下载APP
登录
关闭
讲堂
算法训练营
Python 进阶训练营
企业服务
极客商城
客户端下载
兑换中心
渠道合作
推荐作者
此时此刻,我只想吟诗一首…不,百首!
2018-07-31 费良宏

今天,深度学习俨然成为了全社会的一门显学,而在软件架构的江湖里,Serverless(无服务器架构)则不啻为一名新贵。时髦的概念好则好矣,但如果没有具体的实践则不免流于“纵有屠龙技,何处觅龙迹?”的尴尬。近期热播的《中国诗词大会》第三季或许唤起了许多人对于中国传统诗歌的热爱,对我来说却是此文的成因。
在 Tensorflow 框架上基于 RNN/LSTM 模型针对 24 万首古诗进行训练并生成模型。将 Python3 推理代码与模型打包部署在 AWS Lambda 之上,并利用 Amazon API Gateway 封装为 RESTfull API,调用此 API 可获得计算机生成的七言或五言古诗。项目代码托管在:
背景
现任 Tesla 人工智能总监的“深度学习网红” Andrej Karpathy 在 2015 年发表了一篇名为 《The Unreasonable Effectiveness of Recurrent Neural Networks》 的博文。文章的内容很有趣,主要的思想借用他自己的一句话就是:
“允许你根据多层 LSTM 来训练字符级语言模型。你给它一大块文本,它会学习并且以一次一个字符的方式生成文本”。
为了验证他的想法,他在 Github 上发布了他的基于 Torch 框架的代码。详情点击: https://github.com/karpathy/char-rnn

Andrej 利用他的代码尝试了模仿莎士比亚的著名悲剧《特洛伊罗斯与克瑞西达》,写出了这样一段让人真假难辨的对白 :

更夸张的是,他居然尝试生成了一段看起来有模有样的 Linux Kernel 的 C 语言代码。这让傲娇的程序员们情何以堪啊!

从那以后,基于 Char-RNN 模型的深度学习应用就如同雨后春笋般多了起来。针对中文的应用场景就出现了写小说、写歌词甚至写古诗的各种项目。记得一年多以前,我也尝试写一个版本,虽然格式上看起来像是一首古诗,但只能说是一些字的堆砌,毫无意境以及韵律可言。而在这一年中,深度学习在各个领域的发展只能用狂飙突进来形容。我也就有了再次尝试一下的想法。不过我心目中理想的目标不仅仅是生成古诗这么简单,而是希望将这个应用可以和 Serverless 以及 RESTful 这些技术结合在一起。
RNN、LSTM 算法概念及原理
科普:什么是循环神经网络(RNN)?
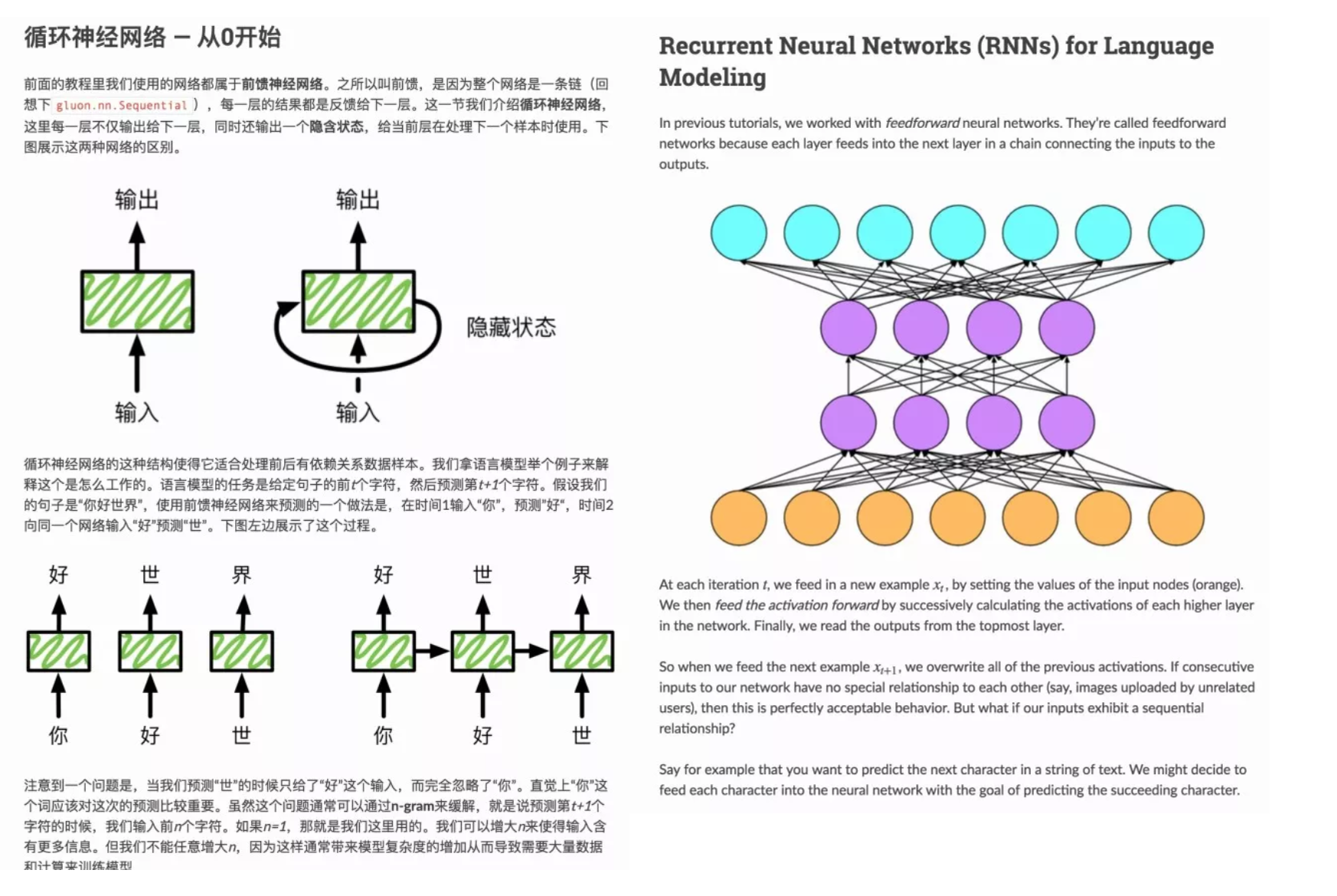
就是一种简单的多层神经网络的分类器。传统的神经网络的输入、输出是固定的。但在一些场景下,样本间存在顺序关系,每个样本和它之前的样本存在关联。例如,在一首诗中,一个词和它前面的词是有关联的。而循环神经网络(RNN)就适用于这种需求。当 RNN 遍历输入的序列时,RNN 每一层不仅输出给下一层,同时还输出了一个隐含状态,给当前层在处理下一个样本时使用。
科普:什么是长短时记忆网络(LSTM)?
