

14|字节码(二):解释器是如何解释执行字节码的?

该思维导图由 AI 生成,仅供参考
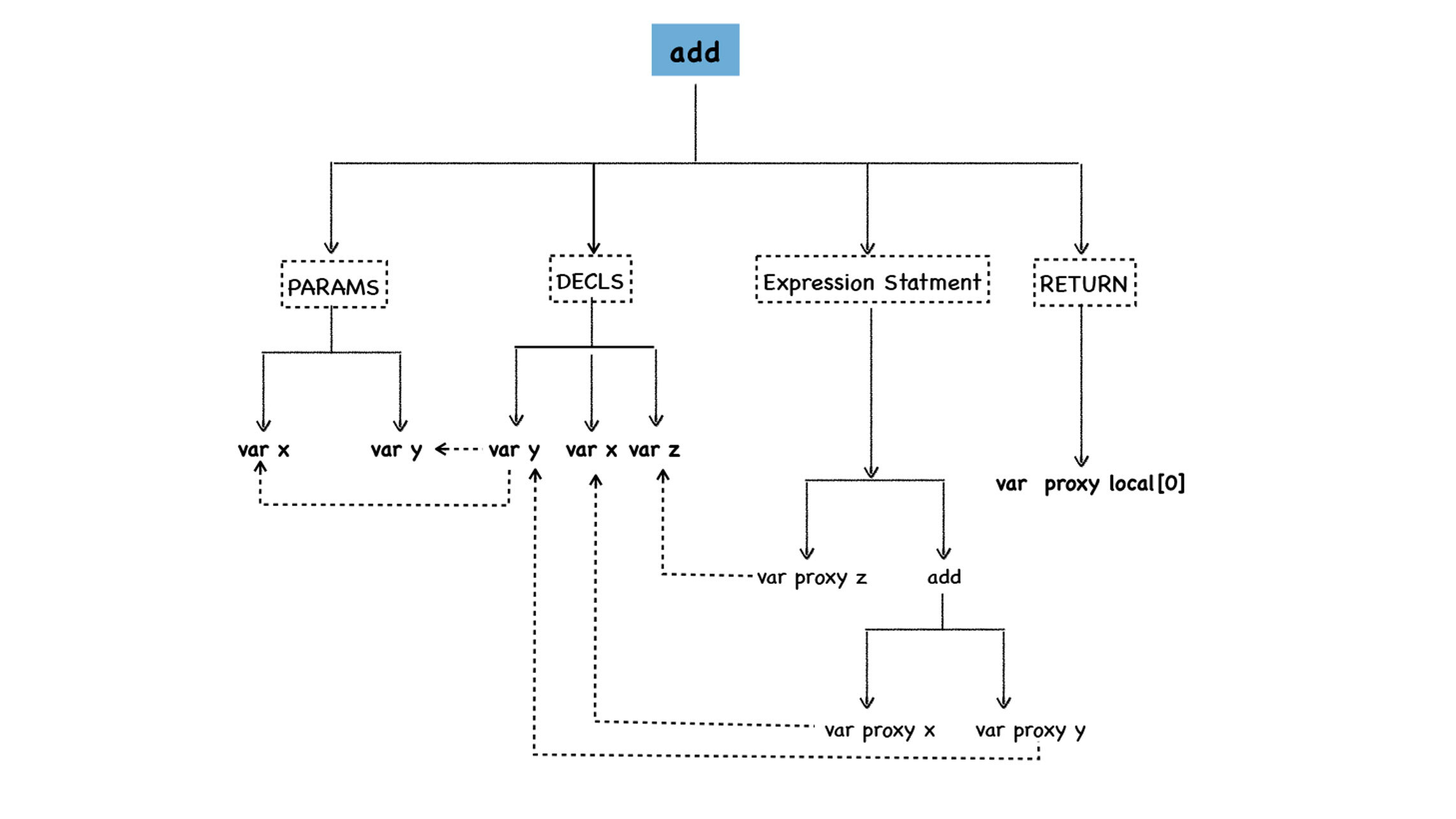
如何生成字节码?
