下载APP
登录
关闭
讲堂
算法训练营
Python 进阶训练营
企业服务
极客商城
客户端下载
兑换中心
渠道合作
推荐作者
一文解释清楚Google BBR拥塞控制算法原理
2019-08-09 陶辉 智链达CTO,前阿里云高级技术专家

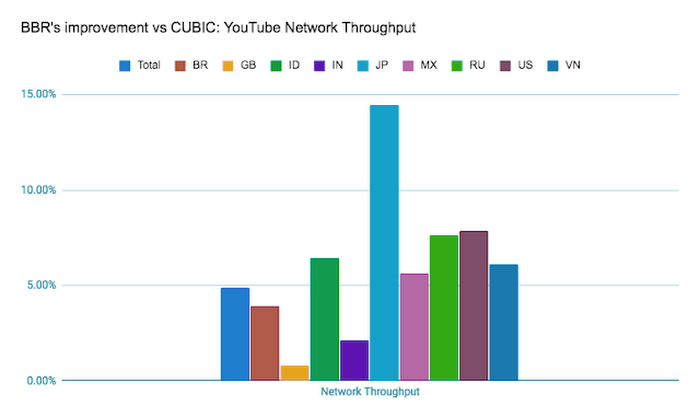
在 2016 年 Google 推出 BBR 算法前,TCP 的拥塞控制算法都是以丢包事件来驱动的,这对含有大缓冲队列的现代路由器来说有很大的性能损耗。而基于测量的 BBR 拥塞控制算法能更有效的使用当下网络环境,Youtube 应用后在吞吐量上有平均 4% 提升(对于日本这样的网络环境有 14% 的提升):
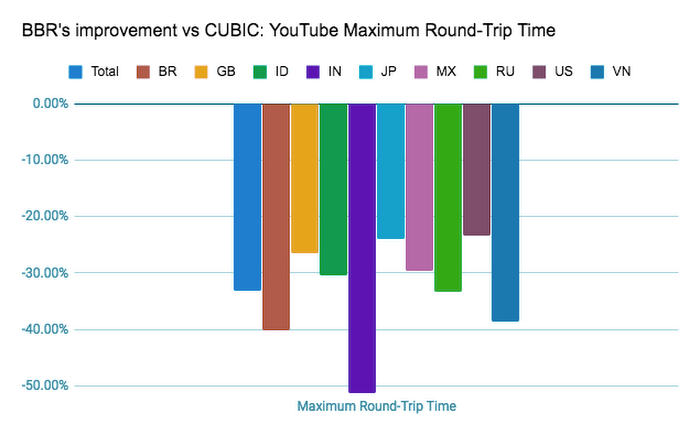
报文的往返时延 RTT 降低了 33%,这样如视频这样的大文件传输更快,用户体验更好:
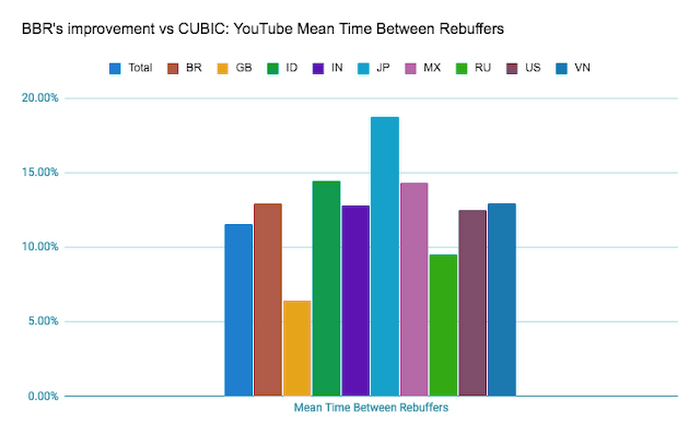
不像 CUBIC 这种基于丢包做拥塞控制,常导致瓶颈路由器大量报文丢失,所以重新缓存的平均间隔时间也有了 11% 提升:
在 Linux4.19 内核中已经将拥塞控制算法从 CUBIC(该算法从 2.6.19 内核就引入 Linux 了)改为 BBR(全称 Bottleneck Bandwidth and Round-trip propagation time),而即将面世的基于 UDP 协议的 HTTP3 也使用 BBR 算法。许多做应用开发的同学可能并不清楚什么是拥塞控制,BBR 算法到底在做什么。我来尝试下用一篇图片比文字还多的文章把这个事说清楚。
TCP 协议是面向字符流的协议,它允许应用层基于 read/write 方法来发送、读取任意长的字符流:
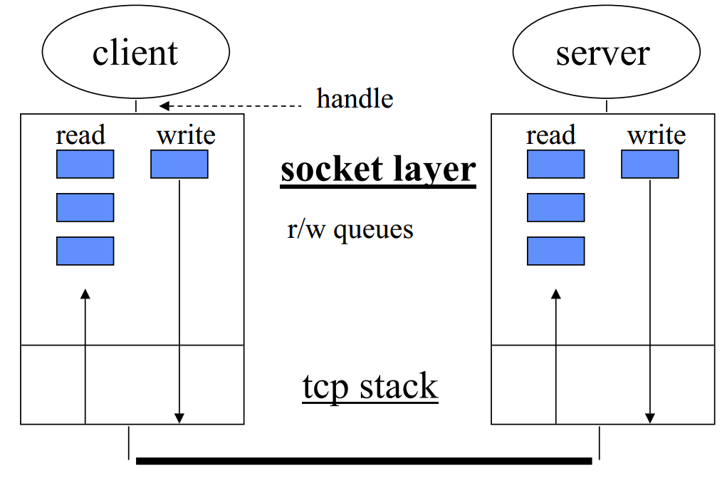
但 TCP 之下的 IP 层是基于块状的 Packet 报文来分片发送的,因此,TCP 协议需要将应用交付给它的字符流拆分成多个 Packet(在 TCP 传输层被称为 Segment)发送,由于网速有变化且接收主机的处理性能有限,TCP 还要决定何时发送这些 Segment。TCP 滑动窗口解决了 Client、Server 这两台主机的问题,但没有去管连接中大量路由器、交换机转发 IP 报文的问题,因此当瓶颈路由器的输入流大于其输出流时,便会发生拥塞:
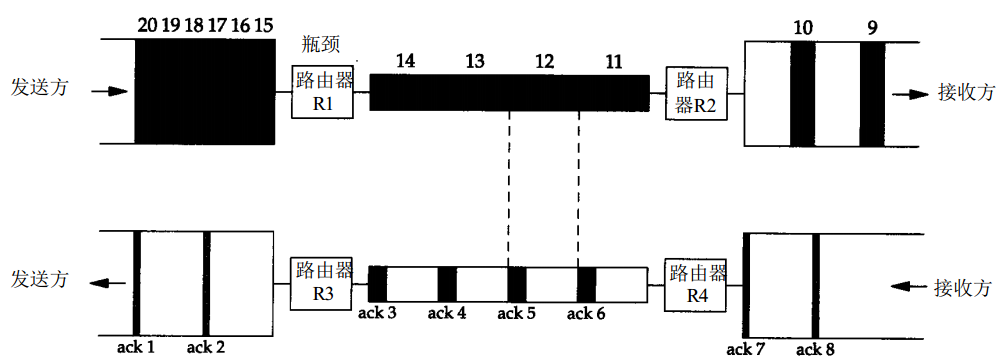
