10 | 发号器:如何保证分库分表后ID的全局唯一性?
2019-10-09 唐扬
《高并发系统设计 40 问》
课程介绍

讲述:唐扬
时长:大小12.77M
你好,我是唐扬。
在前面两节课程中,我带你了解了分布式存储两个核心问题:数据冗余和数据分片,以及在传统关系型数据库中是如何解决的。当我们面临高并发的查询数据请求时,可以使用主从读写分离的方式,部署多个从库分摊读压力;当存储的数据量达到瓶颈时,我们可以将数据分片存储在多个节点上,降低单个存储节点的存储压力,此时我们的架构变成了下面这个样子:
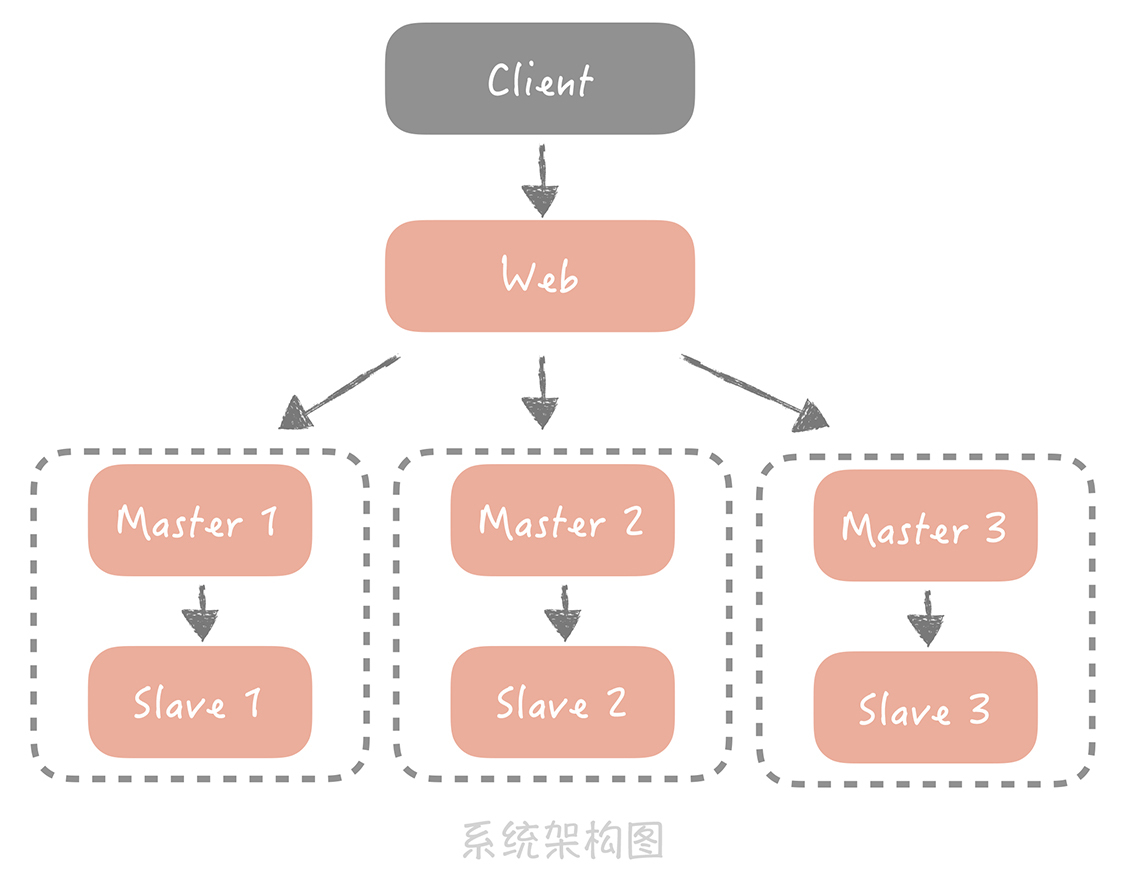
你可以看到,我们通过分库分表和主从读写分离的方式解决了数据库的扩展性问题,但是在 09 讲我也提到过,数据库在分库分表之后,我们在使用数据库时存在的许多限制,比方说查询的时候必须带着分区键;一些聚合类的查询(像是 count())性能较差,需要考虑使用计数器等其它的解决方案,其实分库分表还有一个问题我在
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。
精选留言
 aoe2019-10-10个人觉得“微信序列号生成器”的方法更简单,因为: Snowflake 1. Snowflake算法是基于二进制的,对于像我这样基础不扎实的理解起来还是比较困难。 2. Snowflake集群环境下需要保证时钟同步,对运维能力有一定要求;一旦时钟错乱,又刚好是高并发时,会导致大量异常序号。 3. 如果公司运维能力有限,不适合用Snowflake。 4. 百度开源的UidGenerator(仅支持单机部署)使用Snowflake算法,单机QPS可达600万。项目说明:https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md 。 5. 美团Leaf(分布式ID生成系统),QPS近5万。项目地址:https://tech.meituan.com/2017/04/21/mt-leaf.html 。 微信序列号生成器 文档地址:https://www.infoq.cn/article/wechat-serial-number-generator-architecture 1. 递增但不连续的数字序列解决方案。 2. 设计目标QPS1000万以上。 3. 通过在递增过程中使用“步长”将每秒磁盘写入由1000万级降至1万。 4. 设计原理相对于Snowflake更通俗易懂。 5. 可以使用hash的负载均衡策略组建集群。 6. 缺点:需要自己实现集群中机器增减后更新负载均衡策略的逻辑。 7. Java版最简单Demo():使用spring boot搭建一个web工程,使用Controller调用Service实现数字递增 Service类 import org.springframework.stereotype.Service; import javax.annotation.PostConstruct; import java.util.concurrent.atomic.AtomicLong; @Service public class GeneratorService { private AtomicLong id; @PostConstruct private void init(){ id = new AtomicLong(0); } public long getId(){ return id.incrementAndGet(); } } 单机测试QPS 3万(测试工程、测试脚本在同一机器运行。) 硬件信息:CPU 2.7 GHz Intel Core i7 | 内存 16 GB 2133 MHz LPDDR3 测试工具:JMeter展开共 13 条评论153