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

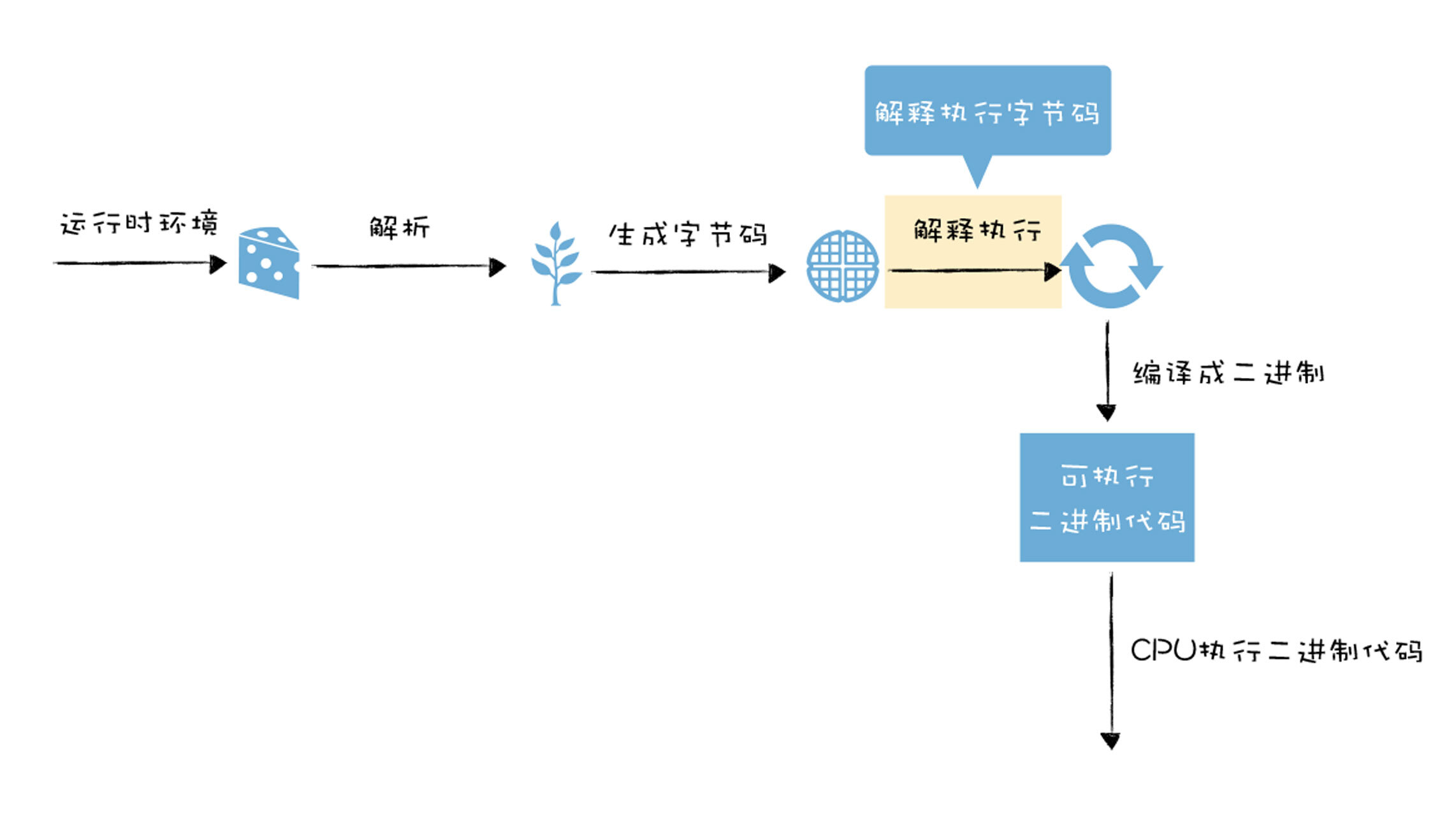
V8引入字节码的原因以及解释器如何解释执行字节码的过程。文章介绍了V8执行JavaScript代码的流程,包括解析代码生成AST和作用域信息,然后转化为字节码,最后由解释器解释执行字节码。通过示例详细解释了生成AST和作用域信息的过程,并展示了生成的字节码。文章提到了生成的字节码的详细信息,并鼓励读者通过理解这些字节码的工作方式来学习其他字节码的工作方式。文章还介绍了V8解释器的架构设计,包括基于寄存器的解释器架构和字节码指令的含义。最后,文章提出了一个思考题,鼓励读者利用d8生成字节码并分析执行流程。整体来说,本文深入浅出地介绍了V8解释器是如何解释执行字节码的过程,对于想要深入了解JavaScript运行时内部工作原理的读者来说,是一篇值得阅读的文章。
《图解 Google V8》,新⼈⾸单¥59

全部留言(20)
- 最新
- 精选
 Shine老师我有一个疑问:'Ldar a1表示将寄存器中的值加载到累加器中' a1的值不是在栈里面吗?不是直接从栈中加载到累加器吗?
Shine老师我有一个疑问:'Ldar a1表示将寄存器中的值加载到累加器中' a1的值不是在栈里面吗?不是直接从栈中加载到累加器吗?作者回复: 这个是参数,存放在栈中,a0代表第一个参数,a1参数代表第二参数,参数an代表第n个参数,你可以把存放参数的地方也看成是存放在栈中的一块寄存器,参数寄存器。
2020-04-1849 木山老师下午好, 我来这里催加餐了(笑),
木山老师下午好, 我来这里催加餐了(笑),作者回复: 晚点啊,最近忙死了
2020-04-175- chris另外请问老师对jvm的字节码熟悉吗,能否推荐一些jvm字节码与v8字节码的比较的资料。目前看到的差异是1)基于栈和基于寄存器,2)v8字节码带了feedback vector。不知还有什么其他的差异。两者之间能否相互表示。openjdk里面自带的nashorn就是一个用java实现的js引擎,它是把js翻译成java字节码吗?
作者回复: 主要因为JavaScript是动态的,而Java是静态的,所以V8需要对动态语言的特性做大量的优化,隐藏类、IC、和IC所使用的Feedback vector都是将动态语言静态化的一种手段。 至于你说的nashorn,我的确不熟悉,所以我也不知道它具体的执行流水线。
2020-04-1724  灰的更高老师,我在这次的课件中看到了,小整型smi。我之前在看书的时候看到了v8的数据表示,书上说smi直接使用前32位进行数值表示,后32位为句柄且最后一位标记位是1,除了smi其他的类型都是存放的指针句柄最后一位是0,但是我不清楚这个其他类型存档指针是什么格式,然后又怎么样和咱们课程里面的内容联系在一起呢,麻烦您能简单介绍一下吗