这虽然是 IP 网络层的事,但如果 TCP 基于分层原则不去管,互联网上大量主机的 TCP 程序便会造成网络恶性拥堵。上图中瓶颈路由器已经造成了网速下降,但如果发送方不管不顾,那么瓶颈路由器的缓冲队列填满后便会发生大量丢包,且此时 RTT(报文往返时间)由于存在长队列而极高。
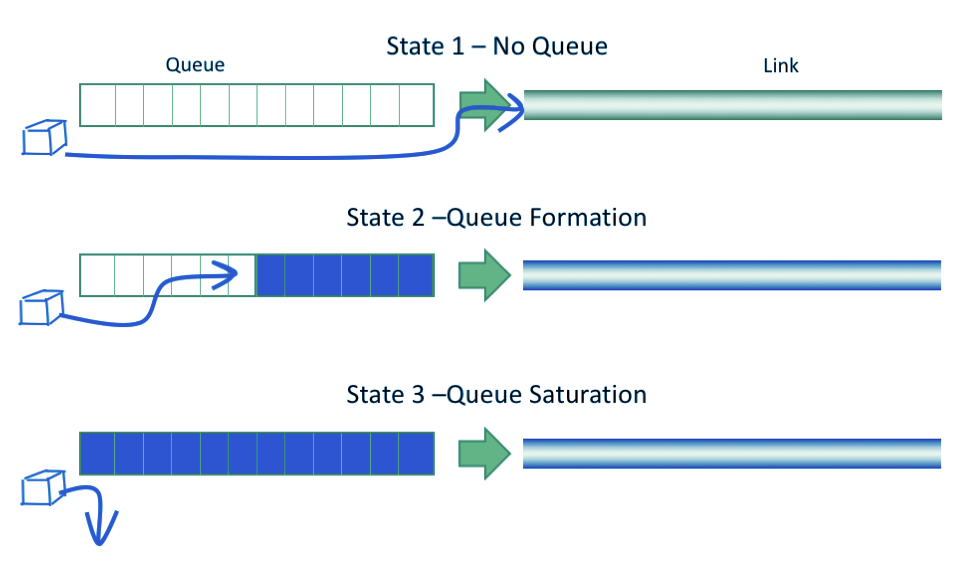
如上图,最好的状态是队列为空,此时 RTT 最低,而 State2 中 RTT 升高,但没有丢包,到 State 3 队列满时开始发生丢包。
TCP 的拥塞控制便用于解决这个问题。在 BBR 出现前,拥塞控制分为四个部分:慢启动、拥塞避免、快速重传、快速恢复:
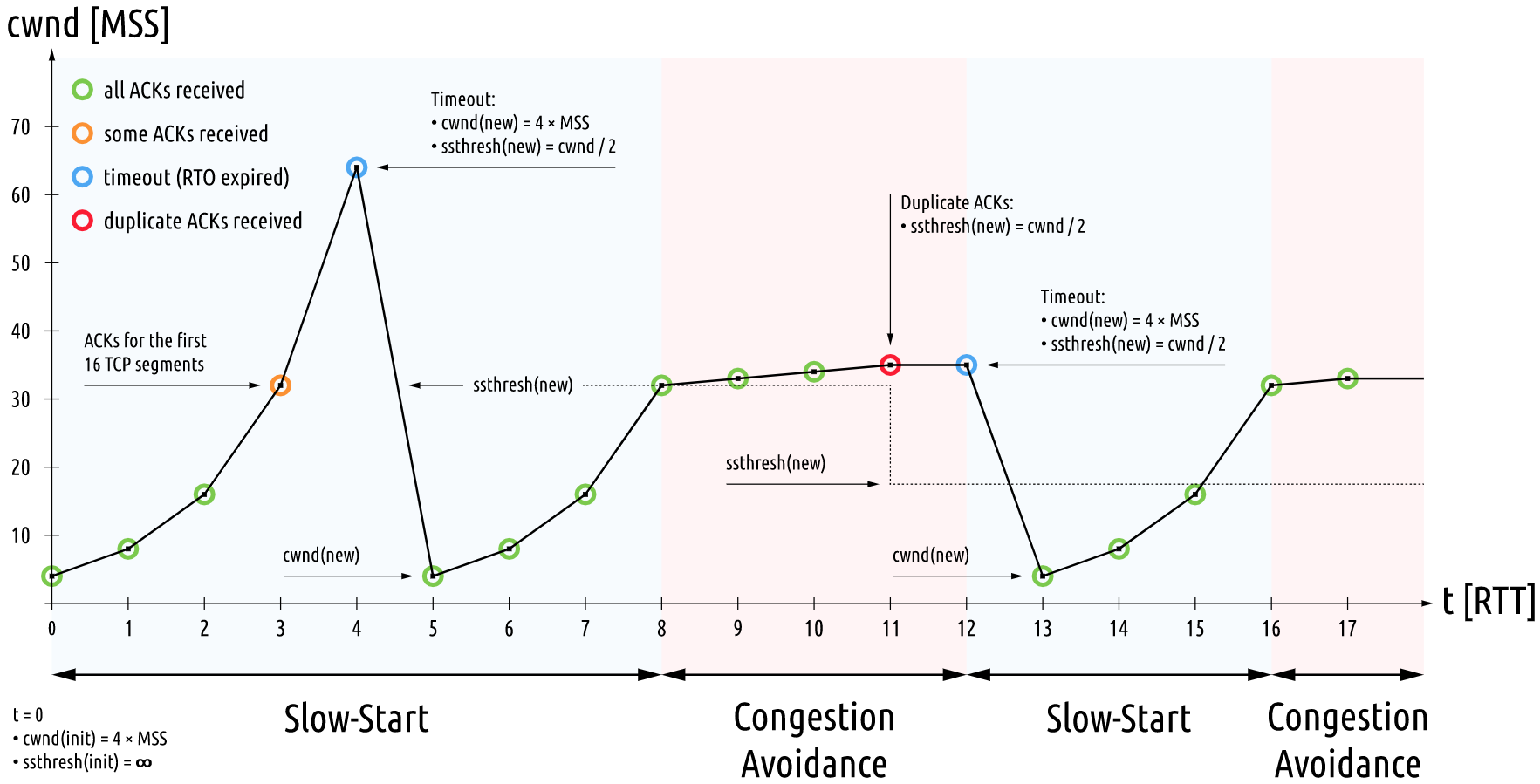
慢启动在 BBR 中仍然保留,它的意义是在不知道连接的瓶颈带宽时,以起始较低的发送速率,以每 RTT 两倍的速度快速增加发送速率,直到到达一个阈值,对应上图中 0-4 秒。到该阈值后,进入线性提高发送速率的阶段,该阶段叫做拥塞避免,直到发生丢包,对应上图中 8-11 秒。丢包后,发速速率大幅下降,针对丢包使用快速重传算法重送发送,同时也使用快速恢复算法把发送速率尽量平滑的升上来。
如果瓶颈路由器的缓存特别大,那么这种以丢包作为探测依据的拥塞算法将会导致严重问题:TCP 链路上长时间 RTT 变大,但吞吐量维持不变。