RNN 非常适合序列分类问题,原因是它能够保留先前输入的重要数据并使用该信息修改当前输出。长短时记忆网络(LSTM)是一种 RNN 结构,它解决了长序列训练和保留记忆的问题。 LSTM 通过引入更多的控制访问单元状态的门来解决梯度求解问题。
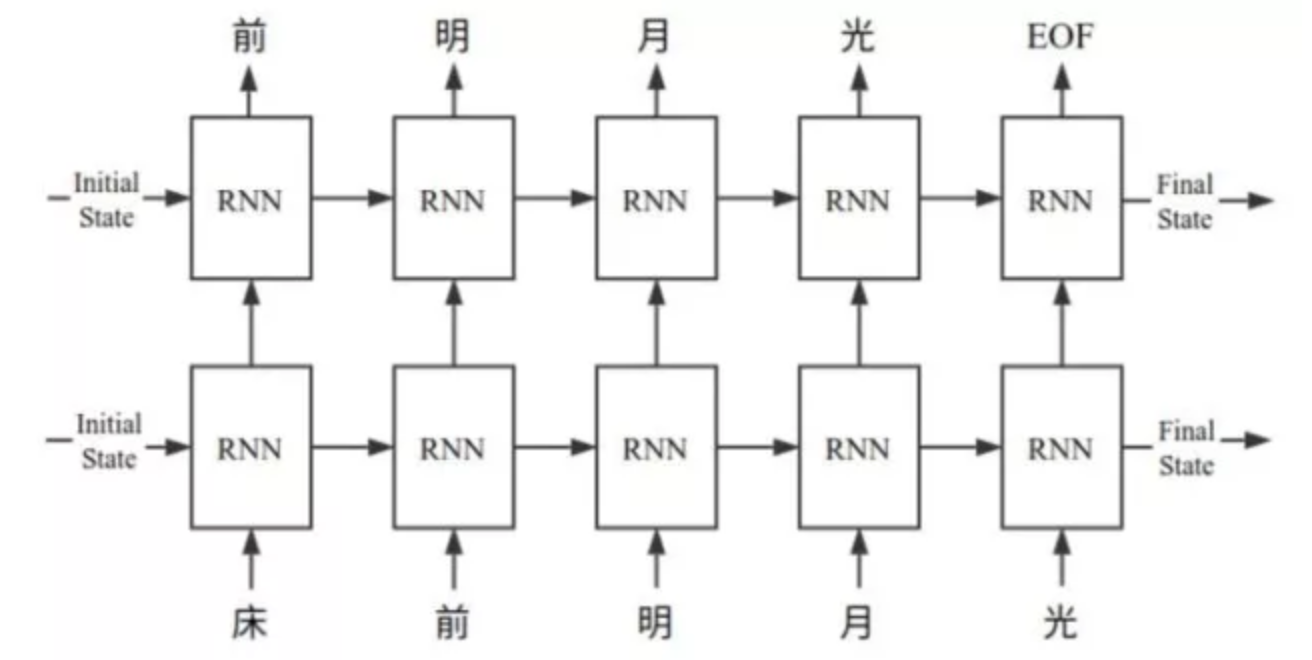
RNN(1980 年代)以及 LSTM(1997 年)至今已经发展的非常成熟了,相关的算法原理已经有太多的文章做过介绍,我就不想在这里献丑了。如果你还希望对此了解更多,我推荐这样两个学习资源:
1
李沐以及 Aston 所作的一个关于循环神经网络的在线课程,其中就有关于如何通过学习周杰伦的歌词而自动生成同样风格新的歌词的例子。
2
Zachary C. Lipton、李沐以及 Alex Smola 等所编写的那本《Deep Learning - The Straight Dope》。其中的第 5 章就是非常详尽的对于 RNN、LSTM 的理论以及实践的讲解:http://gluon.mxnet.io/chapter05_recurrent-neural-networks/simple-rnn.html
数据
对于今天的深度学习应用来说,高质量的训练数据是非常、非常、非常(三遍)重要。在这一次的实践中,我选择了《全唐诗》、《全宋诗》以及《清诗》的合集。在去除了不符合五言、七言的格式之后,共计 246,338 首诗。为了消除标点符号等对于内容生成的影响,需要将其替换为空格。此外,对于非中文字符则需要清理掉。对于中文字符的处理因为 Unicode 良好的编码规则以及 Python3 对于 Unicode 的支持而变得简单。在 Unicode 编码中 4E00~9FFFh 区间是中文表意文字区。于是我们可以简单的通过 Python 的正则表达式来完成数据的清理:
# 替换标点符号
re.sub(r’[,|。|!|?|、|,|.|?|!]+’, “”, str)
# 替换非中文字符
re.sub(r’[^\s+\u4e00-\u9fa5]’, “”, str)
# 选择五言、七言格式的诗句
re.search(r’(\w{5,7}\s)+’, str)
清理完成的数据是这个样子的:

训练模型
编写训练的代码毫无疑义应该就是 Python。不过在我参考过的许多项目中,注意到许多开发者还在执着于 Python2 ,这让我非常困惑。Python 核心团队已经确认了将在 2020 年停止 Python2 ,既然如此我们何必还将精力花在即将被淘汰的事物上?
至于深度学习的框架,我的选择是 Tensorflow。这是因为我看到了 Google 推出了 Tensorflow 下全新的 seq2seq 实现,而原来的那个版本已经被改为 leagcy_seq2seq,这一点请一定注意。新旧两个 seq2seq 的实现最大的不同,简单来说 leagey_seq2seq 是静态的 RNN,而新版的则是动态的 RNN。所谓的静态 RNN 是必须提前将计算图展开,在执行的时候图是固定的,并且最大长度有限制。而动态 RNN 却可以在执行的时候将计算图循环地复用,效率会有显著的提高。其实对老版本的那个 seq2seq ,开发者的吐槽声一直不断。而有动手能力的人早就不屑于吐糟,Denny Britz 以及 Matvey Ezhov 分别给出了他们自己改进的代码。最终,Denny Britz 的那个版本成为了 Tensorflow 的官方版本。
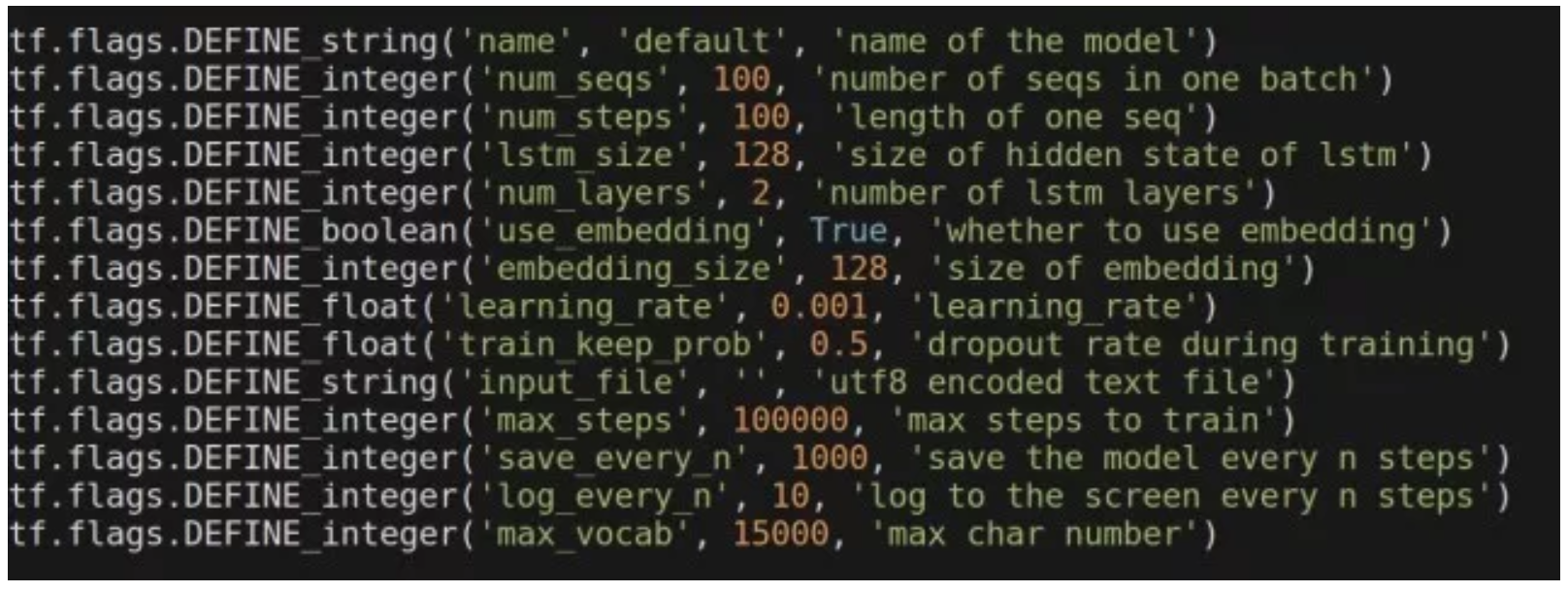
训练古诗的模型定义是比较简单的 :
训练使用到的程序共有三个,具体的细节可以参考 Github 上的完整代码:
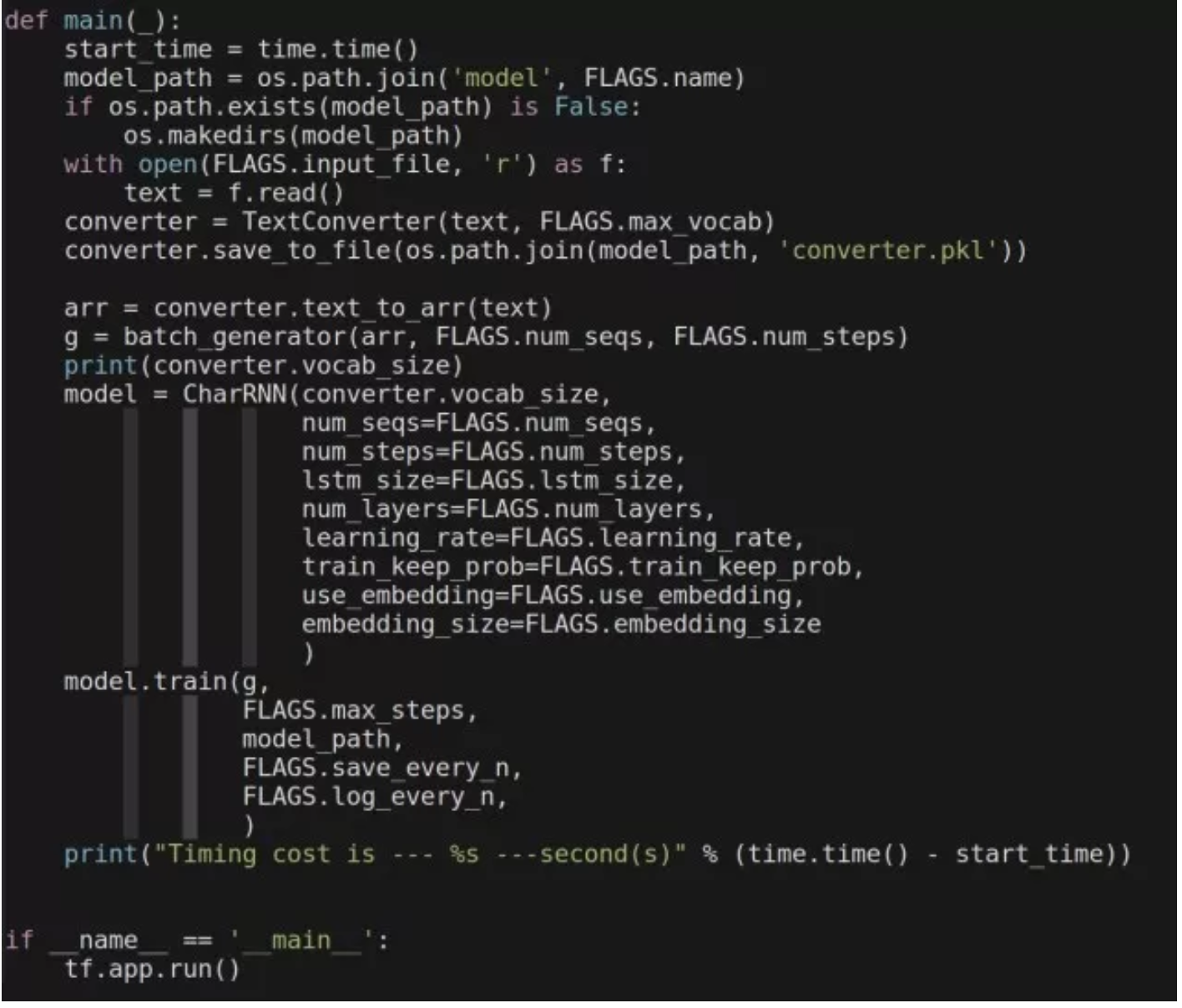
在我的一台 Intel i7-6850K CPU 以及 NVidia 1080Ti 显卡的机器上训练的时间约为 279 秒。而同样的代码运行在 P3.16xlarge 的实例上(Intel Xeon E5-2686v4 64 vCPU、8 块 V100 GPU )以及 AWS Deep Learning AMI 之上,在未做优化的情况下训练时间却达到了 600 秒之多。可见无论硬件条件多么强大,不做系统优化,就只能是白白浪费掉所拥有的宝贵的计算资源。
部署到 AWS Lambda
熟悉云计算或者 AWS 服务的人应该不会对 Lambda 这个产品感到陌生。这个服务自出生起就带着夺目的光环,业内也是好评如潮,成为了所谓的无服务器架构(Serverless)的典范。但是有过深度实践的开发者也一定会对那个“AWS Lambda 限制”以及“Cold Starts”深恶痛绝。在这个项目中,我遇到的主要挑战就是,Lambda 函数部署程序包 50 MB 限制以及运行性能的问题。
我们先来看看在 Lambda 环境中生成古诗所需要的资源:
生成古诗的模型, 压缩后的尺寸是 32MB
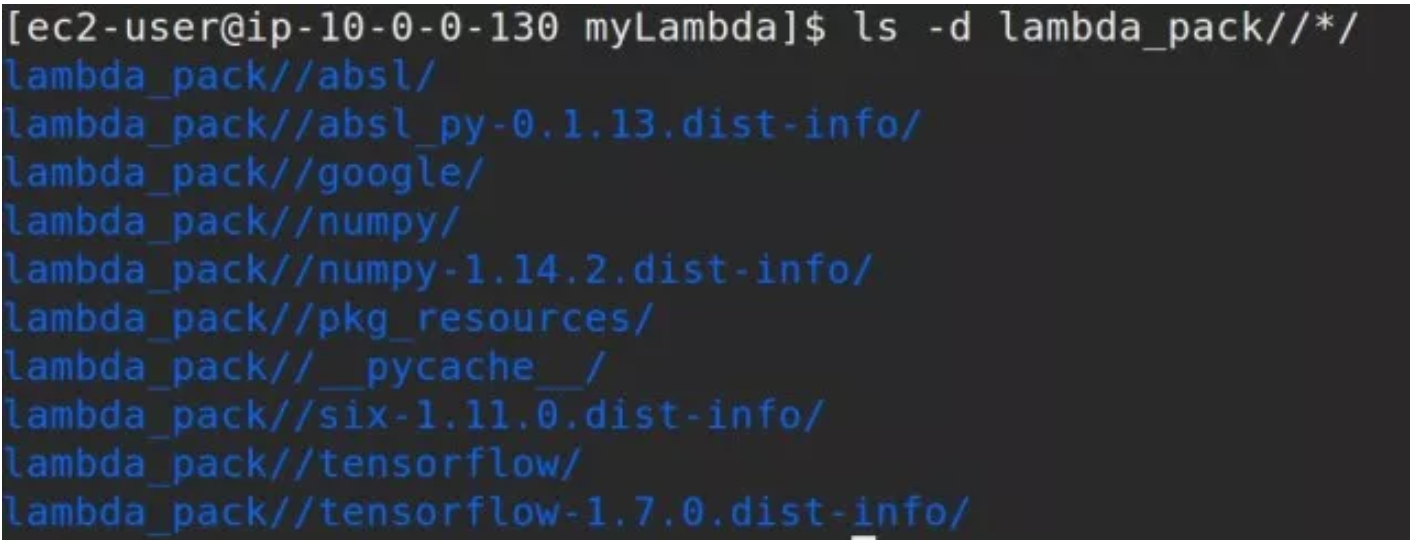
Tensorflow、numpy 等依赖的框架,压缩以后的大小为 48MB。下图就是精简后 Python Package 的情况
打包 Lambda 函数的脚本在这里:
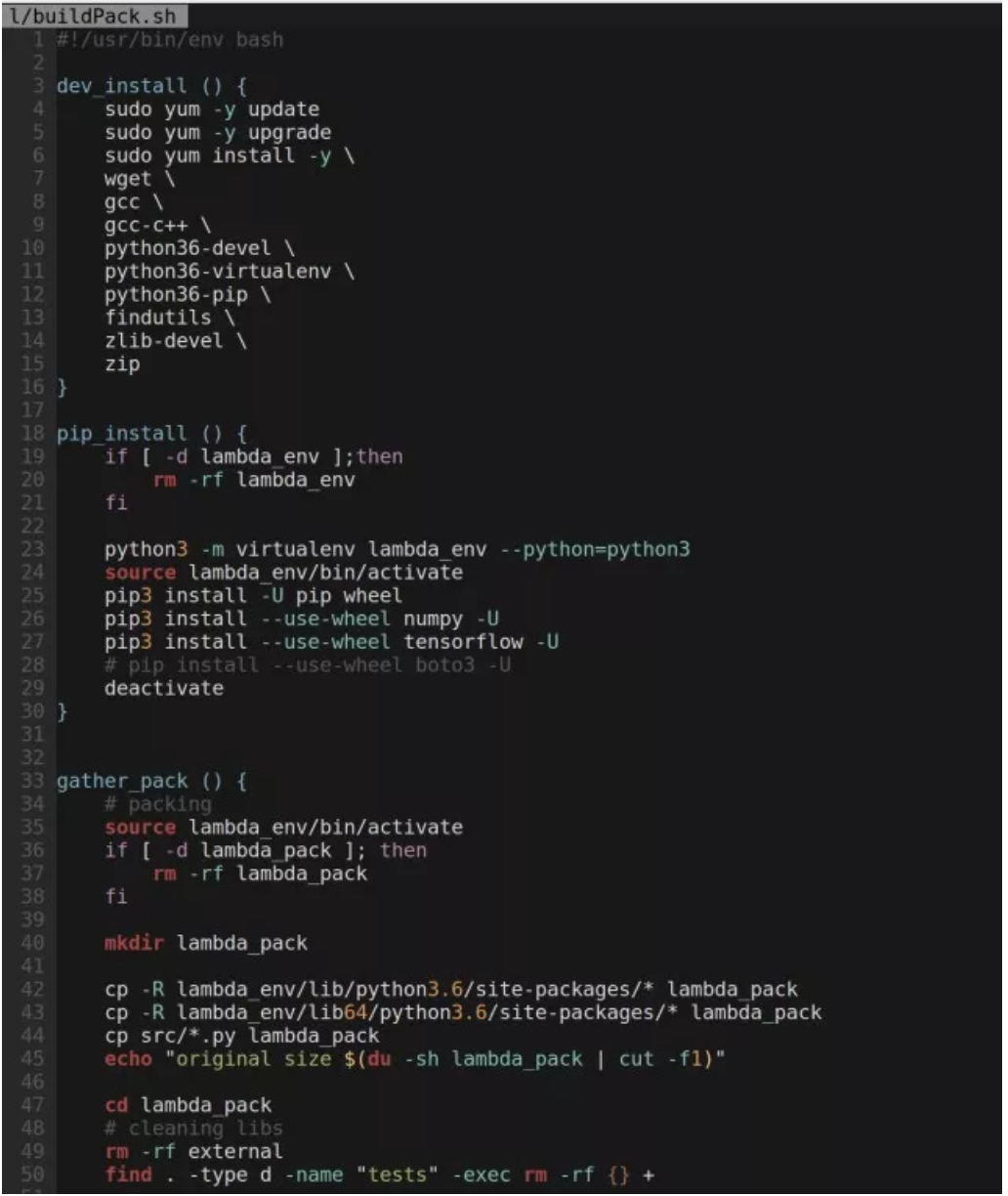
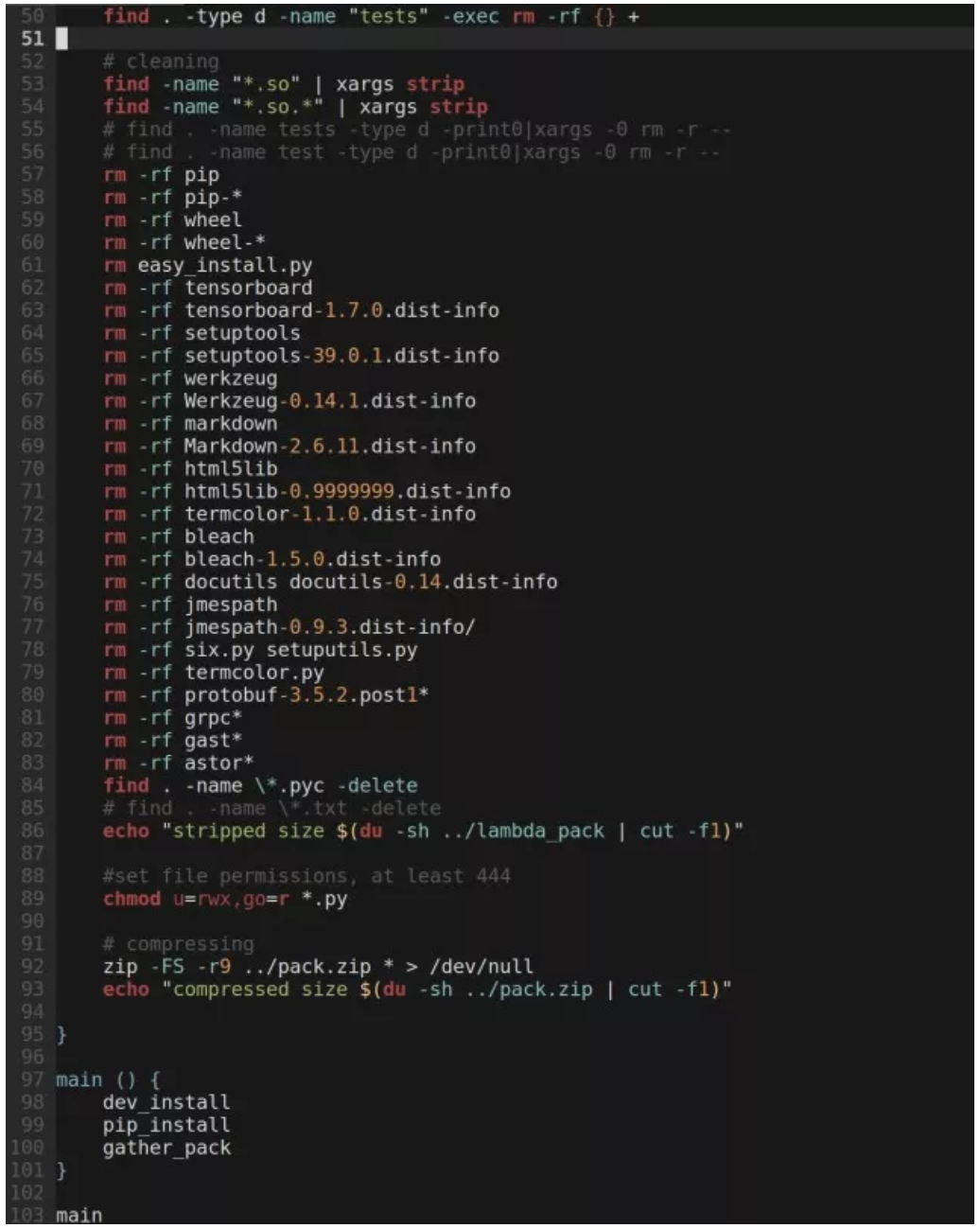
做一些简单的运算就知道,这几项合计的大小是 81MB,已经远远超出了 Lambda 的限制。那么,我们的解决方法是什么?
