

07 | JVM是如何实现反射的?

该思维导图由 AI 生成,仅供参考
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了Java反射机制的实现原理及性能问题。通过分析Method.invoke的源代码,揭示了反射调用的实现机制,包括本地实现、委派实现和动态实现。文章指出动态实现相比本地实现运行效率更高,但生成字节码耗时较长。此外,文章还介绍了反射调用的Inflation机制,即在反射调用次数达到一定阈值时,会切换至动态实现。通过实例代码展示了Inflation机制的触发过程。最后,文章提到可以通过参数关闭Inflation机制。 文章通过实例代码和性能测试,展示了反射调用的性能开销,并提出了优化方案。作者通过多个版本的代码演示,分析了反射调用中的性能瓶颈,包括自动装箱、Object数组生成和内联优化等问题。最终,通过关闭Inflation机制和权限检查,以及优化类型profile的方式,将反射调用的性能开销降低到原本的1.3倍。 总的来说,本文对Java反射机制进行了深入剖析,通过实例代码和性能测试展示了反射调用的性能优化方案。对于想深入了解Java反射机制的读者来说,提供了深入的技术分析和实际案例,帮助读者更好地理解反射机制的实现原理和性能优化。
《深入拆解 Java 虚拟机》,新⼈⾸单¥59

全部留言(81)
- 最新
- 精选
 志远老师您好,提个建议,您讲课过程中经常提到一些概念名词,您讲课总是预设了一个前提,就是假设我们已经知道那个概念,然而并不清楚。比如本文中被不断提到的内联,什么是内联呢?
志远老师您好,提个建议,您讲课过程中经常提到一些概念名词,您讲课总是预设了一个前提,就是假设我们已经知道那个概念,然而并不清楚。比如本文中被不断提到的内联,什么是内联呢?作者回复: 谢谢建议!方法内联指的是编译器在编译一个方法时,将某个方法调用的目标方法也纳入编译范围内,并用其返回值替代原方法调用这么个过程。
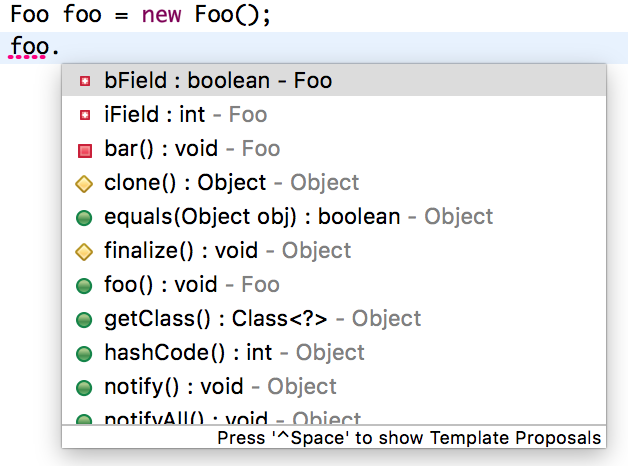
2018-08-067112 xiaguangme开发人员日常接触到的 Java 集成开发环境(IDE)便运用了这一功能:每当我们敲入点号时,IDE 便会根据点号前的内容,动态展示可以访问的字段或者方法。//这个应该是不完全正确的,大部分应该是靠语法树来实现的。
xiaguangme开发人员日常接触到的 Java 集成开发环境(IDE)便运用了这一功能:每当我们敲入点号时,IDE 便会根据点号前的内容,动态展示可以访问的字段或者方法。//这个应该是不完全正确的,大部分应该是靠语法树来实现的。作者回复: 谢谢指出!
2018-08-0661 ext4雨迪您好,我有两个问题: 一是我自己的测试结果和文章中有些出入。在我自己的mac+jdk10环境中,v3版本的代码和v2版本性能是差不多的,多次测试看v3还略好一些。从v2的GC log来看for循环的每一亿次iteration中间都会有GC发生,似乎说明这里的escape analysis并没有做到allocation on stack。您能想到这是什么原因么?另有个小建议就是文章中提到测试结果时,注明一下您的环境。 另一个问题是在您v5版本的代码中,您故意用method1和method2两个对象霸占了2个ProfileType的位子,导致被测的反射操作性能很低。这是因为此处invoke方法的inline是压根儿就没有做呢?还是因为inline是依据target1或者target2来做的,而实际运行时发现类型不一致又触发了deoptimization呢? 望解答,谢谢~
ext4雨迪您好,我有两个问题: 一是我自己的测试结果和文章中有些出入。在我自己的mac+jdk10环境中,v3版本的代码和v2版本性能是差不多的,多次测试看v3还略好一些。从v2的GC log来看for循环的每一亿次iteration中间都会有GC发生,似乎说明这里的escape analysis并没有做到allocation on stack。您能想到这是什么原因么?另有个小建议就是文章中提到测试结果时,注明一下您的环境。 另一个问题是在您v5版本的代码中,您故意用method1和method2两个对象霸占了2个ProfileType的位子,导致被测的反射操作性能很低。这是因为此处invoke方法的inline是压根儿就没有做呢?