

开篇词|从企业级项目开始,进阶推荐系统

在真实数据中成长
算法 + 工程,平滑学习曲线
课程设计
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

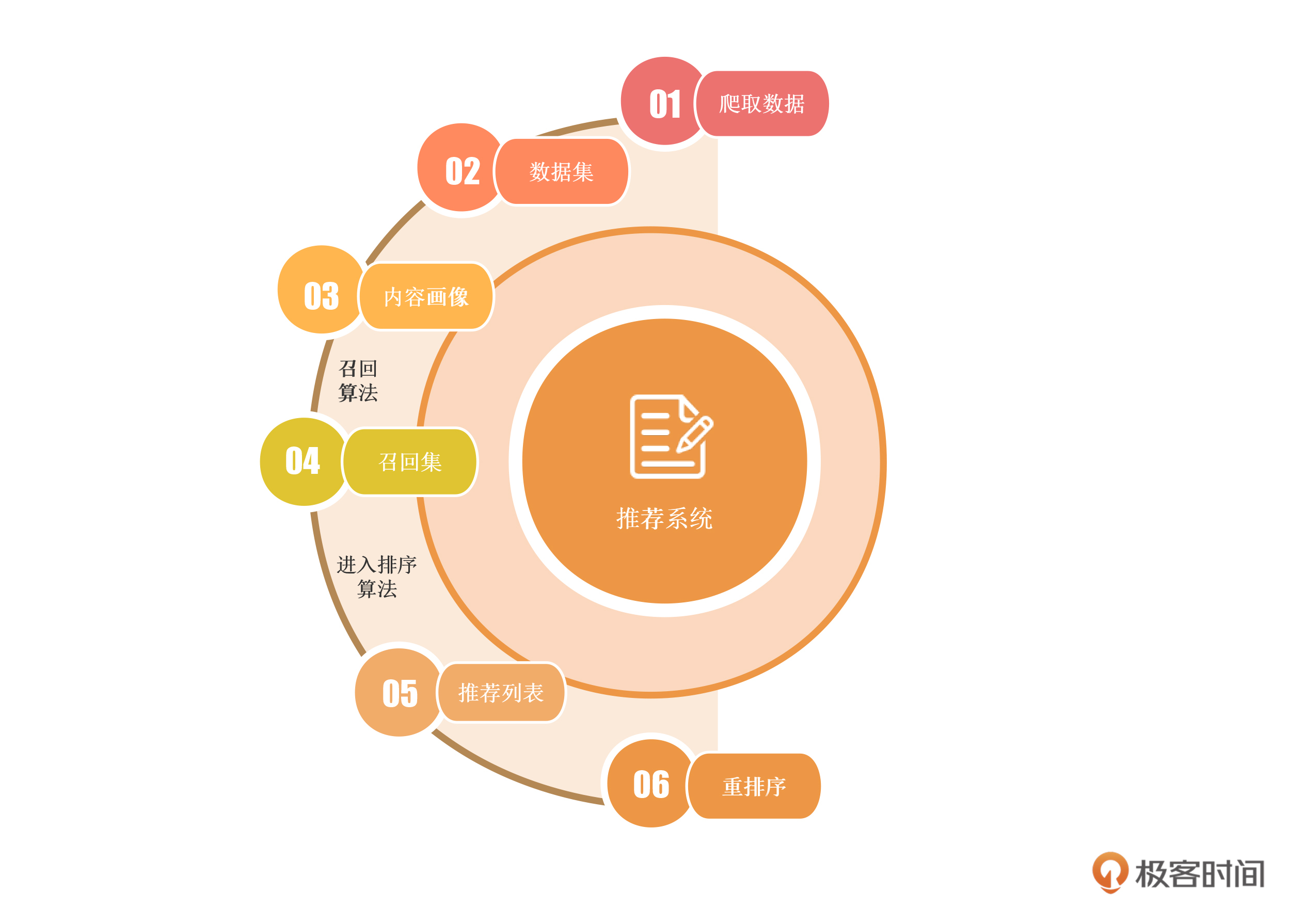
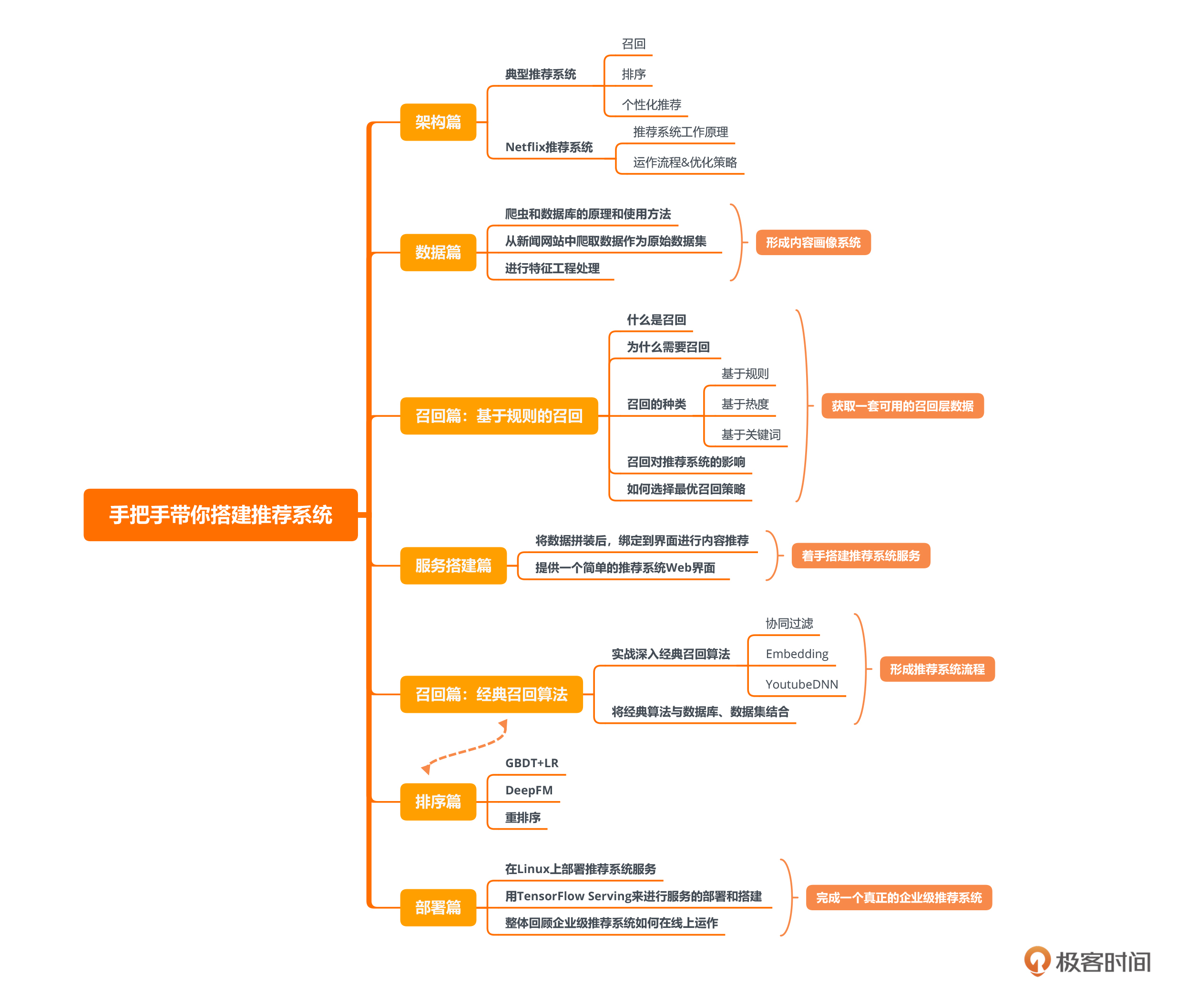
推荐系统在当今企业项目中扮演着不可或缺的角色,黄鸿波的课程设计思路简单明了:“稳中求进,用真实数据搭建企业级系统”。他的课程涵盖了推荐系统的架构、数据处理、召回算法、排序算法以及部署等七个大的章节。通过课程,读者将学习如何从获取真实数据开始,进行数据处理和特征采集,搭建推荐系统,并掌握推荐系统的工程化方案。此外,课程还强调了算法与工程的结合,帮助读者在实际生产实践中更好地应对挑战,构建稳健的推荐系统。整体而言,该课程以实战经验为基础,深入探讨了推荐系统的各个环节,为读者提供了全面的学习和实践指导。
2023-04-1011人觉得很赞给文章提建议
《手把手带你搭建推荐系统》,新⼈⾸单¥59

全部留言(7)
- 最新
- 精选
- 卖代码的梦想家之前推荐系统中用 Elasticsearch 作为召回组件,想问问老师这种做法和自己做的推荐模型区别在哪呢?