aoe2019-10-10个人觉得“微信序列号生成器”的方法更简单,因为: Snowflake 1. Snowflake算法是基于二进制的,对于像我这样基础不扎实的理解起来还是比较困难。 2. Snowflake集群环境下需要保证时钟同步,对运维能力有一定要求;一旦时钟错乱,又刚好是高并发时,会导致大量异常序号。 3. 如果公司运维能力有限,不适合用Snowflake。 4. 百度开源的UidGenerator(仅支持单机部署)使用Snowflake算法,单机QPS可达600万。项目说明:https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md 。 5. 美团Leaf(分布式ID生成系统),QPS近5万。项目地址:https://tech.meituan.com/2017/04/21/mt-leaf.html 。 微信序列号生成器 文档地址:https://www.infoq.cn/article/wechat-serial-number-generator-architecture 1. 递增但不连续的数字序列解决方案。 2. 设计目标QPS1000万以上。 3. 通过在递增过程中使用“步长”将每秒磁盘写入由1000万级降至1万。 4. 设计原理相对于Snowflake更通俗易懂。 5. 可以使用hash的负载均衡策略组建集群。 6. 缺点:需要自己实现集群中机器增减后更新负载均衡策略的逻辑。 7. Java版最简单Demo():使用spring boot搭建一个web工程,使用Controller调用Service实现数字递增 Service类 import org.springframework.stereotype.Service; import javax.annotation.PostConstruct; import java.util.concurrent.atomic.AtomicLong; @Service public class GeneratorService { private AtomicLong id; @PostConstruct private void init(){ id = new AtomicLong(0); } public long getId(){ return id.incrementAndGet(); } } 单机测试QPS 3万(测试工程、测试脚本在同一机器运行。) 硬件信息:CPU 2.7 GHz Intel Core i7 | 内存 16 GB 2133 MHz LPDDR3 测试工具:JMeter展开共 13 条评论153- 程序水果宝2019-10-09老师说如果我们发现系统时钟不准,就可以让发号器暂时拒绝发号,直到时钟准确为止。我们的程序本身就是运行在系统中的,如何来判断系统中的时间是否准确呢?
作者回复: 可以暂时记录上次发好的时间,然后和这次的时间比较
共 5 条评论18  阿杜2019-12-20不仅仅是分库分表后的数据库,很多业务场景都需要分布式发号器,使用snowflake是个很好的选择,不过一般都是用的snowflake雪花算法,实现上会有所差异,比如机器位数和序号位数的选取就不同,1+41位时间戳+10机器区间位+12号递增或随机的数字,类似这种。uuid长度过长,也不递增,使用受限。不过snowflake算法有个问题就是服务器时间回拨的问题,就是时间可能不准,这个时候不能停止发号,我觉得可以采取的方式是:每个服务器存储最新的一个maxNewId,起个线程监控服务器时间是否正确,不正确就从maxNewId递增1获取,同事调准服务器时间,直到服务器时间正确。
阿杜2019-12-20不仅仅是分库分表后的数据库,很多业务场景都需要分布式发号器,使用snowflake是个很好的选择,不过一般都是用的snowflake雪花算法,实现上会有所差异,比如机器位数和序号位数的选取就不同,1+41位时间戳+10机器区间位+12号递增或随机的数字,类似这种。uuid长度过长,也不递增,使用受限。不过snowflake算法有个问题就是服务器时间回拨的问题,就是时间可能不准,这个时候不能停止发号,我觉得可以采取的方式是:每个服务器存储最新的一个maxNewId,起个线程监控服务器时间是否正确,不正确就从maxNewId递增1获取,同事调准服务器时间,直到服务器时间正确。作者回复: 应该可行
17 张珂2020-01-21老师好,想了解部署一套snowflake,性能怎么样?还有一个问题是,发号器虽然可以保证递增发号,但写入数据库时(假设有两个事务要写同一个表),那对于底层B+树也不一定顺序写入,无法利用磁盘顺序写的性能优化吧?
