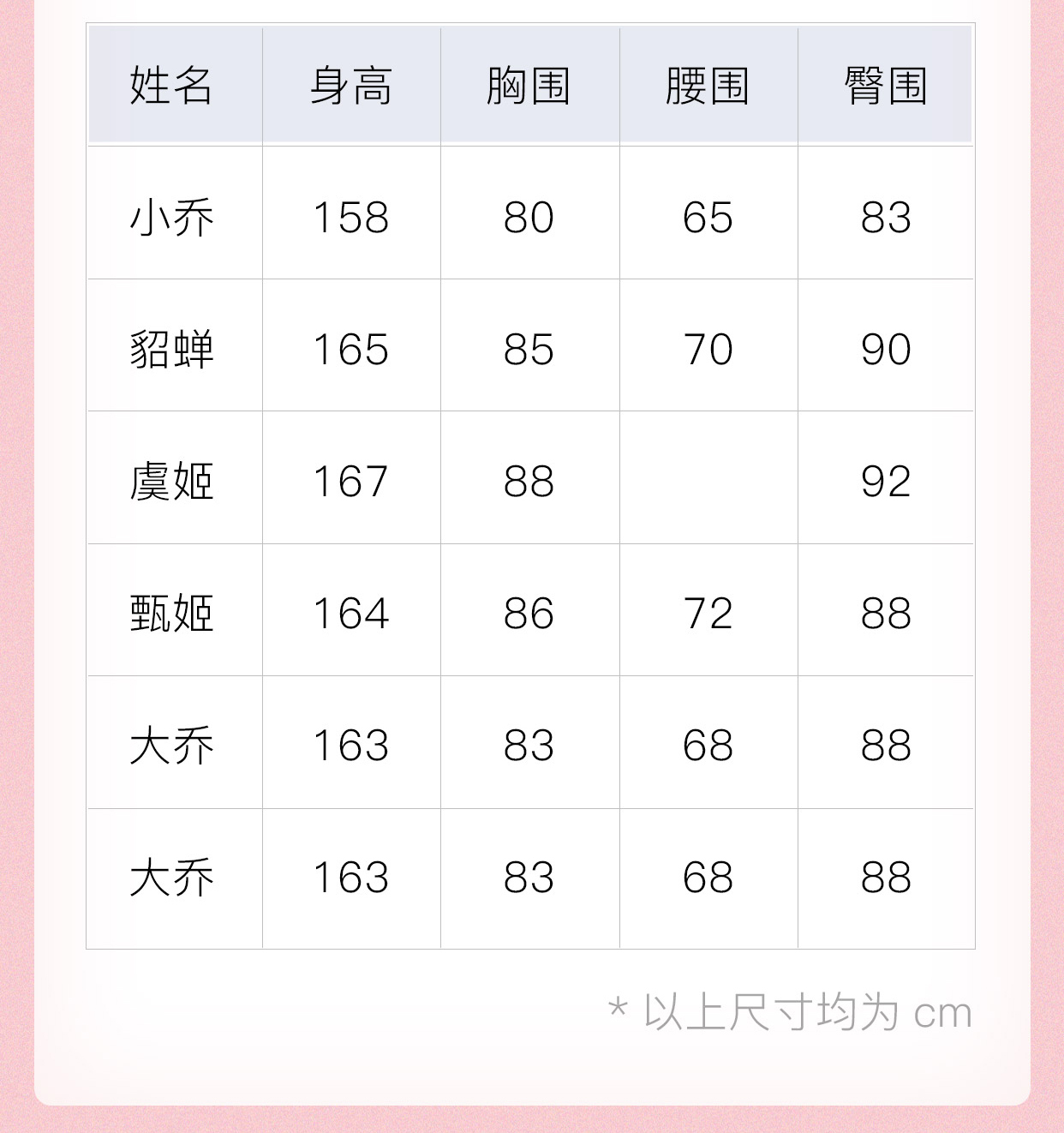
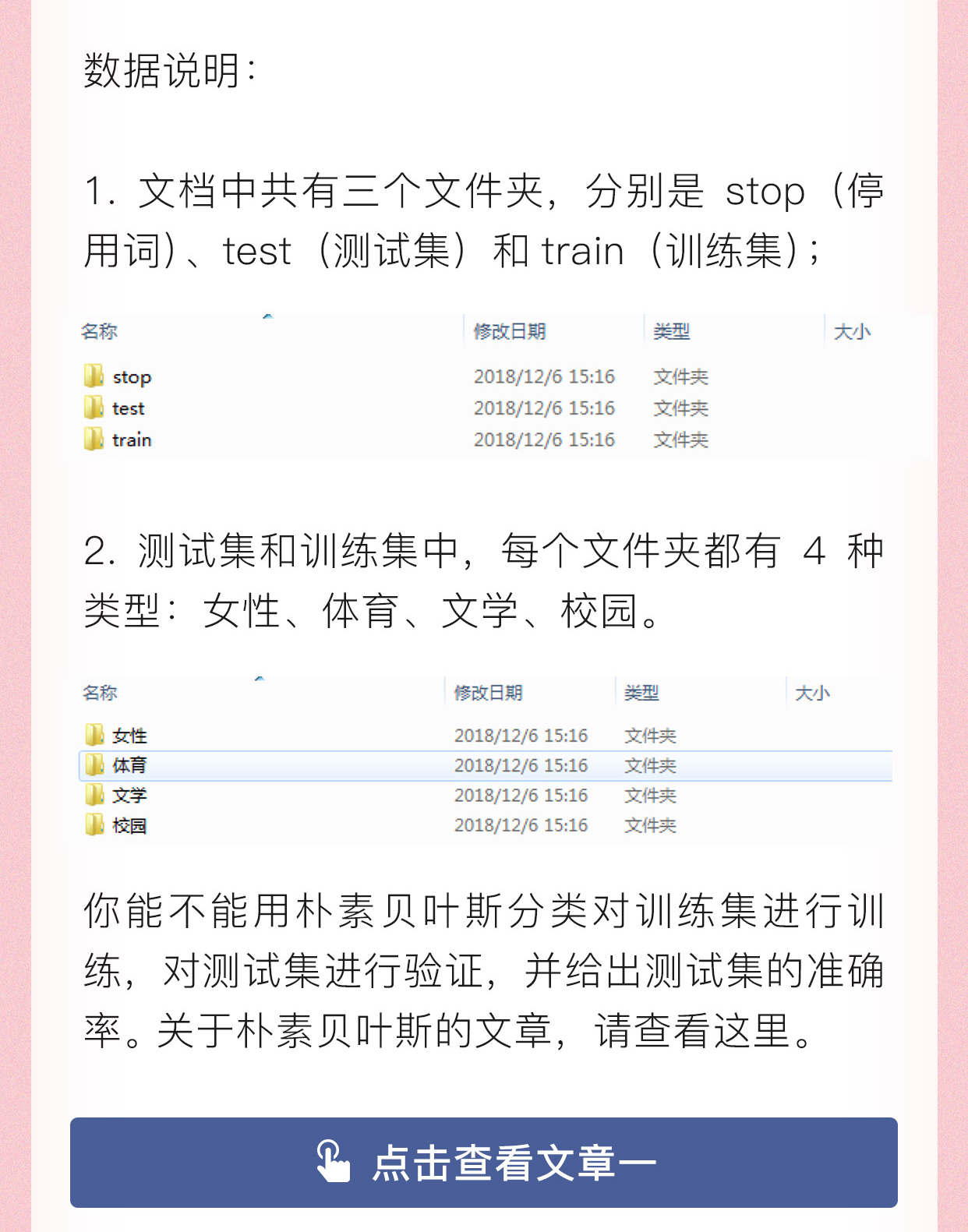
 2019-02-13进阶题答案为:
2019-02-13进阶题答案为:
import os
import codecs
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
def get_data(content_path):
first_class = os.listdir(content_path)
first_path = [os.path.join(content_path, f_class) for f_class in first_class]
content_list = []
label_list = []
for f_path in first_path:
second_path = [os.path.join(f_path, _path) for _path in os.listdir(f_path)]
for s_path in second_path:
print(s_path)
content = open(s_path, encoding='gbk').read()
content_list.append(content)
label_list.append(f_path.split('/')[-1])
print('done')
return content_list, label_list
def seg_sentence(sentence):
word_list = jieba.lcut(sentence)
words = ''
for w in word_list:
if w not in stop_words:
words += w
words += " "
return words
if __name__ == '__main__':
stop_words = [line.strip() for line in codecs.open('stopword.txt', encoding='utf-8').readlines()]
train_path = 'train/'
train_content, train_labels = get_data(content_path=train_path)
train_content = list(map(seg_sentence, train_content))
test_path = 'test/'
test_content, test_labels = get_data(content_path=test_path)
test_content = list(map(seg_sentence, test_content))
tf = TfidfVectorizer(stop_words=stop_words, max_df=0.5)
train_features = tf.fit_transform(train_content)
train_vocabulary = tf.get_feature_names()
clf = MultinomialNB(alpha=0.001).fit(train_features, train_labels)
test_tf = TfidfVectorizer(stop_words=stop_words, max_df=0.5, vocabulary=train_vocabulary)
test_features = test_tf.fit_transform(test_content)