灰的更高老师,我在这次的课件中看到了,小整型smi。我之前在看书的时候看到了v8的数据表示,书上说smi直接使用前32位进行数值表示,后32位为句柄且最后一位标记位是1,除了smi其他的类型都是存放的指针句柄最后一位是0,但是我不清楚这个其他类型存档指针是什么格式,然后又怎么样和咱们课程里面的内容联系在一起呢,麻烦您能简单介绍一下吗作者回复: smi主要是为了优化内存存储,其实很简单,就是使用更少的内存空间来存储数据,比如现在系统都是64位系统了,那么默认整数数据和指针都是64位的,V8就会考虑将这部分内容压缩位32位,但是压缩到32位后就不知道这快内存是数据还是整数了,于是拿出了一个位来表示整数还是指针,这种技术也称指针压缩,课程中对这块内容没有做介绍
2020-05-13- Geek_bcfa56/** [generated bytecode for function: foo (0x32e4082d26c5 <SharedFunctionInfo foo>)] // Creates a new context with number of |slots| for the function closure CreateFunctionContext [0], [1] // 创建函数上下文环境 // Saves the current context in <context>, and pushes the accumulator as the // new current context. PushContext r0 // 保存旧的上下文到r0中,然后把累加器中的内容作为新的上下文 LdaSmi [20] // 加载20到累加器中 StaCurrentContextSlot [2] // 把累加器中的值存储到上下文中的slot 2中 CreateClosure [1], [0], #2 // 创建闭包,并存储在累加器中 Return // 返回累加器中的值 [generated bytecode for function: inner (0x32e4082d28e9 <SharedFunctionInfo inner>)] Ldar a1 // 把a1加载到累加器中 Add a0, [0] // 把累加器中的值和a0相加,即a0+a1 Star r1 // 把累加器中的值存储到r1 // Load the object in |slot_index| of the current context into the accumulator. // 把当前上下文中的slot 2加载到累加器中,即把20(变量d)加载到累加器中 LdaImmutableCurrentContextSlot [2] Add r1, [1] // 把r1跟累加器中的值相加 Star r0 // 把累加器中的值存储到r0 Return // 返回累加器中的值 */2020-11-265
