下载APP
登录
关闭
讲堂
算法训练营
Python 进阶训练营
企业服务
极客商城
客户端下载
兑换中心
渠道合作
推荐作者
第四章 网络(二)
2018-02-27 薛命灯

在上一章中,我们讨论了 rCluser 的网络问题,包括叠加网络的概念、如何使用 Open Contrail 实现叠加网络以及如何与 Docker 集成。在这一章中,我们将深入探讨其他话题:基础设施即代码、负载均衡和失效备援测试。
基础设施即代码
Open Contrail 为我们提供了一组用于配置网络的 API,帮助我们实现了应用程序网络的自动化。我们使用持续交付的方式来发布应用程序,也就是说,任何一个提交到主干分支的代码都有可能成为一个潜在的发布版本。为了支持持续交付,应用程序必须经过严格的自动化测试,我们还要提供一个自动化的构建和部署管道。部署过程必须是可重复的,在发生问题时可以进行回退。但问题是,应用程序的功能并非只有代码,还包括它们所运行的环境。
为了实现可重复的构建和部署,我们需要给应用程序和它的运行环境打上版本标签,并对它们进行审计(这样我们就知道谁对它们做了修改)。也就是说,我们不仅要对应用程序的代码进行版本控制,对应用程序运行环境的描述也需要被包含在版本控制当中。
我们构建了一个系统,用于描述应用程序的网络环境,我们使用了一个简单的 JSON 数据模型来描述网络,并称之为网络蓝图(network blueprint)。然后,我们创建了一个循环作业,从代码版本控制系统上拉取这些蓝图,把它们转换成 Contrail API 调用。开发人员使用这个数据模型来定义他们的网络需求,比如应用程序之前的交互方式。他们不需要关心 IP 地址或其他任何本该由网络工程师掌控的细节问题。
开发人员有自己的网络蓝图,要修改它们只需要发起一个拉取请求,修改完毕之后再合并到主干分支上。有了这种自助流程,修改网络配置不再成为瓶颈,因为我们不再依赖那一小撮网络工程师。现在唯一的瓶颈在于开发人员能够在多少时间内修改和提交 JSON 配置文件。
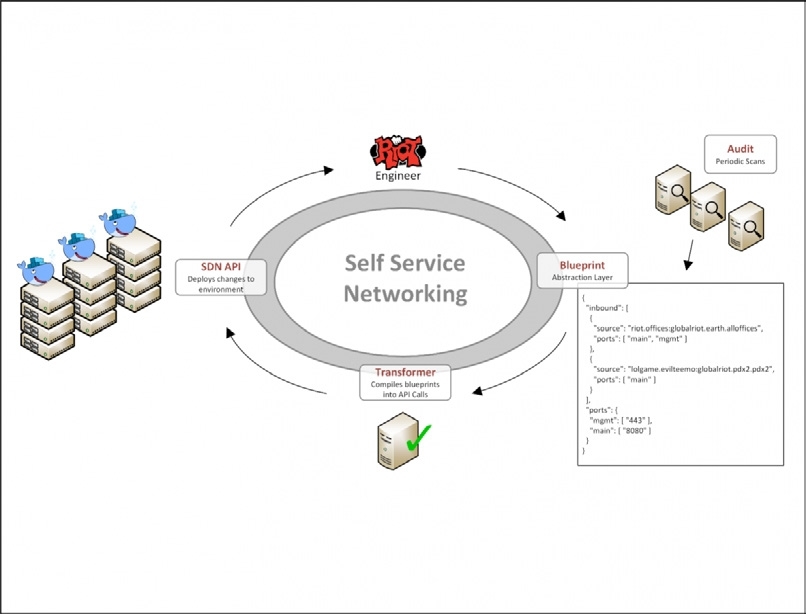
有了这个系统,我们就可以很快地开启必要的网络访问权限。对于 Riot 来说,玩家的安全是最重要的,我们要在基础设施中采取安全措施。我们的安全策略有两个原则,即最少权限原则和深层防御原则。
最少权限的意思是说,Riot 网络的任何一个访问者都只具备访问满足他们工作所必需资源的权限。访问者有可能是人,也可能是后端的服务。这个原则极大地降低了潜在的入侵可能带来的风险。
深度防御的意思是说,我们同时在基础设施的多个地方部署了安全防控措施。就算攻击者突破了一个安全点,后面还有更多的安全点等着他们。例如,公共 Web 服务器对支付系统的访问受到了严格限制,而支付系统也有自己的防御手段,比如使用了 Layer 7 防火墙和入侵检测系统。