还是因为inline是依据target1或者target2来做的,而实际运行时发现类型不一致又触发了deoptimization呢? 望解答,谢谢~作者回复: 多谢建议,我也是mac+jdk10。我这边裸跑v2是2.7x(因为每次要新建整数对象所以有GC),加大整数缓存后跑v2是1.8x(无GC)。你是否忘了加大整数缓存? 第二个问题,研究得很深!Method.invoke一直会被内联,但是它里面的MethodAccesor.invoke则不一定。 实际上,在C2编译之前循环代码已经运行过非常多次,也就是说MethodAccesor.invoke已经看到多次调用至target()的动态实现。在profile里会显示为有target1,有target2,但是profile不完整,即还有一大部分的调用者类型没有记录。 这时候C2会选择不inline这个MethodAccesor.invoke调用,直接做虚调用。
2018-08-0626 夜空当某个反射调用的调用次数在 15 之下时,采用本地实现;当达到 15 时,便开始动态生成字节码... ———可以认为第16次反射调用时的耗时是最长的吗?
夜空当某个反射调用的调用次数在 15 之下时,采用本地实现;当达到 15 时,便开始动态生成字节码... ———可以认为第16次反射调用时的耗时是最长的吗?作者回复: 动态生成发生在第15次(从0开始数的话),所以第15次比较耗时。
2018-08-06316- 星文友给大家讲个笑话: 我负责的项目中有大量动态生成的类,这些类实例的调用原本都是通过反射去完成,后来我觉得反射效率低,就为每个动态类的每个方法在动态生成一个代理类,这个代理类就是进行类型强转然后直接调用。后来在压测环境进行测试,发现并无卵用,早点开到这篇文章我就不用做这么多无用功了。特么的JVM已经有这个功能了啊
作者回复: 这说明你和JVM架构师想一块去了 ;)
2018-11-02314  搬砖匠请教一个问题,本地实现可以用java来替代c++的实现方式吗?这样就可以避过C++的额外开销?
搬砖匠请教一个问题,本地实现可以用java来替代c++的实现方式吗?这样就可以避过C++的额外开销?作者回复: 之所以叫本地实现,就是因为它用的C++代码。如果用Java来实现,就不会这么叫啦 :) JVM有用Java来替代的实现方式,也就是文中介绍的动态实现。它是根据反射调用的目标方法来动态生成字节码的。
2018-09-08313 Kisho郑老师,你好, “动态实现无需经过Java到C++再到Java的切换”,这句话没太明白,能在解释下么?
Kisho郑老师,你好, “动态实现无需经过Java到C++再到Java的切换”,这句话没太明白,能在解释下么?作者回复: 在v0版本中我贴了一段stacktrace,你可以看到中间有个native method,这就是C++代码,也就是它先调用至这个C++代码,在C++代码里面再调用至Java代码。
2018-08-0613 Stephen老师,有三个知识点不太明白,分别是:内联、逃逸分析以及inflation机制
Stephen老师,有三个知识点不太明白,分别是:内联、逃逸分析以及inflation机制作者回复: 内联和逃逸分析后面有两篇会专门介绍,反射的inflation机制是当反射被频繁调用时,动态生成一个类来做直接调用的机制,可以加速反射调用
2018-11-0312 once请问老师 是不是本地方法的性能一般都不是很好呢
once请问老师 是不是本地方法的性能一般都不是很好呢作者回复: 需要经过JNI,所以性能很不好。 不过即时编译器可能会将某些指定的本地方法调用给替换掉。这些特定的本地方法叫intrinsics,下周一会讲。
2018-09-0710- Scott有两个问题: 1.v3版本中,确定不逃逸的数组可以优化访问,这个是怎么做的? 2.v5版本中,为啥逃逸分析会失效,明明都封闭在循环里的?
作者回复: 1. 读数组被替换为之前写入数组的值。后面数组就只有写没有读了,因此可以优化掉。 2. 只要没有完全内联,就会将看似不逃逸的对象通过参数传递出去。即时编译器不知道所调用的方法对该对象有没有副作用,所以会将其判定为逃逸。 (如果你问的是不能分配到栈上,那我只能回答Java虚拟机从设计上不支持栈分配。它要不是堆分配,要不是虚拟分配+标量替换)
2018-08-157