 champ可口可乐了[generated bytecode for function: add (0x02160824fe59 <SharedFunctionInfo add>)] Parameter count 3 Register count 1 Frame size 8 0x21608250026 @ 0 : 25 02 Ldar a1 0x21608250028 @ 2 : 34 03 00 Add a0, [0] 0x2160825002b @ 5 : 26 fb Star r0 0x2160825002d @ 7 : aa Return Constant pool (size = 0) Handler Table (size = 0) Source Position Table (size = 0) 这是我的Mac平台输出的字节码,好像那2条无用代码被优化掉了。 但是,函数开头没有出现 StackCheck,不知道为什么2020-04-1915
champ可口可乐了[generated bytecode for function: add (0x02160824fe59 <SharedFunctionInfo add>)] Parameter count 3 Register count 1 Frame size 8 0x21608250026 @ 0 : 25 02 Ldar a1 0x21608250028 @ 2 : 34 03 00 Add a0, [0] 0x2160825002b @ 5 : 26 fb Star r0 0x2160825002d @ 7 : aa Return Constant pool (size = 0) Handler Table (size = 0) Source Position Table (size = 0) 这是我的Mac平台输出的字节码,好像那2条无用代码被优化掉了。 但是,函数开头没有出现 StackCheck,不知道为什么2020-04-1915 Imart解释器执行字节码 ‘Ldar a1’时,最底层还是会转换为机器码再由 cpu 来吗?这些字节码指令的执行实际需要再调用cpu执行吗?2020-08-243
Imart解释器执行字节码 ‘Ldar a1’时,最底层还是会转换为机器码再由 cpu 来吗?这些字节码指令的执行实际需要再调用cpu执行吗?2020-08-243 奕在生成 作用域 那个图里面, 参数 x ,y 在堆中进行声明吗? 这个不应该也是在栈中的?2020-04-163
奕在生成 作用域 那个图里面, 参数 x ,y 在堆中进行声明吗? 这个不应该也是在栈中的?2020-04-163 慢慢来的比较快字节码是所有的代码编译出来的,用于缓存的状态,那么这时还有12节说的延迟解析吗?2021-03-1711
慢慢来的比较快字节码是所有的代码编译出来的,用于缓存的状态,那么这时还有12节说的延迟解析吗?2021-03-1711- Imart老师 您好,解释器解释执行字节码,为什么之后还需要编译为二进制码给cpu执行?比如 Ldar a1 这句字节码 最终是不是也编译为对应的机器码,再给cpu 执行?2020-08-2411