predict_labels = clf.predict(test_features)
accuracy = metrics.accuracy_score(test_labels, predict_labels)
print("Test Accuracy: ", accuracy)展开 5 2019-02-17场景题答案为:
2019-02-17场景题答案为:
# coding:utf-8
import requests
import json
def download(src, name):
try:
path = './%s.jpg' % name
r = requests.get(src, timeout=15)
fp = open(path, 'wb')
fp.write(r.content)
fp.close()
except Exception:
print "图片无法下载"
query = '爱情'
page_number = 1
for p in range(page_number):
print "开始下载页面:%s" % (p+1)
url = 'https://movie.douban.com/j/search_subjects?type=movie&tag=%s&sort=recommend&page_limit=20&page_start=%s' % (query, p*20)
response = requests.get(url)
content = response.text
data_dict = json.loads(content)
img_urls = [info_dict['cover'] for info_dict in data_dict['subjects']]
img_name = [info_dict['title'] for info_dict in data_dict['subjects']]
for i in list(zip(img_urls, img_name)):
download(i[0], i[1])
print "下载页面:%s完成" % (p+1)展开 4- 2019-02-17进阶题答案:91%
import os
import codecs
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
def prepare_data(path):
categories = os.listdir(path)
category_paths = [os.path.join(path, category.decode("gbk")) for category in categories]
data_list = []
label_list = []
for c_path in category_paths:
file_paths = [os.path.join(c_path, file_name) for file_name in os.listdir(c_path)]
for f_path in file_paths:
with codecs.open(f_path, encoding='gbk') as f_handler:
try:
content = f_handler.read()
data_list.append(content)
label_list.append(os.path.basename(c_path))
except Exception as e:
print "Exception in %s with %s" % (f_path, e)
return data_list, label_list