事实上,我们的传输速度在 3 个阶段被不同的因素限制:
应用程序限制阶段,此时 RTT 不变,随着应用程序开始发送大文件,速率直线上升;
BDP 限制阶段,此时 RTT 开始不断上升,但吞吐量不变,因为此时瓶颈路由器已经达到上限,缓冲队列正在不断增加;
瓶颈路由器缓冲队列限制阶段,此时开始大量丢包。如下所示:
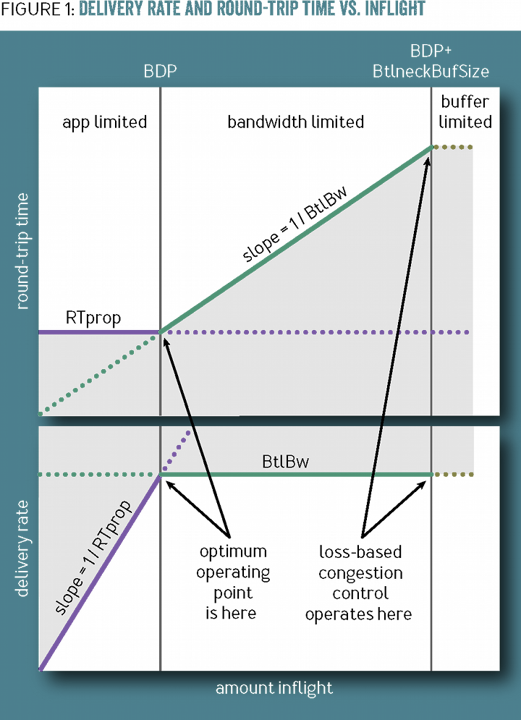
如 CUBIC 这样基于丢包的拥塞控制算法在第 2 条灰色竖线发生作用,这已经太晚了,更好的作用点是 BDP 上限开始发挥作用时,也就是第 1 条灰色竖线。
什么叫做 BDP 呢?它叫做带宽时延积,例如一条链路的带宽是 100Mbps,而 RTT 是 40ms,那么
BDP=100Mbps*0.04s=4Mb=0.5MB
即平均每秒飞行中的报文应当是 0.5MB。因此 Linux 的接收窗口缓存常参考此设置:
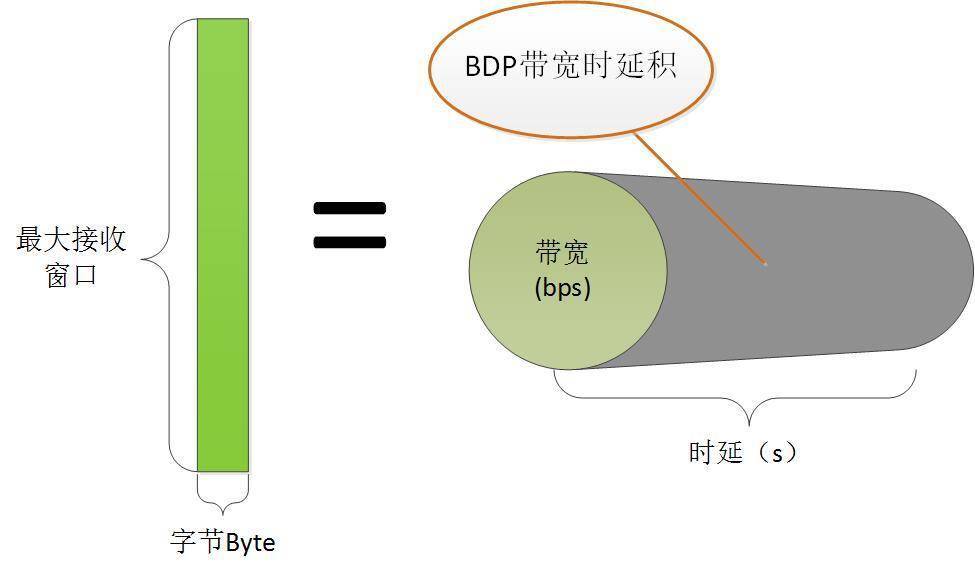
第 1 条灰色竖线,是瓶颈路由器的缓冲队列刚刚开始积压时的节点。随着内存的不断降价,路由器设备的缓冲队列也会越来越大,CUBIC 算法会造成更大的 RTT 时延!