存储:S3 和/tmp
我们选择了将打包好的模型文件(chinese_poetry_model.tgz)保存到 Amazon S3 的存储桶中。这样做的好处是显而易见的,打包部署的程序可以限制在 50MB 之内。当 Lambda 函数被调用的时候模型文件将会被下载至 Lambda 运行的服务器上的/tmp 空间下加以使用。需要注意的一点是 Lambda 对于临时磁盘容量(“/tmp”空间)也存在一个 512MB 的限制。这就要求我们解压缩以后的模型文件的尺寸不能超过这个数字。当 Lambda 函数存在多个并发请求的时候,模型文件只需要下载一次就可以。所以代码中需要对此做出判断。
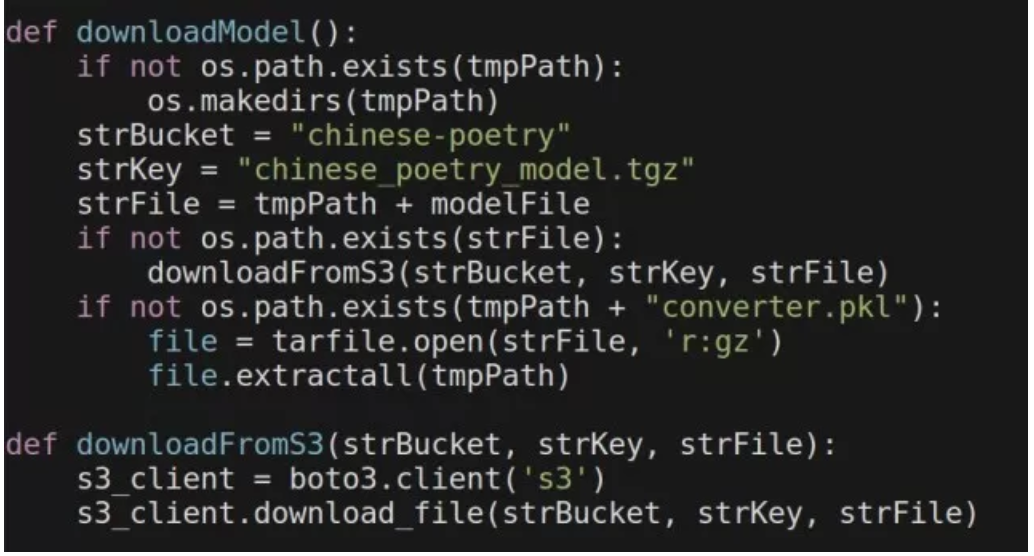
此外,一个附加的好处是,这种模式实现了应用与模型的解耦。未来模型或者应用程序得以独立进行升级或变更。
预热:Cloudwatch 计划事件
有人可能对上述问题仍有一些疑问:如果我们并行启动 200 个调用,如何避免过多的下载模型,因为在那时模型文件还不存在? /tmp 中的文件会持续多久?
2014 年,当 Lambda 仍处于 Preview 的时候,极富个性的 Lambda 产品负责人 Tim Wagner 在一篇博客中写了这样一段话:

他的意思是,如果沙箱被重用,那么您上次写入 / tmp 的文件仍将保留在那里。
在 Lambda 的官方文档中,也有这样的介绍 :

在一个真实的生产环境中,为了确保模型文件始终处于有效的状态,我们可以建立一个 Schedule event 来保持运行环境的 “Warm”。 设定每隔几分钟就调用一次函数,而不进行任何请求的处理,可以确保已经准备好模型文件。
预热:Lambda 部署