作者回复: Elasticsearch主要是基于关键词的相似度来进行推荐,这种推荐方式比较依赖于分词方法,分词的好坏决定了整体的好坏。 自己做推荐算法是利用了用户的特征和内容的特征,这里不仅包含了相似度,还包含了一些隐藏的语义和相关信息,相对来讲会更加准确一些。
2023-04-11归属地:广东4 
 徐石头从课表上知道这门课后期待已久,从上个月盼到这个月,公司产品推荐系统逐渐承载不了需求,请教下老师如果小公司搭建推荐系统对硬件成本是不是要求比较高,没有专门的人力负责这块,人员成本和经济成本有限的前提下有没有比较好的解决方案,我想这也是小公司痛点。
徐石头从课表上知道这门课后期待已久,从上个月盼到这个月,公司产品推荐系统逐渐承载不了需求,请教下老师如果小公司搭建推荐系统对硬件成本是不是要求比较高,没有专门的人力负责这块,人员成本和经济成本有限的前提下有没有比较好的解决方案,我想这也是小公司痛点。作者回复: 同学,你好,其实对于小公司或者小团队来讲,搭建推荐系统的要求并不需要特别高,首先我们要评估好用量。 在我们的这套课程中,或者说真实企业的项目中,一共会分成下面几个部分: 1、推荐系统的模型项目:主要是推荐系统的算法运算、模型运算、推理等,这个可以单独用一个服务器; 2、前端的服务器,这个可以单独一个服务器,这个服务器要求不高,主要是web请求页面; 然后就是几个数据库,redis,MongoDB,以及MySQL(如果需要的话),这几个部分可以和前端共用一个服务器,也可以单独分开,这个就看预算了; 至于开发人员和成本,我觉得2~3个人的小团队,有2个月左右,一般来讲问题不大,如果前期没有很好的数据,可以尝试以冷启动或者我课程中的基于规则的推荐来启动这个项目。
2023-04-10归属地:湖南34 风轻扬想啥来啥,最近正想系统了解一下推荐系统,极客就给安排上了,非常期待老师的更新。 另外,想请教一下老师,我查了一下flask,是python的一个框架,爬虫啥的也都是python,不咋懂python的研发,能学这门课吗?平时主要用java开发
风轻扬想啥来啥,最近正想系统了解一下推荐系统,极客就给安排上了,非常期待老师的更新。 另外,想请教一下老师,我查了一下flask,是python的一个框架,爬虫啥的也都是python,不咋懂python的研发,能学这门课吗?平时主要用java开发作者回复: 我个人觉得是没问题的,我们的课程代码分成3个部分。 1、数据获取:这部分是讲爬虫,我们是用Python来写的,用的是Python中的scrapy框架; 2、推荐模型搭建:这部分是讲各个模型怎么写,以及对数据库的操作; 3、服务端的搭建:这部分是webservice。 在这三部分中,第一部分和第三部分,实际上用任何语言都可以开发,Java中也有很好的爬虫框架,也有比较好的服务端框架,比如springboot等; 那么第二部分模型篇,其实用Java也可以实现,只不过对于机器学习来说,Python的库更多一些。我们只要了解算法本质,其实语言只是一个工具而已,不用过于纠结语言。
2023-04-10归属地:北京23- ShenshunYao老师想问一下这门课的github源码在什么地方,想深入研究一下
作者回复: https://github.com/ipeaking/recommendation https://github.com/ipeaking/scrapy_sina
2023-07-29归属地:加拿大1  -Forward这门课为什么不讲讲大数据平台,我看到很多企业项目都用用到了大数据平台,如hadoop和spark等
-Forward这门课为什么不讲讲大数据平台,我看到很多企业项目都用用到了大数据平台,如hadoop和spark等作者回复: 同学你好,由于课程篇幅有限,以及很多时候大数据平台不是算法工程师关心的重点,所以在这里我们就没有去讲。
2023-05-14归属地:广东 小嘟嘟开篇很赞,非常具有吸引力,求更新
小嘟嘟开篇很赞,非常具有吸引力,求更新作者回复: 感谢支持。
2023-04-11归属地:上海 大豆腐这个课程的内容非常完整,非常适合新手,但是缺少前端和一些关键代码,希望作者能够补齐,有了完整可运行的代码,这门课就够的上精品了。2024-01-04归属地:广西
大豆腐这个课程的内容非常完整,非常适合新手,但是缺少前端和一些关键代码,希望作者能够补齐,有了完整可运行的代码,这门课就够的上精品了。2024-01-04归属地:广西