而 BBR 通过检测 RTprop 和 BtlBw 来实现拥塞控制。什么是 RTprop 呢?这是链路的物理时延,因为 RTT 里含有报文在路由器队列里的排队时间、ACK 的延迟确认时间等。什么叫延迟确认呢?
TCP 每个报文必须被确认,确认动作是通过接收端发送 ACK 报文实现的,但由于 TCP 和 IP 头部有 40 个字节,如果不携带数据只为发送 ACK 网络效率过低,所以会让独立的 ACK 报文等一等,看看有没有数据发的时候顺便带给对方,或者等等看多个 ACK 一起发。所以,可以用下列公式表示 RTT 与 RTprop 的差别:

RTT 我们可以测量得出,RTprop 呢,我们只需要找到瓶颈路由器队列为空时多次 RTT 测量的最小值即可:
而 BtlBw 全称是 bottleneck bandwith,即瓶颈带宽,我们可以通过测量已发送但未 ACK 确认的飞行中字节除以飞行时间 deliveryRate 来测量:
早在 1979 年 Leonard Kleinrock 就提出了第 1 条竖线是最好的拥塞控制点,但被 Jeffrey M. Jaffe 证明不可能实现,因为没有办法判断 RTT 变化到底是不是因为链路变化了,从而不同的设备瓶颈导致的,还是瓶颈路由器上的其他 TCP 连接的流量发生了大的变化。但我们有了 RTprop 和 BtlBw 后,当 RTprop 升高时我们便得到了 BtlBw,这便找到第 1 条灰色竖线最好的拥塞控制点,也有了后续发送速率的依据。
基于 BBR 算法,由于瓶颈路由器的队列为空,最直接的影响就是 RTT 大幅下降,可以看到下图中 CUBIC 黄色线条的 RTT 比 BBR 要高很多:
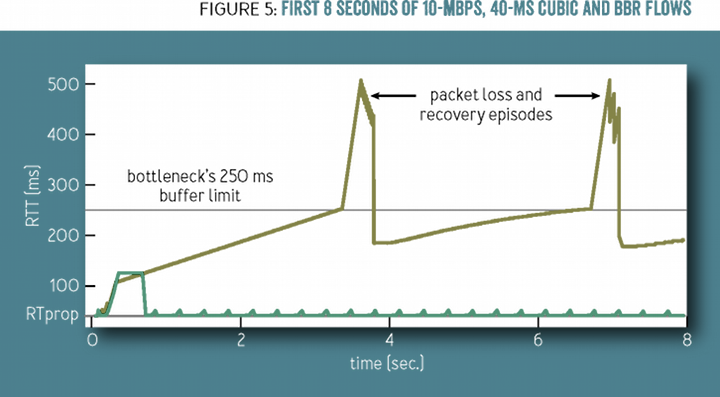
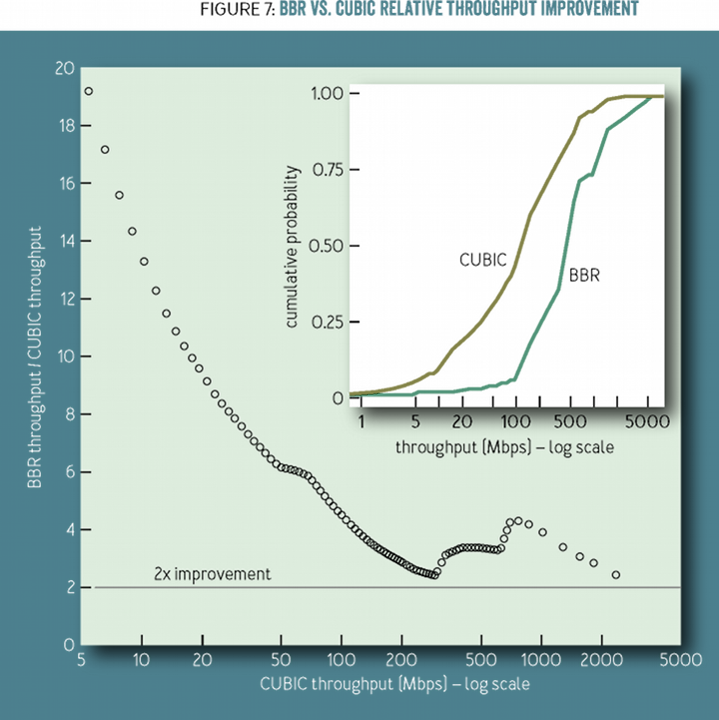
而因为没有丢包,BBR 传输速率也会有大幅提升,下图中插入的图为 CDF 累积概率分布函数,从 CDF 中可以很清晰的看到 CUBIC 下大部分连接的吞吐量都更低:
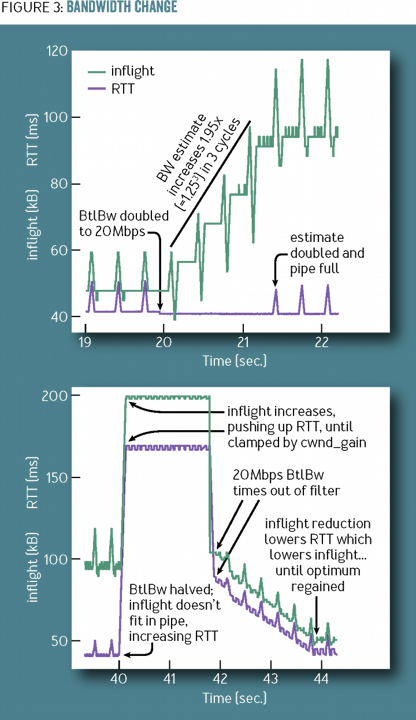
如果链路发生了切换,新的瓶颈带宽升大或者变小怎么办呢?BBR 会尝试周期性的探测新的瓶颈带宽,这个周期值为 1.25、0.75、1、1、1、1,如下所示:
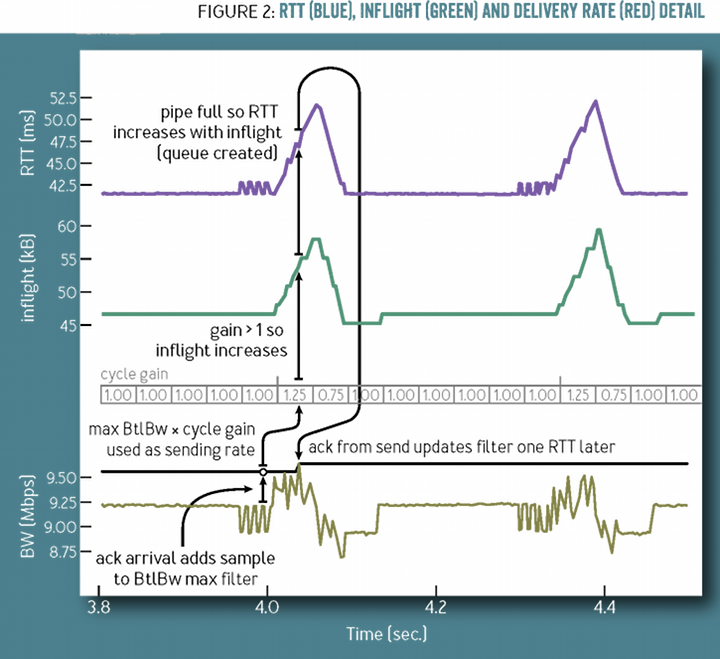