parent_path = ""
stop_file = os.path.join(parent_path, "stop", "stopword.txt")
with codecs.open(stop_file, encoding='utf-8') as file_handler:
stop_words = [line.strip() for line in file_handler.readlines()]
stop_words.append("LOTOzf")
train_path = os.path.join(parent_path, "train")
train_data, train_labels = prepare_data(train_path)
train_data_tokenized = [" ".join(jieba.lcut(s)) for s in train_data]
test_path = os.path.join(parent_path, "test")
test_data, test_labels = prepare_data(test_path)
test_data_tokenized = [" ".join(jieba.lcut(s)) for s in test_data]
tf = TfidfVectorizer(stop_words=stop_words, max_df=0.5)
train_features = tf.fit_transform(train_data_tokenized)
train_vocabulary = tf.get_feature_names()
clf = MultinomialNB(alpha=0.001).fit(train_features, train_labels)
test_tf = TfidfVectorizer(stop_words=stop_words, max_df=0.5, vocabulary=train_vocabulary)
test_features = test_tf.fit_transform(test_data_tokenized)
predict_labels = clf.predict(test_features)
accuracy = metrics.accuracy_score(test_labels, predict_labels)
print "Test Accuracy: %s" % accuracy展开 4 - 2019-02-13场景题答案为:
import requests
import json
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Host": "movie.douban.com",
"Referer": "https://movie.douban.com/",
"Upgrade-Insecure-Requests": '1',
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
}
def download(src, name):
picture_path = './' + str(name) + '.jpg'
try:
response = requests.get(src, timeout=15)
fp = open(picture_path, 'wb')
fp.write(response.content)
fp.close()
except requests.exceptions.ConnectionError:
print("Image can not download!!!")