对于 Lambda 函数的部署,许多人可能习惯通过浏览器在 AWS console 上完成部署操作。但这却是我非常反感的一点。我不喜欢这种方式是因为我认为在云计算的环境里,所有的操作都应该是程序化的,都应当通过程序、脚本或者模版一类的工具以自动化的方式来完成。试想在一个大型的、复杂的生产环境中,各种运维、管理都依赖人手动完成。这其中的风险、错误率、不确定性以及过极的工作效率想起来都会让人不寒而栗吧。尽管这是个很小的项目,我也希望通过自动化而不是手工的方法来完成部署。多说无益,上部署脚本:
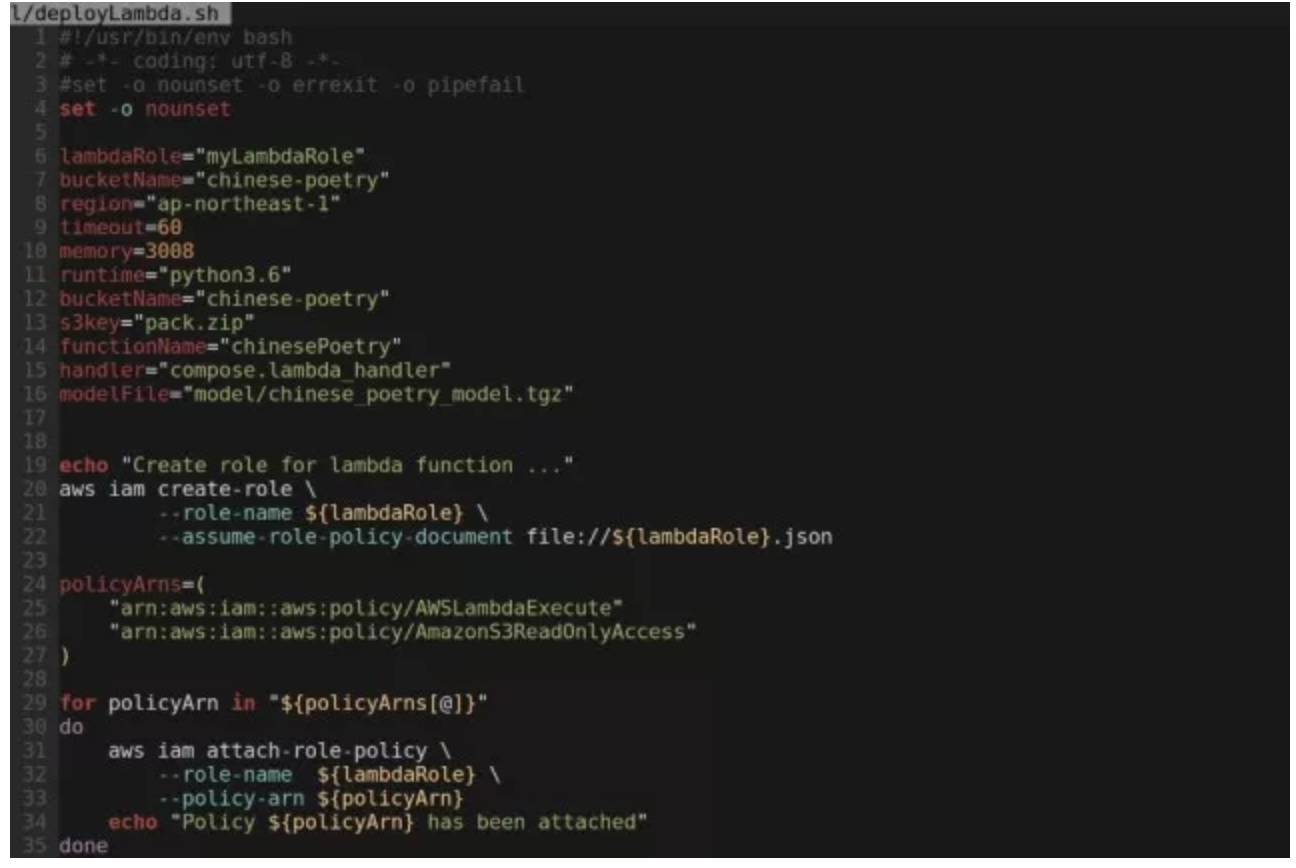
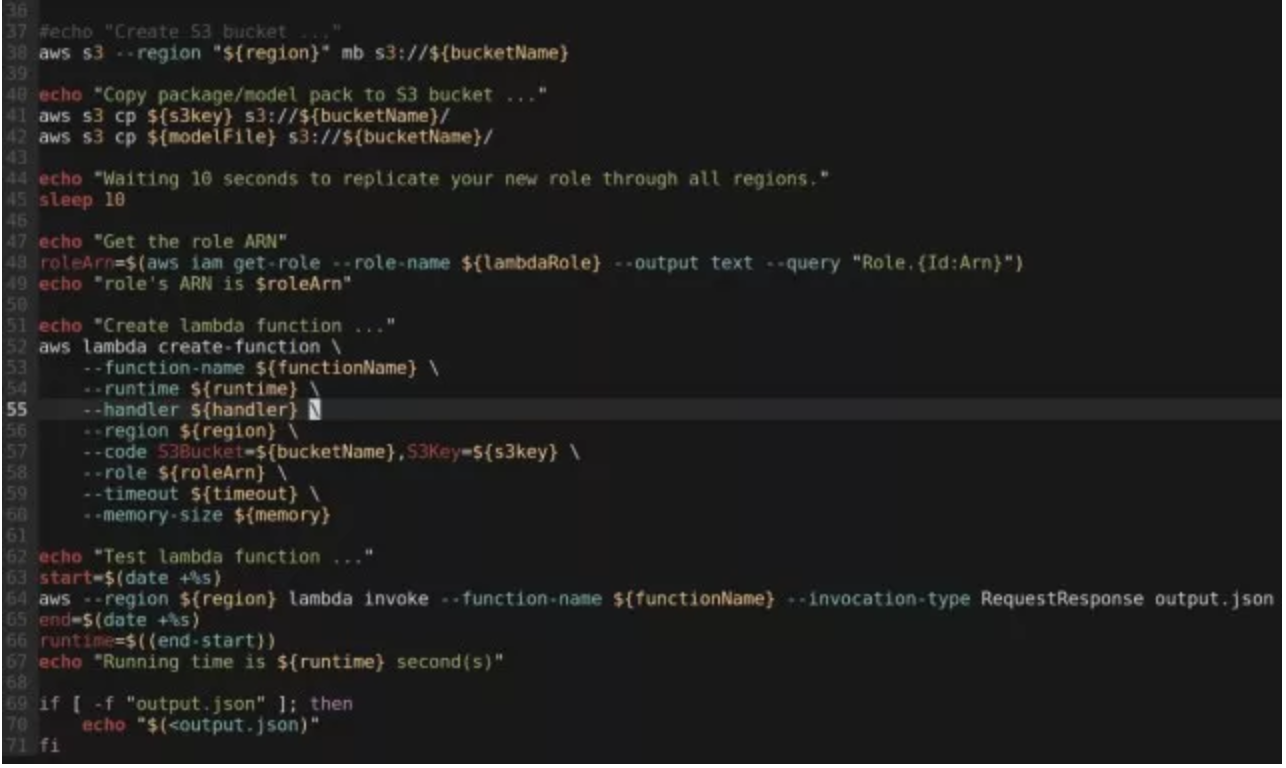
部署脚本的最后会利用 AWS CLI 来调用(invoke)这个函数已验证部署是否成功。不过,输出的结果看起来有点奇怪,不像是一首诗。这是因为 Lambda 函数的输出采用的是 JSON 的格式,而按照 RFC4627 的解释 JSON 格式对于 UNICODE 字符串进行了转义处理。
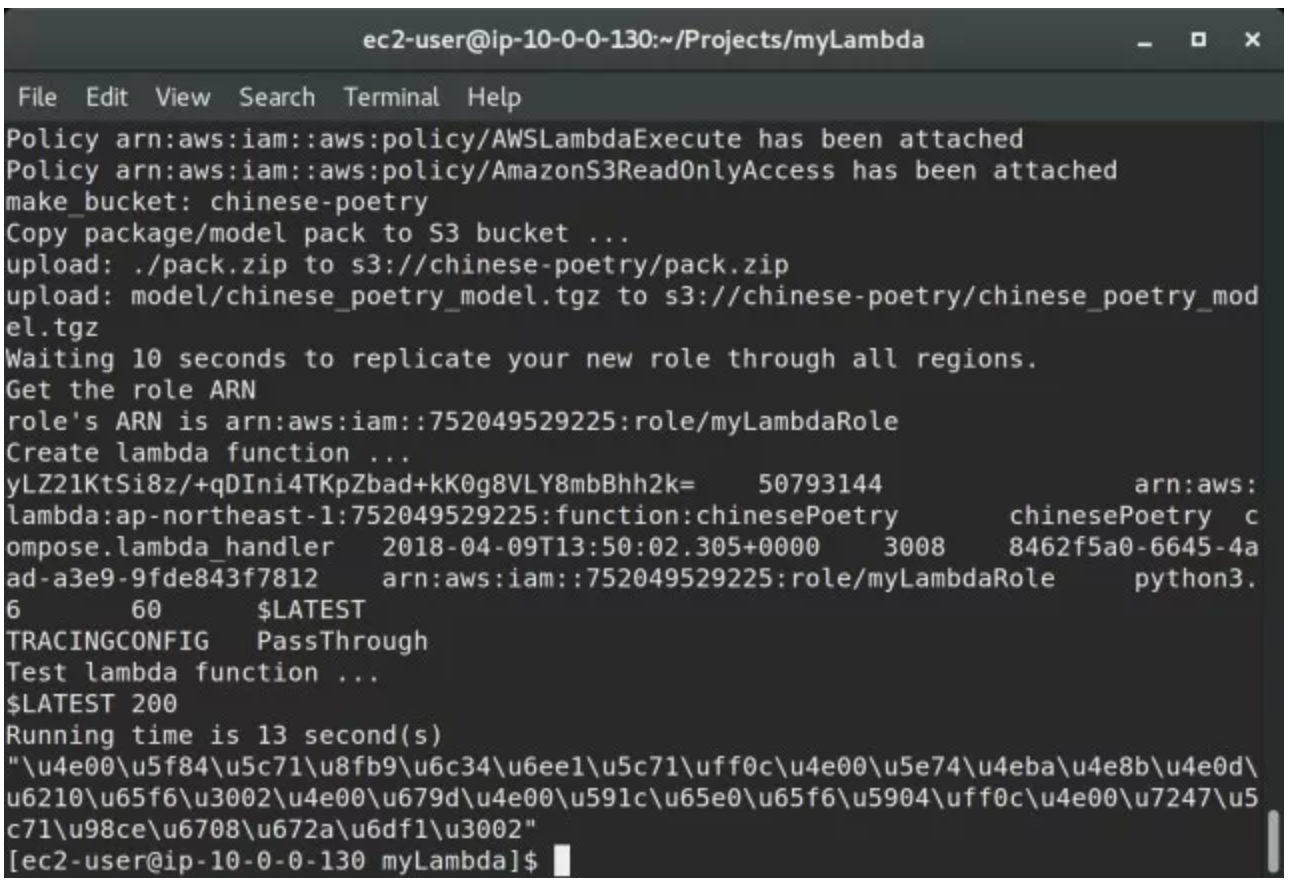
特别强调
为了确保我们打包的代码、库与 Python 环境和 Lambda 运行环境相匹配。建议打包的服务器环境与 Lambda 相一致。查看 Lambda 的文档我们可以了解到 Lambda 的运行环境为:
于是我们创建打包所需的 EC2 实例的时候,务必选择 Amazon Linux AMI 而不是其它。目前最新的 Amazon Linux AMI 的版本是 2017.09.1。在我的测试来看,这个版本应该最好的选择。一个很容易混淆的版本是:
Amazon Linux 2 LTS Candidate AMI 2017.12.0 (HVM), SSD Volume Type
这个版本与 Lambda 运行环境有比较大的差别 (例如其缺省的 Python3 的版本是 3.7,而 Lambda 上的 Python3 的版本是 3.6),不建议使用。
RESTfull API