1.25 会使得 BBR 尝试发送更多的飞行中报文,而如果产生了队列积压,0.75 则会释放队列。下图中是先以 10Mbps 的链路传输 TCP,在第 20 秒网络切换到了更快的 40Mbps 链路,由于 1.25 的存在 BBR 很快发现了更大的带宽,而第 40 秒又切换回了 10Mbps 链路,2 秒内由于 RTT 的快速增加 BBR 调低了发送速率,可以看到由于有了 pacing_gain 周期变换 BBR 工作得很好。
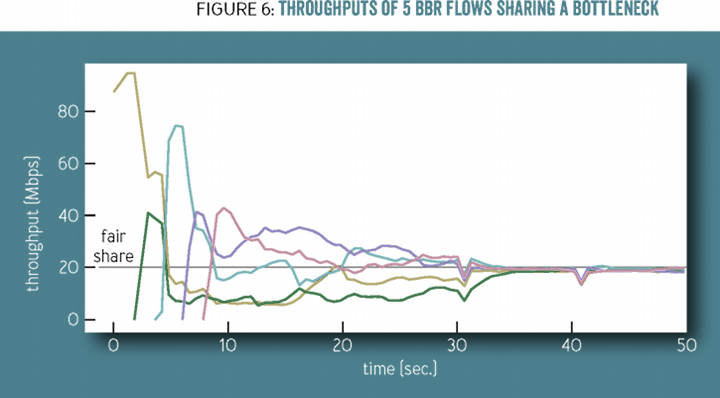
pacing_gain 周期还有个优点,就是可以使多条初始速度不同的 TCP 链路快速的平均分享带宽,如下图所示,后启动的连接由于过高估计 BDP 产生队列积压,早先连接的 BBR 便会在数个周期内快速降低发送速率,最终由于不产生队列积压下 RTT 是一致的,故平衡时 5 条链路均分了带宽:
我们再来看看慢启动阶段,下图网络是 10Mbps、40ms,因此未确认的飞行字节数应为 10Mbps*0.04s=0.05MB。黄色线条是 CUBIC 算法下已发送字节数,而紫色是 ACK 已确认字节数,绿色则是 BBR 算法下的已发送字节数。显然,最初 CUBIC 与 BBR 算法相同,在 0.25 秒时飞行字节数显然远超过了 0.05MB 字节数,大约在 0.1MB 字节数也就是 2 倍 BDP:
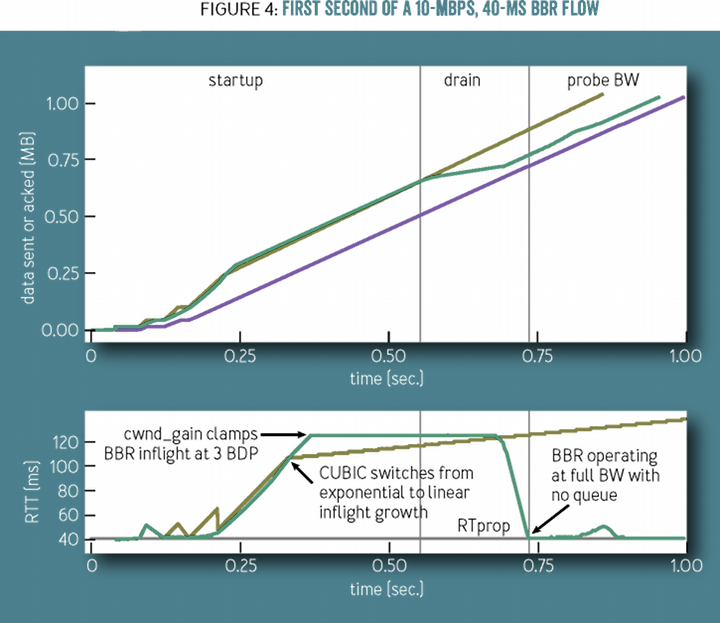
大约在 0.3 秒时,CUBIC 开始线性增加拥塞窗口,而到了 0.5 秒后 BBR 开始降低发送速率,即排空瓶颈路由器的拥塞队列,到 0.75 秒时飞行字节数调整到了 BDP 大小,这是最合适的发送速率。
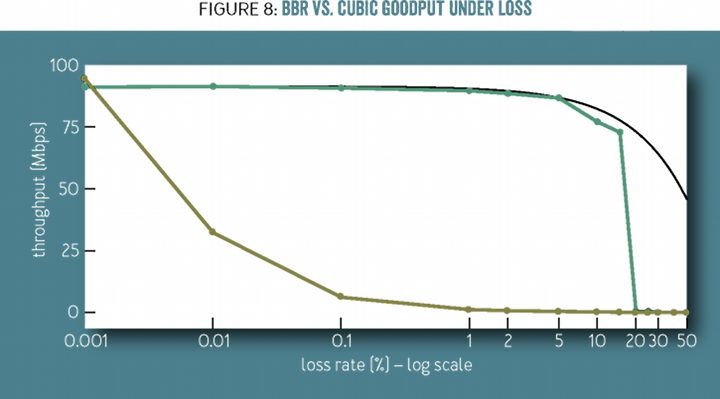
当繁忙的网络出现大幅丢包时,BBR 的表现也远好于 CUBIC 算法。下图中,丢包率从 0.001% 到 50% 时,可以看到绿色的 BBR 远好于黄色的 CUBIC。大约当丢包率到 0.1% 时,CUBIC 由于不停的触发拥塞算法,所以吞吐量极速降到 10Mbps 只有原先的 1/10,而 BBR 直到 5% 丢包率才出现明显的吞吐量下降。
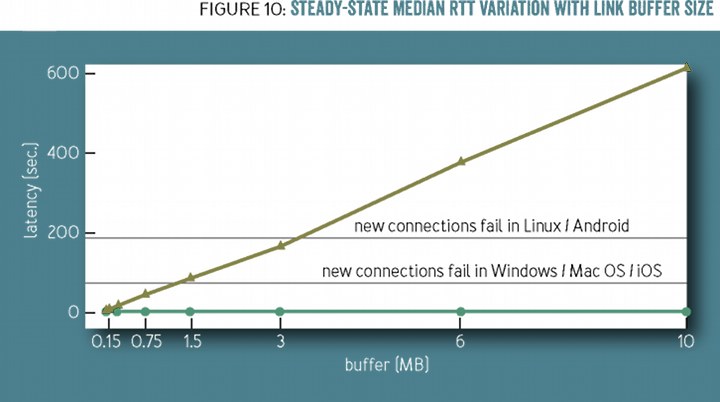
CUBIC 造成瓶颈路由器的缓冲队列越来越满,RTT 时延就会越来越大,而操作系统对三次握手的建立是有最大时间限制的,这导致建 CUBIC 下的网络极端拥塞时,新连接很难建立成功,如下图中 RTT 中位数达到 100 秒时 Windows 便很难建立成功新连接,而 200 秒时 Linux/Android 也无法建立成功。