def spider(query, page_no):
for p in range(page_no):
print("Begin page :", p+1)
url = 'https://movie.douban.com/j/search_subjects?type=movie&tag=' + query + '&sort=recommend&page_limit=20&page_start=' + str(p*20)
response = requests.get(url, headers=headers)
content = response.text
data_dict = json.loads(content)
img_urls = [info_one['cover'] for info_one in data_dict['subjects']]
img_name = [info_one['title'] for info_one in data_dict['subjects']]
img_info = list(zip(img_urls, img_name))
for i in img_info:
download(src=i[0], name=i[1])
print("download picture {} finished!".format(i[1]))
print("Finish page :", p+1)
if __name__ == '__main__':
query = '爱情'
spider(query=query, page_no=2)展开 4 - 2019-02-13基础题答案为:
import pandas as pd
df = pd.DataFrame({'姓名': ['小乔', '貂蝉', '虞姬', '甄姬', '大乔', '大乔'],
'身高': [158, 165, 167, 164, 163, 163],
'胸围': [80, 85, 88, 86, 83, 83],
'腰围': [65, 70, None, 72, 68, 68],
'臀围': [83, 90, 92, 88, 88, 88]})
# 删除重复值
df = df.drop_duplicates(df)
# 填充缺失值:均值填充
df['腰围'].fillna(df['腰围'].mean(), inplace=True)
# 新增变量:三围指数
df['三围指数'] = (df['胸围'] + df['腰围'] + df['臀围'])/df['身高']*100展开 4 - 2019-02-13基础题答案为:
# coding:utf-8
import pandas as pd
from decimal import Decimal
df = pd.DataFrame({'姓名': ['小乔', '貂蝉', '虞姬', '甄姬', '大乔', '大乔'],
'身高': [158, 165, 167, 164, 163, 163],
'胸围': [80, 85, 88, 86, 83, 83],
'腰围': [65, 70, None, 72, 68, 68],
'臀围': [83, 90, 92, 88, 88, 88]})
print df
# Remove duplicated data
df.drop_duplicates(inplace=True)
print df
# Fill None data
df['腰围'].fillna(df['腰围'].mean(), inplace=True)
print df
# Add new column
df['三围指数'] = ((df['胸围'] + df['腰围'] + df['臀围']) / df['身高'] * 100).apply(
lambda x: Decimal(str(x)).quantize(Decimal('0.00')))
print df展开 4  2019-02-12场景题答案
2019-02-12场景题答案
# 场景题
import requests
import json
# 下载图片
def download(url, title):
dir = './' + title + '.jpg'
try:
pic = requests.get(url)
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
except requests.exceptions.ConnectionError:
print('图片无法下载')
for num in range(0, 1000, 20):
# 构造url,翻页变换参数为start=, tag=电影, gender=爱情, 改变start=后面的数字,可以爬取不同的页
url = 'https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=%E7%94%B5%E5%BD%B1&start='\
+ str(num)+'&genres=%E7%88%B1%E6%83%85'
html = requests.get(url).text
# 转为json格式
res = json.loads(html, encoding='utf-8')
for result in res['data']:
cover = result['cover']
title = result['title']