张珂2020-01-21老师好,想了解部署一套snowflake,性能怎么样?还有一个问题是,发号器虽然可以保证递增发号,但写入数据库时(假设有两个事务要写同一个表),那对于底层B+树也不一定顺序写入,无法利用磁盘顺序写的性能优化吧?作者回复: 性能在单实例单核可以达到2亿万次每秒 发号器一般是改的redis
7 小喵喵2019-10-09但是当数据库分库分表后,使用自增字段就无法保证 ID 的全局唯一性了? 1.使用数据库的自增,设置起始值和步长不一样,不是一样可以实现吗? 2.预估每天的数据量,预先生成ID存入缓存(比如Redis)里面,然后去取,这种方法也简单?
小喵喵2019-10-09但是当数据库分库分表后,使用自增字段就无法保证 ID 的全局唯一性了? 1.使用数据库的自增,设置起始值和步长不一样,不是一样可以实现吗? 2.预估每天的数据量,预先生成ID存入缓存(比如Redis)里面,然后去取,这种方法也简单?作者回复: 其实很难预估数据量,某一天有活动咋办?不同的起始值也可,只是增加人工成本,增加了库表咋办?忘了设置咋办?
共 3 条评论7
 Lane2020-01-31老师我有疑问:中间的机器ID,同一毫秒内,3号机器先注册了一个用户,1号机器再注册一个用户。这样的话也不是顺序的了。
Lane2020-01-31老师我有疑问:中间的机器ID,同一毫秒内,3号机器先注册了一个用户,1号机器再注册一个用户。这样的话也不是顺序的了。作者回复: 是的,如果是独立部署的话就可以保证了
共 2 条评论5 长期规划2019-10-22老师,序列号占12位,对应序列号最大值4096,如果一毫秒内请求生成唯一键的次数大于此值怎么办呢?我能想到的办法是当生成的序列号达到4096时,延时1毫秒,再生成。实际中,是这样处理吗?
长期规划2019-10-22老师,序列号占12位,对应序列号最大值4096,如果一毫秒内请求生成唯一键的次数大于此值怎么办呢?我能想到的办法是当生成的序列号达到4096时,延时1毫秒,再生成。实际中,是这样处理吗?作者回复: 会发这么多号吗……
5 王肖武2019-10-12snowflake不能保证单调递增吧?首先,服务器的时钟可能有快有慢;其次,同一时刻,机器号大的机器生成的ID总是大于机器号小的机器,但他的请求可能是先到达了数据库。个人观点:主键还是要用数据库的自增id,另外再加个全局唯一的code作为业务主键。
王肖武2019-10-12snowflake不能保证单调递增吧?首先,服务器的时钟可能有快有慢;其次,同一时刻,机器号大的机器生成的ID总是大于机器号小的机器,但他的请求可能是先到达了数据库。个人观点:主键还是要用数据库的自增id,另外再加个全局唯一的code作为业务主键。作者回复: 首先,服务器的时钟一般是对时的 其次,如果是单独部署的发号器,没有机器ID是可以保证单调递增的
共 5 条评论5 stg6092019-10-09假设通过容器化来部署发号器,且同时会有多个发号器容器运行,那这个 worker Id 如何生成。容器自身的 id 是一串很长的16进制,无法转换为 worker id 吧?难道也需要引入 zookeeper 吗?有没有其他简单可行的方案?