BBR 算法的伪代码如下,这里包括两个流程,收到 ACK 确认以及发送报文:
function onAck(packet)
rtt = now - packet.sendtime
update_min_filter(RTpropFilter, rtt)
delivered += packet.size
delivered_time = now
deliveryRate = (delivered - packet.delivered) / (delivered_time - packet.delivered_time)
if (deliveryRate > BtlBwFilter.currentMax || ! packet.app_limited)
update_max_filter(BtlBwFilter, deliveryRate)
if (app_limited_until > 0)
app_limited_until = app_limited_until - packet.size
这里的 app_limited_until 是在允许发送时观察是否有发送任务决定的。发送报文时伪码为:
function send(packet)
bdp = BtlBwFilter.currentMax × RTpropFilter.currentMin
if (inflight >= cwnd_gain × bdp)
// wait for ack or retransmission timeout
return
if (now >= nextSendTime)
packet = nextPacketToSend()
if (! packet)
app_limited_until = inflight
return
packet.app_limited = (app_limited_until > 0)
packet.sendtime = now
packet.delivered = delivered
packet.delivered_time = delivered_time
ship(packet)
nextSendTime = now + packet.size / (pacing_gain × BtlBwFilter.currentMax)
timerCallbackAt(send, nextSendTime)
pacing_gain 便是决定链路速率调整的关键周期数组。