download(cover, title)展开 3- 2019-02-12进阶题答案
# 进阶题
import os
import jieba
import io
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
# 分词
def cut_text(path_name):
str = ''
f = open(path_name, 'rb', ).read()
text = jieba.cut(f)
for word in text:
str += word + ' '
return str
# 构造训练集
def loadtrainset(path,label):
allfiles = os.listdir(path)
train = []
labels = []
for file in allfiles:
path_name = path+"/"+file
train.append(cut_text(path_name))
labels.append(label)
return train, labels
# 训练集
train, labels = loadtrainset(r'E:\文件\Dataset\train\女性', '女性')
train1, labels1 = loadtrainset(r'E:\文件\Dataset\train\体育', '体育')
train2, labels2 = loadtrainset(r'E:\文件\Dataset\train\文学', '文学')
train3, labels3 = loadtrainset(r'E:\文件\Dataset\train\校园', '校园')
train_data = train + train1 + train2 + train3
train_label = labels + labels1 + labels2 + labels3
# 测试集
test, labels = loadtrainset(r'E:\文件\Dataset\test\女性', '女性')
test1, labels1 = loadtrainset(r'E:\文件\Dataset\test\体育', '体育')
test2, labels2 = loadtrainset(r'E:\文件\Dataset\test\文学', '文学')
test3, labels3 = loadtrainset(r'E:\文件\Dataset\test\校园', '校园')
test_data = test + test1 + test2 + test3
test_label = labels + labels1 + labels2 + labels3
# 加载停词表
stop_words = [line.strip() for line in io.open('E:\文件\Dataset\stop\stopword.txt', encoding='utf-8').readlines()]
# 训练集转换
tf = TfidfVectorizer(stop_words=stop_words, max_df=0.5)
features = tf.fit_transform(train_data)
# 加载分类器
clf = MultinomialNB(alpha=0.001)
clf.fit(features, train_label)
# 测试集转化
tf1 = TfidfVectorizer(stop_words=stop_words, max_df=0.5, vocabulary=tf.vocabulary_)
test_feat = tf1.fit_transform(test_data)
# 预测,输出准确率
pred_labels = clf.predict(test_feat)
print(metrics.accuracy_score(test_label, pred_labels))展开 3  2019-02-12第一题答案为:
2019-02-12第一题答案为:
import pandas as pd
from pandas import DataFrame
data = {'身高':[158, 165, 167, 164, 163, 163], '胸围': [80, 85, 88, 86, 83, 83], '腰围': [65, 70, None, 72, 68, 68],
'臀围': [83, 90, 92, 88, 88, 88], '胸围指数': ['','', '', '', '', ''],
'腰围指数': ['', '', '', '', '', ''],
'臀围指数': ['', '', '', '', '', '']}
df = DataFrame(data, index=['小乔', '貂蝉', '虞姬', '甄姬', '大乔', '大乔'])
df = df.drop_duplicates()
print(df)
# 以其他人的腰围平均值填充空缺值
df['腰围'].fillna(df['腰围'].mean(), inplace=True)
print(df)
# 定义计算三围指数的函数
def sanweizhishu(df):
df['胸围指数'] = df['胸围']/df['身高'] * 100
df['腰围指数'] = df['腰围']/df['身高'] * 100
df['臀围指数'] = df['臀围']/df['身高'] * 100
return df