stg6092019-10-09假设通过容器化来部署发号器,且同时会有多个发号器容器运行,那这个 worker Id 如何生成。容器自身的 id 是一串很长的16进制,无法转换为 worker id 吧?难道也需要引入 zookeeper 吗?有没有其他简单可行的方案?作者回复: 容器ID太长了。。。 其实引入zk也还好,对于zk是弱依赖,只是启动的时候拉一下机器ID
5 jimmy2019-10-09snowflake方案中 现在一般公司都有容器虚拟化,所以每个实例都有自己的实例ID,以此作为唯一ID即可,另外保险起见在服务启动的时候可以向其他启动的服务发送check请求,确保ID全局唯一,这样可以不引入zk,让系统更简单些~
jimmy2019-10-09snowflake方案中 现在一般公司都有容器虚拟化,所以每个实例都有自己的实例ID,以此作为唯一ID即可,另外保险起见在服务启动的时候可以向其他启动的服务发送check请求,确保ID全局唯一,这样可以不引入zk,让系统更简单些~作者回复: 容器ID太长了吧,比较占发号器的位数
5 gogo2019-10-10标准的snowflake算法最多支持69年,如果项目真的支撑到69年之后,应该怎么处理呢
gogo2019-10-10标准的snowflake算法最多支持69年,如果项目真的支撑到69年之后,应该怎么处理呢作者回复: 在没到69年的时候增加时间的位数……
共 6 条评论4 Jxin2019-10-091.数据库自增的全局唯一键。可以在设计出按一定步进生成id。比如分库为3台,每台的主键id初始值分别为0、1、2自增步进为3。这样也可以唯一。不过数据库作为整个系统的吊车尾。还是别拿它搞事了。 2.如果业务没有id带有实时字段的要求,那么可以用预生成备用的方式。客户端服务每次按一定步进来拉取id集合,并缓存到客户端本地内存。如此也能有效率的提升。(哪怕有实时业务段,也可以将非业务的其他部分生成好,到客户端用时再拼接)
Jxin2019-10-091.数据库自增的全局唯一键。可以在设计出按一定步进生成id。比如分库为3台,每台的主键id初始值分别为0、1、2自增步进为3。这样也可以唯一。不过数据库作为整个系统的吊车尾。还是别拿它搞事了。 2.如果业务没有id带有实时字段的要求,那么可以用预生成备用的方式。客户端服务每次按一定步进来拉取id集合,并缓存到客户端本地内存。如此也能有效率的提升。(哪怕有实时业务段,也可以将非业务的其他部分生成好,到客户端用时再拼接)作者回复: 👍
共 2 条评论4 ET go home2019-10-09请问下同一时间位,同一机器,在生成序列号时,是要上锁的吧?
ET go home2019-10-09请问下同一时间位,同一机器,在生成序列号时,是要上锁的吧?作者回复: 是的 不过像redis那样单线程处理就好了
4 停三秒2020-03-01想知道那个机器ID如何设置,如果节点重启就再分配一个机器ID的话,那10位的机器ID也支撑不了多少次的重启啊
停三秒2020-03-01想知道那个机器ID如何设置,如果节点重启就再分配一个机器ID的话,那10位的机器ID也支撑不了多少次的重启啊作者回复: ID在同一时间是可以重复的,所以每次重启选择一个可用的,或者一台机器用一个固定的就好了
3 yuan2019-11-13为什么snowflake的第一位一定是0?
yuan2019-11-13为什么snowflake的第一位一定是0?作者回复: 标准实现是的
共 4 条评论3 XD2019-11-03如果单纯为了保证分表之后自增主键唯一,在创建数据表的时候,配合auto_increment_offset和auto_increment_increment不就可以实现吗?(当然我不是说在微服务中不需要取号器)
XD2019-11-03如果单纯为了保证分表之后自增主键唯一,在创建数据表的时候,配合auto_increment_offset和auto_increment_increment不就可以实现吗?(当然我不是说在微服务中不需要取号器)作者回复: 这样要对每一个库的offset都要维护,你要是分了1000张表,就要维护1000个offset
3- 长期规划2019-10-22学习了,之前面试时被问到如何设计ID生成器,没答好。3
 helloworld2019-10-21老师,有相关的示例代码不?我的理解是每一个毫秒将下41时间戳加1,10位的机器不变,12的序列号先随机生成一个数字,然后再在这个基础上生成这一毫秒所需要的全局id的数量。不知道我理解的对不对。打卡09.
helloworld2019-10-21老师,有相关的示例代码不?我的理解是每一个毫秒将下41时间戳加1,10位的机器不变,12的序列号先随机生成一个数字,然后再在这个基础上生成这一毫秒所需要的全局id的数量。不知道我理解的对不对。打卡09.作者回复: 是的,没错
共 2 条评论3 朱海昆2019-10-14老师在生产上是如何处理时钟回拨的?看材料leaf是基于zookeeper 记录处理的,是不是还有其他方式?
朱海昆2019-10-14老师在生产上是如何处理时钟回拨的?看材料leaf是基于zookeeper 记录处理的,是不是还有其他方式?作者回复: 我想是通过记录上一次发号的时间戳,如果这次的时间戳比上次的小,就认为是回拨,拒绝发号
3 daydaynobug2020-04-19但是如果真的出现每毫秒只发一个号,不应该是末尾永远是0吗
daydaynobug2020-04-19但是如果真的出现每毫秒只发一个号,不应该是末尾永远是0吗作者回复: 额 从1发号还是从0发号随你
2