BBR 算法对网络世界的拥塞控制有重大意义,尤其未来可以想见路由器的队列一定会越来越大。HTTP3 放弃了 TCP 协议,这意味着它需要在应用层(各框架中间件)中基于 BBR 算法实现拥塞控制,所以,BBR 算法其实离我们很近。理解 BBR,我们便能更好的应对网络拥塞导致的性能问题,也会对未来的拥塞控制算法发展脉络更清晰。

写留言
精选留言(10)
 2019-08-07BBR 这玩意科学上网的时候用过,用来加速杠杠的。 5
2019-08-07BBR 这玩意科学上网的时候用过,用来加速杠杠的。 5 2019-08-07老师讲解的非常好👍,对网络理解更深了一步,期待老师继续出更多的精品课程 4
2019-08-07老师讲解的非常好👍,对网络理解更深了一步,期待老师继续出更多的精品课程 4- 2019-08-07可以配合论文阅读:
BBR: Congestion-Based Congestion Control:https://queue.acm.org/detail.cfm?id=3022184 3  2019-08-07老师,上面这些数据图在哪里看的?可以提供一下链接? 1 1
2019-08-07老师,上面这些数据图在哪里看的?可以提供一下链接? 1 1 2019-08-07结合趣谈网络协议这门课,获益匪浅。大神就是大神。 1
2019-08-07结合趣谈网络协议这门课,获益匪浅。大神就是大神。 1 2019-08-08个人有一个担心——假设网络内既有CUBIC算法的设备,也有BBR算法的设备,BBR这边很克制,但CUBIC的却一直“侵占带宽”。是否最终会依旧会出现网络大量丢包的情况,且带宽基本被CUBIC老流氓们所占据呢?
2019-08-08个人有一个担心——假设网络内既有CUBIC算法的设备,也有BBR算法的设备,BBR这边很克制,但CUBIC的却一直“侵占带宽”。是否最终会依旧会出现网络大量丢包的情况,且带宽基本被CUBIC老流氓们所占据呢? 2019-08-07感觉老师的文章比视频课要讲得更透彻,更易于理解,可能是因为视频更注重实战,期待老师的专栏。
2019-08-07感觉老师的文章比视频课要讲得更透彻,更易于理解,可能是因为视频更注重实战,期待老师的专栏。- 2019-08-07放弃了TCP……
 2019-08-07补充一下参考文档:
2019-08-07补充一下参考文档:
BBR Congestion Based Congestion Control 2019-08-07原文 请Google dog250 bbr
2019-08-07原文 请Google dog250 bbr