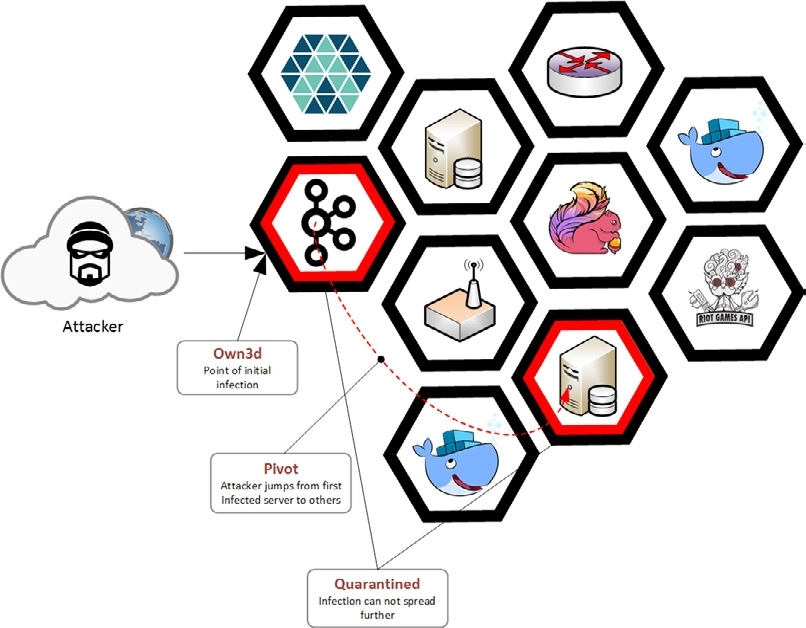
Contrail 通过 v Router 给每一台主机设置了一个安全点。基于基础设施即代码的 JSON 描述,我们就有了最新的网路安全策略。我们还开发了用于扫描网络规则的工具。速度、强壮的安全实践、审计能力——这些组合在一起形成了一个健壮的安全系统,它不仅不会给开发人员带来麻烦,反而让他们能够更快更方便地完成他们的工作。
负载均衡
为了满足应用程序不断增长的需求,我们基于 DNS、Equal Cost Multi-Pathing(ECMP)和传统的基于 TCP 的负载均衡器(HAProxy 或 NGINX)构建了一套功能丰富的高可用负载均衡解决方案。我们通过 DNS 在全球的多个 IP 地址上分发流量。玩家可以使用类似“riotplzmoarkatskins.riotgames.com”这样的域名,我们的服务器会返回多个 IP 地址。有一半玩家可能会收到一个地址列表,列表的第一个地址是服务器 A,另一半玩家则收到另一个地址列表,其中第一个地址是服务器 B。如果服务器 A 或服务器 B 发生宕机,客户端会尝试连接到另一台服务器上,因此玩家不会感觉到出现了服务中断。
我们的内部网络中有多台服务器被配置成可以对服务器 A 的 IP 地址做出应答。在网络看来,这些服务器都是可用的目标服务器。在收到一个新的玩家连接后,我们使用散列函数来计算该请求应该被转发给哪一台服务器。散列函数使用了 IP 地址和 TCP 端口。为了将服务器发生宕机的影响降到最低,我们使用了一致性散列,这样可以确保只有使用了那台宕机服务器的玩家会受到影响。在大多数时候,客户端会自动重新发起一个新的连接,玩家甚至都感觉不到服务中断。在收到新的连接后,因为宕机的服务器已经被移除,我们不会再尝试把请求转发给这台服务器。我们的大部分系统会自动启动一个新的实例,然后把它加到一致性散列环中。负载均衡的最后一层是使用传统的基于 TCP 或 HTTP 的负载均衡器,如 HAProxy 或 NGINX。
来自 ECMP 层的请求会达到负载均衡器实例上。这些实例监测后端的 Web 服务器,确保它们都是活跃的,并能够在一定时间内返回响应,时刻准备接收新的请求。如果这些条件都满足,服务器就会收到请求,并将响应结果逐层返回给玩家。我们在这一层进行蓝绿部署和智能健康监测,比如检查“/index.html 是否返回 200 响应码”。除此之外,我们还可以进行 canary 部署,先让 10 台服务器中的一台部署最新的应用,剩下 9 台仍然运行旧
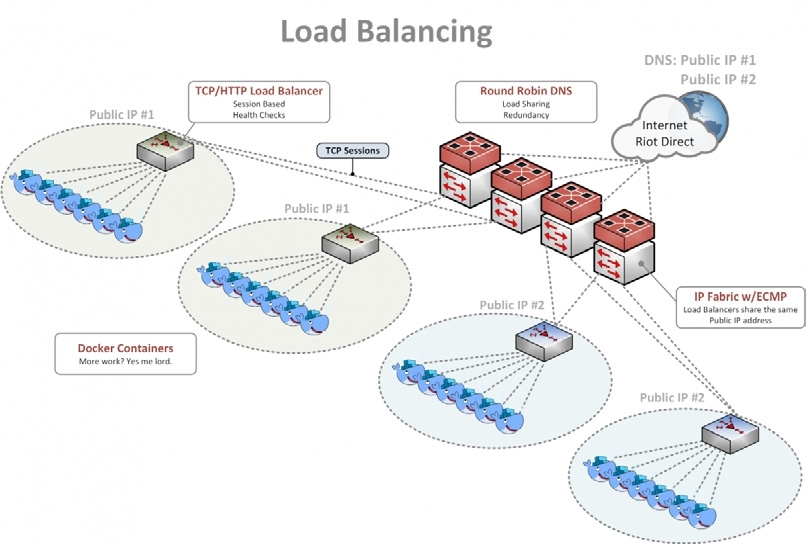