部署完成以后,我们的函数就可以通过 AWS SDK 以及 AWS CLI 的方式来进行调用了。但对于调用者来说,这肯定不是一种最好的方式。这种更好的方式应该就是 RESTfull API 的封装方式。它提供了基于最常见的 HTTP/HTTPS 方式,以最简单的 GET/PUT/POST 等简单的 HTTP Verb 实现对 API 的请求调用。在 AWS 的产品家族中,Amazon API Gateway 就提供了这样的服务。接下来,我们还是要坚持自动化的原则通过一段脚本来实现 Lambda 函数的封装。
如果仅仅从文档的篇幅来看,你绝对不会认为 Amazon API Gateway 是一个复杂的产品。但是完成这个脚本确实让我大伤脑筋,因为这个服务的复杂程度远远超出了我的预期。可以想象一下,我们口中热议的 Web Services、RESTfull 乃至 Microservices,如果缺少一个强大的平台做支撑,就只能是空中楼阁、无本之木。而打造像 Lambda、API Gateway 这样一个强大的平台却绝非易事,这也就是云计算的价值所在吧。附上这一段让我备尝辛苦的脚本:
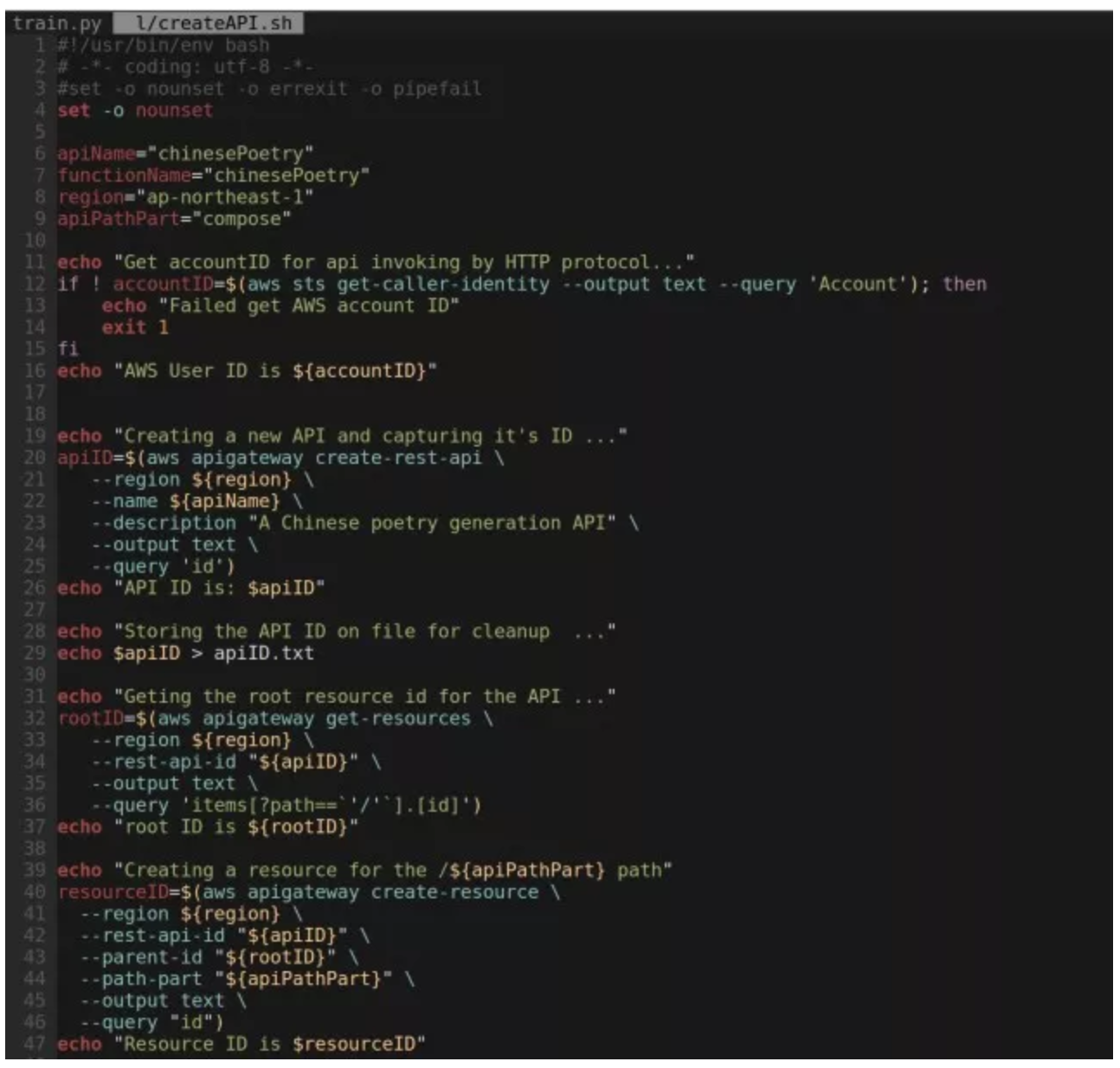
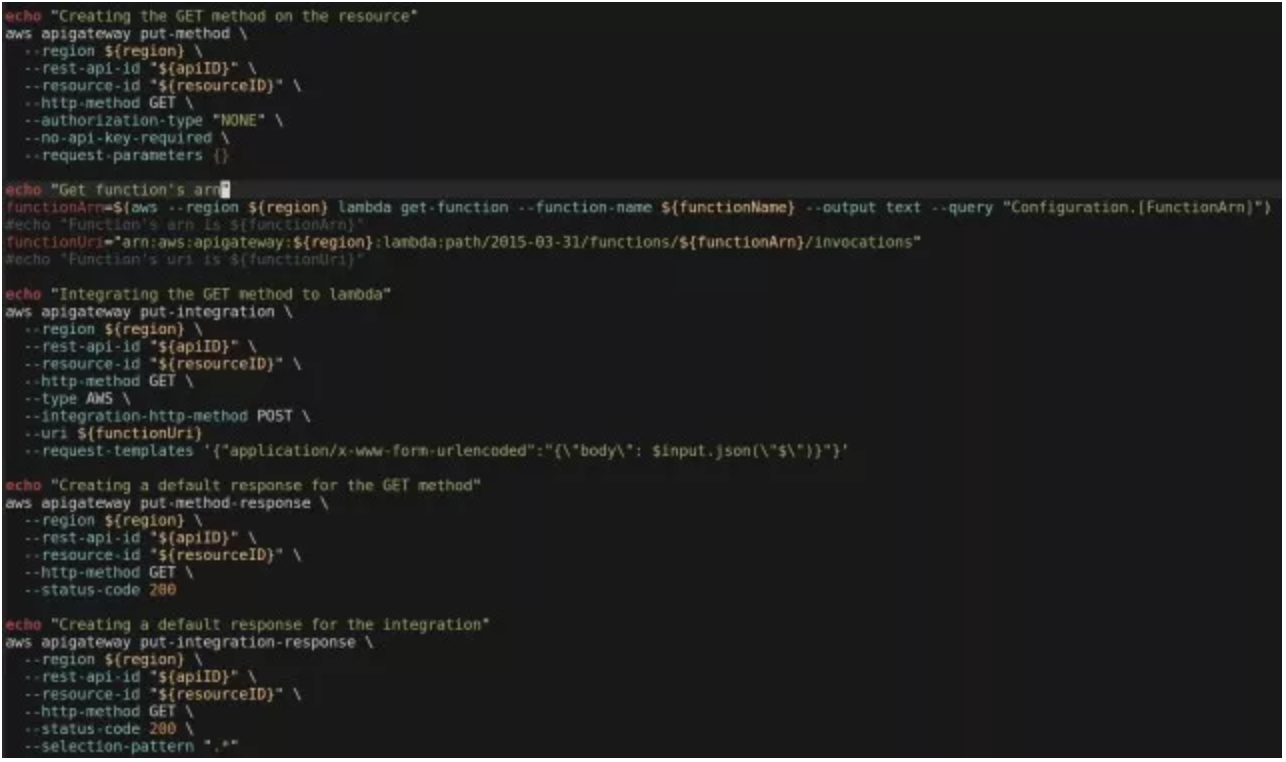
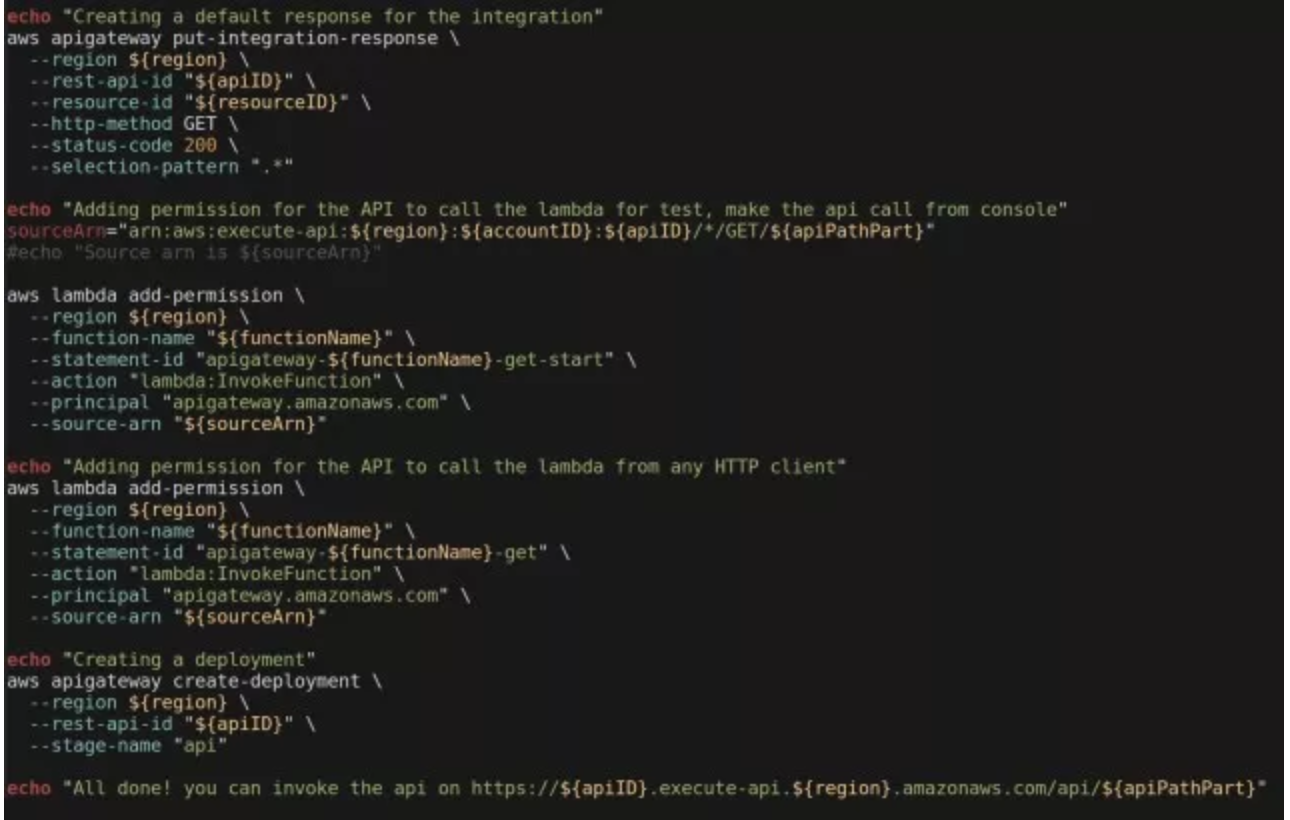
这个脚本执行之后,我们得到了一个 URL: https://p1umw2k6rf.execute-api.ap-northeast-1.amazonaws.com/api/compose
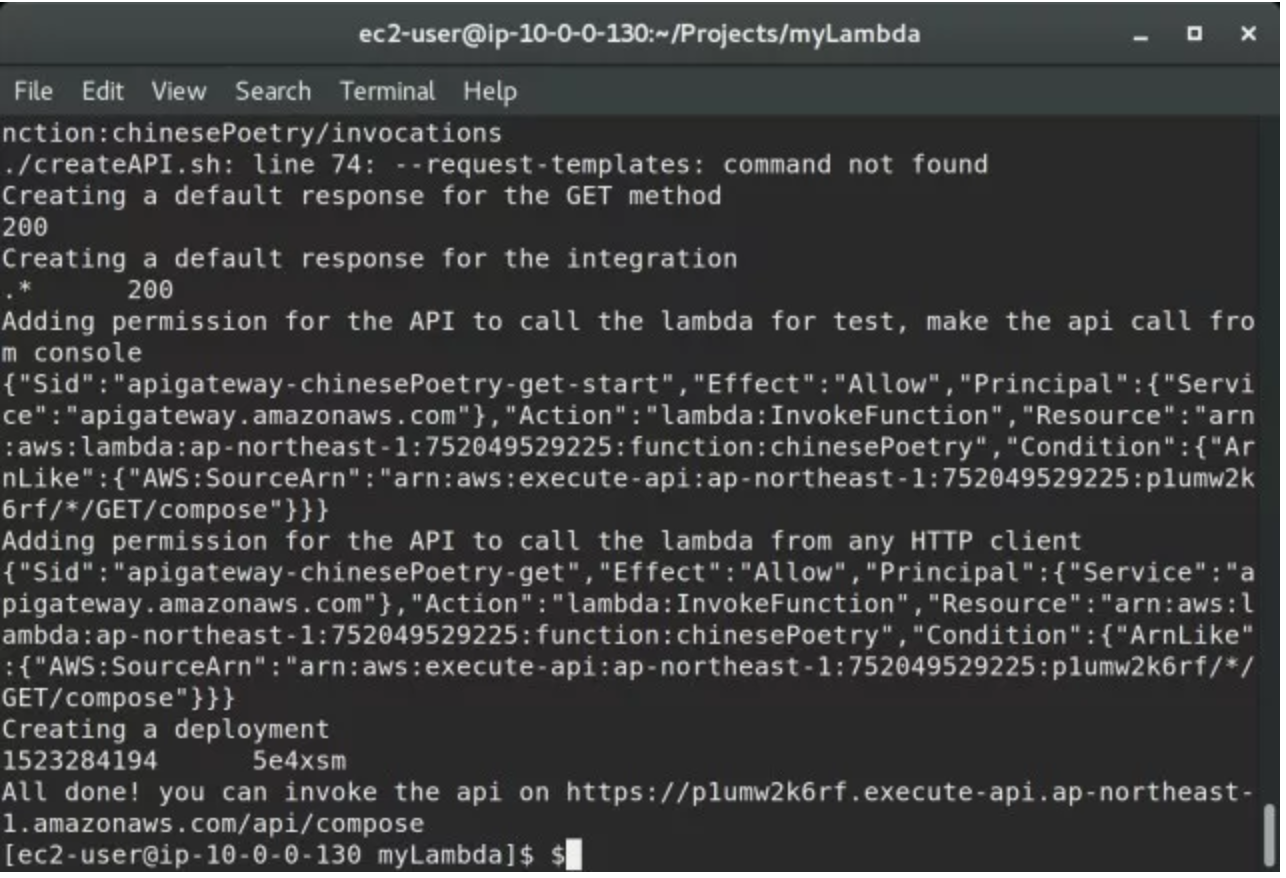
通过浏览器访问这个网址,等待 7~9 秒钟就可以看到一个 JSON 格式的内容。为了验证内容的有效,还可以执行这样的一行代码来验证 -
python3 -c "import requests;r= requests.get('https://p1umw2k6rf.execute