# 填入三围指数
df = df.apply(sanweizhishu, axis=1)
print(df)
第二题答案:
因为代码写的比较长,分了多个文件,所以这里提供github地址
https://github.com/zhouwei713/data_analysis/tree/master/document_sort展开 3 2019-02-13基础题
2019-02-13基础题
https://github.com/hotheat/Three_exercises/tree/master/%E5%9F%BA%E7%A1%80%E9%A2%98
进阶题(预测率只有 57%,有需要改进的地方请指教)
https://github.com/hotheat/Three_exercises/tree/master/Two
场景题
https://github.com/hotheat/Three_exercises/tree/master/%E5%9C%BA%E6%99%AF%E9%A2%98展开 2- 2019-02-13第三题答案:
import requests
import json
def deal_pic(url, name):
pic = requests.get(url)
with open(name + '.jpg', 'wb') as f:
f.write(pic.content)
def get_poster():
for i in range(0, 9000, 20):
url = 'https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=电影&start=%s&genres=爱情' % i
req = requests.get(url).text
req_dict = json.loads(req)
for j in req_dict['data']:
name = j['title']
poster_url = j['cover']
print(name, poster_url)
deal_pic(poster_url, name)
if __name__ == "__main__":
get_poster()展开 2  2019-02-12第一关基础题答案为:
2019-02-12第一关基础题答案为:
import pandas as pd
df = pd.DataFrame({'姓名': ['小乔', '貂蝉', '虞姬', '甄姬', '大乔', '大乔'],
'身高': [158, 165, 167, 164, 163, 163],
'胸围': [80, 85, 88, 86, 83, 83],
'腰围': [65, 70, None, 72, 68, 68],
'臀围': [83, 90, 92, 88, 88, 88]})
# 去除重复行
df = df.drop_duplicates()
# 补充缺失值
df['腰围'].fillna(df['腰围'].mean(), inplace=True)
# 新增列“三围指数”
df['三围指数'] = (df['胸围'] + df['腰围'] + df['臀围']) / df['身高'] * 100
print(df)展开 2 2019-02-15第三关
2019-02-15第三关
重在参与,重在学习。
参考了周萝卜和Aaron Cheun的代码。
问题:我用浏览器无法获取周萝卜和Aaron Cheun中的json返回链接,测试Aaron Cheun中的链接可用,于是就直接拿来用了。现在还是不知道https://api.douban.com/v2/movie/search?tag=%E7%88%B1%E6%83%85&start=0&count=10这个链接怎么得到的…………
import requests
import json
# 下载图片
def download(url, title):
dir = './pic/' + title + '.jpg'
try:
pic = requests.get(url)
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
except requests.exceptions.ConnectionError:
print('图片无法下载')
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3510.2 Safari/537.36}'}
for num in range(0, 1000, 20):
url = 'https://api.douban.com/v2/movie/search?tag=爱情&start='\
+ str(num)+'&count=20'
html = requests.get(url,headers = headers).text
# 转为json格式
res = json.loads(html, encoding='utf-8')
# print(res)
for result in res['subjects']:
cover = result['images']['large']
print(cover)
title = result['title']
print(title)
download(cover, title)展开 1- 2019-02-14第二关
参考了大白牙的代码,在唐吉柯德的帮助下搞定,非常感谢!