版应用。我们对新应用进行严密监控,如果一切顺利,那么就再拿出两台服务器部署新版应用,并以此类推。如果中间出现了问题,我们就回退到上一个稳定版本,并修复问题。这样,我们就可以持续地改进我们的服务,同时又能将风险降到最低。
有了这些层(DNS、ECMP、TCP 或 Layer 7 负载均衡),我们为开发者和玩家提供了一个功能丰富、稳定且可伸缩的解决方案。
失效备援测试
高可用系统最重要的能力是在系统发生故障时能够进行自动恢复。在我们刚开始构建数据中心时,我们通过让工程师拔掉线缆或随机重启服务器的方式来模拟故障。但在数据中心建好并投入使用后,这样做其实很难。我们被要求在做好某些事情之后就永远不要再去动它们。我们确实基于这个流程发现了一些问题,也避免了一些中断,但它仍然有需要改进的地方。
于是我们按照数据中心的比例搭建了一个 staging 环境,该环境的规模要足够精确,避免造成不必要的浪费。我们使用了两个机架,每个机架上有 5 台服务器。生产环境的机器比 staging 要多得多,不过 staging 环境足够我们进行测试了。
在将变更发布到生产环境之前,我们先在 staging 环境对它们进行测试。我们对每一个变更进行快速的基础测试,以便发现潜在的 bug。这样我们就不用再担心我们的自动化系统会变脆弱,也不用担心太多的变更会让我们不堪重负。我们要在进入生产环境之前,把 bug 扼杀在 staging 环境里。
除了基础测试,我们也进行更为复杂的破坏性测试,我们停掉一些重要的组件,强制让系统在受损的状态下运行。在只剩下 3 到 4 个子系统可以运行的时候,我们就知道我们可以承受多大程度的损失,并在不影响玩家的情况下修复系统。
这一整套测试比基础测试更加耗时、更加具有破坏性,也更加复杂,所以我们要减少运行整套测试的频次。我们让链接失效、重启机器、重启机架、禁用 SDN 控制器,只要我们能想到的,我们就去做。然后我们统计系统多久可以恢复,并确保一切运行顺畅。如果出现了偏差,我们就查看从上一次运行到现在究竟做出了哪些代码变更,在这些变更进入生产环境之前把它们都找出来。如果我们在生产环境中遇到了之前没有测试到的问题,我们就把它加到测试用例中,确保同样的问题不会再次发生。我们的目标是尽早发现问题,问题越早被发现,就可以越快修复它们。为此,我们不仅能够走得更快,而且可以走得更自信。
在这一章中,我们介绍了我们是如何实现基础设施即代码、负载均衡和失效备援测试的。“唯一不变的就是变化”这句话很好地概括了我们的处境。基础设施是有生命的,它一直在成长和演化。在它成长的时候,我们要为它提供资源,在它生病的时候我们照顾好它,我们要在全球范围内以尽可能快的速度做好这些。我们要认真面对这样的现实,我们的工具、流程需要跟上不断变化的环境。
写留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。