-api.ap-northeast-1.amazonaws.com/api/compose');print(r.json())"
执行的结果应该就是一首有模有样的古诗了。我不知道你运行的时候生成了什么样的诗,我看到的这样的一些句子:
一日山边客, 清风未得归。 一生何日见, 风月自相寻。
山山一日不堪寻,未觉清秋不可留。 未觉人情犹可见, 更怜山外有花声。
一片春深水未深, 不知风雨不知愁。 春来不得无多事, 不觉人情不自知。
不知人物有人情 ,不见江南一一声。不是春风无处去, 不知何处到江南。
一枝春日月, 不见月前春。 一片秋风好, 山风一月秋。
春风不得雨, 春月落梅花。 不见人家去, 谁知不见归。
山下无人见, 春来不可怜。 一时春日远, 风月自相寻。
一径秋风雨不开 ,不能知我自相亲。 一杯何处有诗事, 只有诗人不得知。
春风吹落雪, 不到水云明。 山上无时事, 人间一日寒。
一片无人不自知, 不须何处有诗人。 一杯一夜无如我, 只是人间老客人。
天上山中远, 江南日暮深。 山林无限处 ,风雨不堪来。
白云山上远, 风月月无人 。一径风流月, 风霜月下秋。 春深山上月 ,山影满云深。
一日春风月满山, 春风不是月边来。 一枝不见江南去, 不见春风月不斜。
不是江南路, 何须有一声。 不怜人在此, 一日不成春。
春风犹是此, 只是故园情。
一点一花风月落 ,一杯无处自归来。
一朝何所见, 一笑亦相思。
春风一片水, 风月不知情。
天地不可见,我来无处归。不为一年事,不识白头心。
一夜一年人已好,只怜人事自相知。
天上风流一径秋,山风吹月一枝开。不知一曲无时处,只有江山一片来。
一夜秋来晚, 秋风雨不收。 一花春未见, 风月一时来。
春雨寒风月, 秋寒月影开。 山林不相望, 风月自相归。
通常剧情到了高潮,宋晓峰老师总要说一句他的招牌口头禅:“此时此刻,我想吟诗一首….”。对我来说,这两天看到的诗已经足够多了。这些诗虽然说朗朗上口,只要此文对各位有所收益我就心满意足了。