https://blog.csdn.net/canf07/article/details/87259992 1 - 2019-02-14第一关,重在参与,重在学习O(∩_∩)O
import pandas as pd
df = pd.DataFrame({'姓名': ['小乔', '貂蝉', '虞姬', '甄姬', '大乔', '大乔'],
'身高': [158, 165, 167, 164, 163, 163],
'胸围': [80, 85, 88, 86, 83, 83],
'腰围': [65, 70, None, 72, 68, 68],
'臀围': [83, 90, 92, 88, 88, 88]})
print(df)
# 删除重复值
df.drop_duplicates(['姓名'],inplace=True)
print(df)
# 填充缺失值:均值填充
df['腰围'].fillna(df['腰围'].mean(), inplace=True)
print(df)
# 新增变量:三围指数
df['三围指数'] = (df['胸围'] + df['腰围'] + df['臀围'])/df['身高']*100
print(df)展开 1 - 2019-02-13第一关:
import pandas as pd
import numpy as np
data_girls = {'姓名':['小乔','貂蝉','虞姬','甄姬','大乔','大乔'],
'身高':[158,165,167,164,163,163],
'胸围':[80,85,88,86,83,83],
'腰围':[65,70,None,72,68,68],
'臀围':[83,90,92,88,88,88]}
df_girls = pd.DataFrame(data_girls)
df_girls.drop_duplicates('姓名',inplace = True)
df_girls['腰围'].fillna(np.ceil(df_girls['腰围'].mean()),inplace = True)
df_girls['三围指数'] = (df_girls.sum(axis = 1)-df_girls['身高'])/df_girls['身高']
print(df_girls)展开 1  2019-02-13基础题答案为:
2019-02-13基础题答案为:
import pandas as pd
df = pd.DataFrame({'姓名': ['小乔', '貂蝉', '虞姬', '甄姬', '大乔', '大乔'],
'身高': [158, 165, 167, 164, 163, 163],
'胸围': [80, 85, 88, 86, 83, 83],
'腰围': [65, 70, None, 72, 68, 68],
'臀围': [83, 90, 92, 88, 88, 88]})
# 去除重复行
df = df.drop_duplicates()
# 补充缺失值
df['腰围'].fillna(df['腰围'].mean(), inplace=True)
# 新增列“三围指数”
df['三围指数'] = (df['胸围'] + df['腰围'] + df['臀围']) / df['身高'] * 100
print(df)
谢谢!展开 1 2019-02-13第一关答案是:
2019-02-13第一关答案是:
import pandas as pd
df = pd.DataFrame({'姓名': ['小乔', '貂蝉', '虞姬', '甄姬', '大乔', '大乔'],
'身高': [158, 165, 167, 164, 163, 163],
'胸围': [80, 85, 88, 86, 83, 83],
'腰围': [65, 70, None, 72, 68, 68],
'臀围': [83, 90, 92, 88, 88, 88]})
# 去除重复行
df = df.drop_duplicates()
# 补充缺失值
df['腰围'].fillna(df['腰围'].mean(), inplace=True)
# 新增列“三围指数”
df['三围指数'] = (df['胸围'] + df['腰围'] + df['臀围']) / df['身高'] * 100
print(df)展开 1- 2019-02-13#第一关答案
import pandas as pd
import numpy as np
df = pd.DataFrame({'姓名': ['小乔', '貂蝉', '虞姬', '甄姬', '大乔', '大乔'], '身高': [158, 165, 167, 164, 163, 163], '胸围': [80, 85, 88, 86, 83, 83], '腰围': [65, 70, np.nan, 72, 68, 68], '臀围': [83, 90, 92, 88, 88, 88]} )
df = df.set_index(['姓名'])
# 去除重复
df.drop_duplicates(inplace=True)
# 数据填充, 觉得以均值填充比较靠谱
df['腰围'] = df['腰围'].fillna(df['腰围'].mean())
#新增三列 三围指数由三个指数构成:
df['胸围指数'] = (df['胸围'] / df['身高'])*100
df['腰围指数'] = (df['腰围'] / df['身高'])*100
df['臀围指数'] = (df['臀围'] / df['身高'])*100
print(df)展开 1  2019-02-131
2019-02-131
第一关基础题答案为:
import pandas as pd
df = pd.DataFrame({'姓名': ['小乔', '貂蝉', '虞姬', '甄姬', '大乔', '大乔'],
'身高': [158, 165, 167, 164, 163, 163],
'胸围': [80, 85, 88, 86, 83, 83],
'腰围': [65, 70, None, 72, 68, 68],
'臀围': [83, 90, 92, 88, 88, 88]})
# 去除重复行
df = df.drop_duplicates()
# 补充缺失值
df['腰围'].fillna(df['腰围'].mean(), inplace=True)
# 新增列“三围指数”
df['三围指数'] = (df['胸围'] + df['腰围'] + df['臀围']) / df['身高'] * 100
print(df)展开 1